Relationale Datenbanken - Entwurf und Prinzipien (Version Oktober 2025)
| |
Copyright 2025 Josef L. Staud |
|
Autor: Josef L. Staud |
|
Stand: Oktober 2025 |
|
Umfang des gedruckten Textes: ca. 60 Seiten |
|
Zum Text |
|
Diese Text entstand im Oktober 2025. Er ist auch in englischer Sprache veröffentlicht (https://www.staud.info/rmkEoF/re_t_1.php). Beide Texte sind auf diesen Webseiten zu finden. |
|
Prof. Dr. Josef L. Staud |
|
Aufbereitung für's Web |
|
Diese HTML-Seiten wurden mithilfe eines von mir erstellten Programms erzeugt: WebGenerator (Version 2021-1). Es setzt Texte in HTML-Seiten um und wird ständig weiterentwickelt. Die "maschinelle" Erstellung erlaubt es, nach jeder Änderung des Textes diesen unmittelbar neu in HTML-Seiten umzusetzen. Dies erfolgt inzwischen in zwei Versionen: mit und ohne Frames. Derzeit werden bei den meisten Texten beide Versionen parallell angeboten. |
|
Da es nicht möglich ist, nach jeder Neuerstellung alle Seiten zu prüfen, ist es durchaus möglich, dass irgendwo auf einer "abgelegenen" Seite Fehler auftreten. Ich bitte dafür um Verzeihung und um Hinweise (hs@staud.info). |
|
Urheberrecht |
|
Dieser Text ist urheberrechtlich geschützt. Die dadurch begründeten Rechte, insbesondere die der Übersetzung, des Nachdrucks, des Vortrags, der Entnahme von Abbildungen und Tabellen oder der Vervielfältigung auf anderen Wegen und der Speicherung in Datenverarbeitungsanlagen, bleiben, auch bei nur auszugsweiser Verwertung, vorbehalten. Eine Vervielfältigung dieses Textes oder von Teilen dieses Textes ist auch im Einzelfall nur in den Grenzen der gesetzlichen Bestimmungen des Urheberrechtsgesetzes der Bundesrepublik Deutschland vom 9. September 1965 in der jeweils geltenden Fassung zulässig. Sie ist grundsätzlich vergütungspflichtig. Zuwiderhandlungen unterliegen den Strafbestimmungen des Urheberrechtsgesetzes. |
|
Warenzeichen und Markenschutz |
|
Alle in diesem Text genannten Gebrauchsnamen, Handelsnamen, Marken, Produktnamen, usw. unterliegen warenzeichen-, marken- oder patentrechtlichem Schutz bzw. sind Warenzeichen oder eingetragene Warenzeichen der jeweiligen Inhaber. Die Wiedergabe solcher Namen und Bezeichnungen in diesem Text berechtigt auch ohne besondere Kennzeichnung nicht zu der Annahme, dass solche Namen im Sinne der Gesetzgebung zu Warenzeichen und Markenschutz als frei zu betrachten wären und daher von jedermann benutzt werden dürften. |
|
Prof. Dr. Josef L. Staud |
|
|
|
Vorwort
| |
Während dieser Text die wichtigsten Punkte des Entwicklungswegs hin zu Relationalen Datenbanken erläutert, enthält das folgende Buch eine umfassende Darstellung der relationalen Theorie: |
|
Staud, Josef Ludwig: Relationale Datenbanken. Grundlagen, Modellierung, Speicherung, Alternativen (2. Auflage). Hamburg 2021 (tredition) |
|
Zum Kaufen: https://shop.tredition.com/booktitle/Relationale_Datenbanken/W-1_161508 |
|
Auszüge daraus finden sich auf https://www.staud.info/rm2/rm_t_1.php |
|
Sozusagen ein Begleitwerk stellt die folgende Aufgabensammlung dar: |
|
DBTraining - Datenbanktraining zu RM, ERM, SQL und OOM. 128 einführende Aufgaben und Lösungen. |
|
Dieses findet sich hier: https://www.staud.info/AufgabenDBoF/db_t_1.php |
|
Es enthält Aufgaben und Lösungen zum Training folgender Aspekte rund um Datenbanken: |
|
- Modellierung relationaler Datenbanken
- Einrichten relationaler Datenbanken mit XAMPP/mySQL
- Abfragen und Arbeiten von Datenbanken mit SQL
- Web-Oberfläche einrichten mit PHP
- Entity Relationship - Modellierung
- Objektorientierte Modellierung nach der UML 2.5
|
|
Auch mit einigen beispielhaften Lösungen durch ChatGPT, um zu sehen, wie weit die aktuelle KI bei der Lösung von Aufgaben aus diesem Umfeld schon gekommen ist. |
|
Hinweise zur Textgestaltung |
|
Was die zu beschreibenden Elemente in der Datenmodellierung angeht, kann man einen Ausgangspunkt und drei Modellebenen unterscheiden. Der Ausgangspunkt ist der zu modellierende Anwendungsbereich, manchmal auch Weltausschnitt genannt. Die erste Modellebene ist die der Attribute, durch die Objekte und Beziehungen beschrieben werden. Die zweite die Ebene der "kleinsten" Elemente im jeweiligen Ansatz, dies sind hier die Relationen. Die dritte Ebene ist die des gesamten Datenmodells. Um diesbezüglich im Text die Übersichtlichkeit zu erhöhen wird folgende typographische Festlegung getroffen: |
|
- Bezeichnungen von Anwendungsbereichen werden etwas vergrößert, in Kapitälchent und in Arial gesetzt: Hochschule, Personalwesen, WebShop.
- Bezeichnungen von Datenmodellen und Datenbanken sind in normaler Größe und in Arial gesetzt: Vertrieb, Zoo, WebShop, Datenbanksysteme (Markt für Datenbanksysteme).
- Bezeichnungen von Relationen sind etwas verkleinert und in Arial gesetzt: Angestellte, Abteilungen, Projekte.
- Bezeichnungen von Attributen sind etwas verkleinert, fett und in Arial gesetzt: Gehalt, Name, Datum. Bei zusammengesetzten Benennungen wird der nachfolgende Begriff wieder groß begonnen: PersNr (Personalnummer), BezProj (Bezeichnung Projekt).
- Ausprägungen von Attributen werden in normaler Größe und in Courier gesetzt, z.B. Müller für das Attribut Name.
|
|
Für die Relationen (Tabellen für relationale Datenbanken) wird bei der Bezeichnung immer die Mehrzahl gewählt, da ja in der Regel mehrere Objekte bzw. Beziehungen erfasst sind. |
|
Web-Version und Druck-Version |
|
Es gibt von diesem Text eine Version für's Web (Web-Version) und eine, die gedruckt wird (Druck-Version). Beide unterscheiden sich nur in der formalen Gestaltung. Die Druck-Version hat z.B. zu Beginn ein Inhaltsverzeichnis und am Textende einen Index. |
|
|
|
|
|
Abkürzungsverzeichnis |
|
|
|
| Abkürzung |
Begriff |
Anmerkungen |
| 1NF |
Erste Normalform |
Relation ohne Wiederholungsgruppen, nur atomare Werte. |
| 2NF |
Zweite Normalform |
Keine partiellen Abhängigkeiten von Teilen eines Schlüssels. |
| 3NF |
Dritte Normalform |
Keine transitiven Abhängigkeiten von Nichtschlüsselattributen. |
| BCNF |
Boyce-Codd-Normalform |
Strenger als 3NF: Jeder Determinant muss ein Kandidatenschlüssel sein. |
| 4NF |
Vierte Normalform |
Keine nichttrivialen mehrwertigen Abhängigkeiten außer von Kandidatenschlüsseln. |
| 5NF |
Fünfte Normalform |
Zerlegung so, dass keine Join-Abhängigkeiten mehr bestehen. |
| FD |
Funktionale Abhängigkeit |
Beziehung zwischen Attributen. |
| SA |
Schlüsselattribut |
Attribut, das Teil eines Schlüssels ist. |
| NSA |
Nichtschlüsselattribut |
Attribut, das nicht Teil eines Schlüssels ist. |
| PS |
Primärschlüssel |
Eindeutiger Schlüssel einer Relation. |
| FS |
Fremdschlüssel |
Schlüssel, der auf eine andere Relation verweist. |
| |
|
|
|
|
1 Überblick, Um was geht es? |
|
|
|
1.1 Meilensteine des Datenbankdesigns |
|
Die folgende Abbildung zeigt den Gesamtweg beim Datenbankdesign, vom Anwendungsbereich bis zur Datenbank. |
|
. 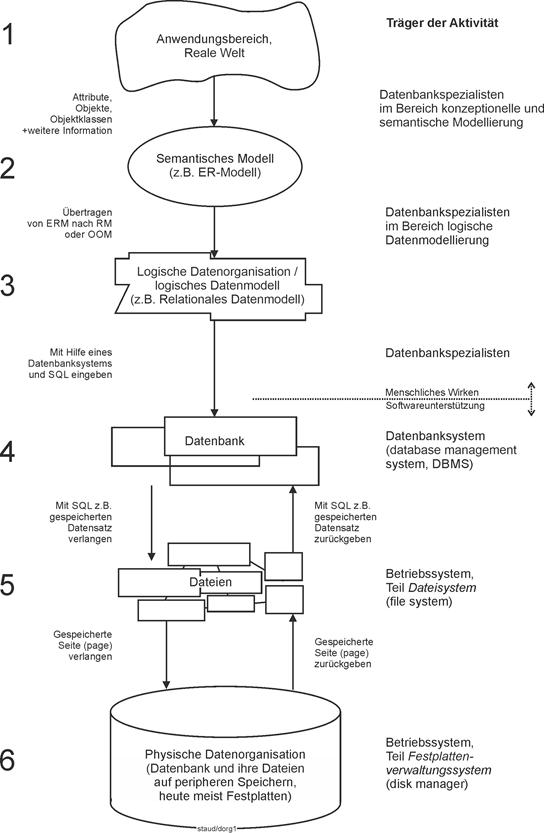 |
|
Abbildung 1.1-1: Aufbau von Relationen. |
|
Das folgende Buch deckt die meisten dieser Themen ab: |
|
Staud, Josef Ludwig: Relationale Datenbanken. Grundlagen, Modellierung, Speicherung, Alternativen (2. Auflage). Hamburg 2021 (tredition) |
|
1.2 Inhalte |
|
Dieser Text ist eine Zusammenfassung aus obigem Buch. Sie deckt - kurz und knapp - die wichtigsten der in der Abbildung genannten Themen ab: |
|
- In Kapitel 3 geht es um Relationen, die Datentabellen mit einem spezifischen Aufbau, die von zentraler Bedeutung sind.
- Kapitel 5 zeigt wie Beziehungen in der relationalen Datenmodellierung realisiert werden.
- Kapitel 6 zeigt, wie mit der relationalen Theorie das Datenmodell optimiert wird. Das Werkzeug dafür sind sechs Normalformen. Der Schwerpunkt liegt dabei, wegen ihrer großen praktischen Bedeutung, auf den ersten drei Normalformen: 1NF, 2NF, BCNF.
- Die Kapitel 7 bis 11 zeigen, wie zentrale semantische Muster in relationalen Datenmodellen umgesetzt werden: "Semantik sucht Syntax". Das reicht von der Bewältigung von Einzel- und Typinformation über Generalisierung / Spezialisierung, Aggregation, Komposition bis zu Eigenschaften von Beziehungen.
- In Kapitel 12 sind die Regeln für die Erstellung relationaler Datenmodelle zusammengestellt.
- Die Kapitel 12 bis 14 zeigen an einem Beispiel ("Rechnungen") die Erstellung einer Datenbank mit SQL.
|
|
1.3 Zielgruppe |
|
Dieser Text richtet sich an Einsteigerinnen und Einsteiger in das Gebiet des Datenbankdesigns. Er eignet sich insbesondere für Studierende an Hochschulen und Fachhochschulen, Lernende an Berufsschulen oder in Weiterbildungsprogrammen sowie für Berufstätige, die im Rahmen von Schulungen oder Zertifizierungslehrgängen Kenntnisse im Bereich Datenbanken erwerben möchten. |
|
Das Material bietet eine kompakte Einführung in die grundlegenden Konzepte des Datenbankdesigns und unterstützt sowohl das akademische Lernen als auch die praktische Anwendung in Projekten und im Berufsalltag. |
|
2 Anwendungsbereiche |
|
Am Anfang der Entwicklung einer Datenbank ist die Klärung des Anwendungsbereichs zu leisten. Welche Daten sollen in der Datenbank erfasst werden, welche Auswertungen sollen mit den Daten möglich sein, welche Geschäftsprozesse sollen unterstützt werden. In der Datenbanktheorie wird dies Konzeptionelle Modellierung (conceptul modeling) genannt. Hier dazu nur das allerwichtigste, für eine ausführliche Darstellung vgl. https://www.staud.info/rm2/rm_t_1.php#Kapitel4 und die dort angegebene Literatur. |
|
Der Ausschnitt der realen oder auch fiktiven Welt, der in der Datenbank erfasst werden soll, wird aso Anwendungsbereich genannt. Die doch sehr schlichte Datenbanksicht auf Anwendungsbereiche nimmt erstmal nur Objekte mit ihren Attributen (Angestellte eines Unternehmens; Abteilungen eines Unternehmens) und Beziehungen zwischen den Objekten (Angestellte arbeiten in Abteilungen) wahr. |
|
Auch andere Begriffe sind oder waren hier üblich, z.B. Weltausschnitt (von slice of reality), universe of discourse, subject area. |
|
Objekte |
|
Mit Objekten sind hier Objekte im umgangssprachlichen Sinn gemeint. Also alles, was wir wahrnehmen und dem wir Eigenschaften zuweisen. Von den Eigenschaften werden die betrachtet, die Attribute sind (Angestellte haben einen Namen, Vornamen, ein bestimmtes Alter, usw.). Vgl. unten. |
|
In der objektorientierten Theorie werden die Konzepte Objekte und Objektklassen (vgl. unten) ebenfalls verwendet. Auch dort sind sie Träger von Attributen, zusätzlich aber auch von Methoden und vielem mehr. Sie sind dort der Ausgangspunkt der theoretischen Ausführungen. Vgl. https://www.staud.info/leitOO.php für eine einführende Darstellung. |
|
Will man einen kleinen theoretischen Dreh mit rein bringen, könnte man Objekte definieren als Elemente unserer Wahrnehmung, denen wir beschreibende Attribute und mindestens ein identifizierendes Attribut zuweisen können, also, einfach formuliert: |
|
Objekte sind alle wargenommenen Phänomene, die durch Attribute identifiziert und beschrieben werden kann. |
|
Attribute |
|
Attribute beschreiben also die Eigenschaften von Objekten. Für die Angestellten eines Unternehmens z.B. |
|
- Personalnummer (PersNr)
- Name
- Vorname (VNname)
- Datum der Einstellung (DatEinst)
- Geburtstag (GebTag)
|
|
Wie sind diese Attribute strukturiert? Sie besitzen eine Bezeichnung, verschiedene Attributsausprägungen und Objekte oder Beziehungen, die sie beschreiben. Betrachten wir einige Beispiele: |
|
- Widmer, Maier, usw. als Namen von Angestellten in einem Unternehmen
- Schwarz, weiß, grau, rot, ... als Farben von Autos
- Männlich, weiblich als Geschlecht von Katzen
- 126 als Messwert des Blutzuckers bei Diabetikern
- 5, 10, 20, 50, ... als Dauer von Ehen in Jahren
- 450,00 Euro als Preis eines Datenbanksystems bei einem bestimmten Händler
- 5000,00 Euro oder ein anderer positiver Betrag als Gehalt von Menschen
- 10050, 10051, ... als Personalnummer von Angestellten
- 1,7 oder eine andere Zahl zwischen 1 und 5 als Note von Hochschulklausuren
|
|
Alle unterstrichenen Wörter sind Beispiele für Attributsbezeichnungen. Alle kursiv gesetzten Wörter und Zahlen sind Beispiele für Attributsausprägungen, d.h. von Werten, die ein Attribut annehmen kann. Die Zahl vonAusprägungen muss mindestens 2 sein (zum Beispiel bei Geschlecht), sie kann einige umfassen (Farbe von Autos) oder viele (Namen, Messwerte). |
|
Attribute können bestimmte Werte annehmen, diese werden Attributsausprägungen genannt. |
|
Alle fett gesetzten Wörter bezeichnen Objekte und Beziehungen (im allgemeinsten Sinn) und nach einigen Modellierungsschritten Relationen. Diese werden durch die Attribute und ihre Ausprägungen beschrieben. Objekte bzw. Beziehungen müssen angegeben werden, da sonst nicht klar ist, worauf sich die Attribute beziehen. Dieser Zusammenhang zwischen Attributsbezeichnungen, -ausprägungen und Objekten / Beziehungen ist grundlegend und wie folgt: |
|
- Attribute haben eine bestimmte Menge von Attributsausprägungen.
- Objekten / Beziehungen werden Attribute zugeordnet.
- Ein Objekt hat für jedes Attribut eine gültige Attributausprägung, manchmal auch mehrere.
|
|
Vgl. für eine umfangreichere Darstellung https://www.staud.info/rm2/rm_t_1.php#Abschnitt3.4. |
|
Objektklasse |
|
Gleich aufgebaute Objekte, hier also Objekte mit denselben Attributen, also demselben Schlüssel und denselben beschreibenden Attributen werden zu Objektklassen zusammengefasst. Obige Attribute könnten dann eine Objektklasse Angestellte beschreiben. Ein einzelnes Objekt wäre dann z.B. Andrea Maier, geboren am 10.10. 2001, eingestellt am 20.12. 2022 mit der Personalnummer 1008. |
|
Anwendungsbereich erfassen und abgrenzen |
|
Will man also für die zu erstellende Datenbank den Anwendungsbereich erfassen und abgrenzen, muss man die darin vorkommenden Objektklassen mit ihren Attributen und die Beziehungen zwischen diesen identifizieren. |
|
Wie grenzt man Objektklassen voneinander ab. Hier hilft die Regel: Alle Objekte, die durch einen Schlüssel identifiziert und durch weitere Attribute beschrieben werden, gehören zusammen, stellen eine Objektklassedar. |
|
Hat man z.B. zu Angestellten folgende Attribute erhoben ... |
|
- Personalnummer (PersNr)
- Name
- Vorname (VNname)
- Datum der Einstellung (DatEinst)
- Geburtstag (GebTag)
- Bezeichnung der Abteilung (AbtBez), in der er oder sie arbeitet
- Leiter der Abteilung (AbtLeiter)
- Standort der Abteilung
|
|
... muss man erkennen, dass hier zwei Objektklassen vorliegen: |
|
- Die Objekte von Angestellte werden durch die PersNr identifiziert und durch Name, VName, DatEinst, GebTag und AbtBez beschrieben.
- Die Objekte Abteilungen erhalten den Schlüssel AbtBez und die beschreibenden Attribute AbtLeiter und Standort.
- Der Zusammenhang zwischen Angestellte und Abteilungen wird durch ein Attribut AbtBez bei den Angestellten festgehalten. Wir werden ein solches Attribut später Fremdschlüssel nennen.
|
|
Beziehungen |
|
Beziehungen sind hier wie folgt definiert: |
|
- Sie bestehen zwischen Objektklassen bzw. Objekten. Z.B., wenn es die Objektklassen Angestellte und Abteilungen gibt, dann gibt es die Beziehung Angestellte/r arbeitet in Abteilung.
- Sie beruhen auf Attributen, im obigen Beispiel wird dann z.B. die Personalnummer (1008) mit der Abteilungsbezeichnung (PW; Personalwesen) in Verbindung gestzt.
|
|
Für eine umfangreiche Darstellung vgl. https://www.staud.info/rm2/rm_t_1.php#Kapitel6. Für eine grundsätzliche Darstellung der Beziehungen in allen Modellierungsansätzen vgl. https://www.staud.info/Beziehungen/bz_t_1.php |
|
Genauso wie für Objekte werden auch für Beziehungen Klassen gebildet. Hier ist es aber meist so, dass mehr als ein Attribut für die Identifikation einer jeden Beziehung benötigt wird. |
|
|
|
3 Relationen |
|
|
|
3.1 Von Klassen zu Relationen |
|
Im nächsten Schritt wird nun jede der gefundenen Objekt- und Beziehungsklassen in einer Tabelle erfasst. Dies geschieht wie folgt: |
|
- die Attributsbezeichnungen stehen im Kopf der Spalten
- darunter folgen Zeile für Zeile die Attributsausprägungen, die ein Objekt bzw. eine Beziehung beschreiben, geordnet nach der Attributsanordnung in der Kopfzeile. Diese Zeilen werden in der relationalen Theorie Tupel genannt.
|
|
Betrachten wir das obige Beispiel der Objektklasse Angestellte. Die Tabelle kann (in einfacher und abstrahierter Form) so aussehen, wie unten angegeben. Eines der Attribute muss identifizierenden Charakter haben, hier ist es die Personalnummer. Es wird Schlüssel (der Relation) genannt und durch eine Raute gekennzeichnet (mehr dazu weiter unten). Für die Objektklasse Angestellte entsteht also eine Tabelle wie die folgende: |
|
Tabelle Angestellte |
|
| #PersNr |
Name |
VName |
DatEinst |
GebTag |
| 1001 |
Müller |
Karolin |
1.3.2010 |
14.5.1985 |
| 1010 |
Jäger |
Rolf |
1.10.1990 |
21.9.1959 |
| 1020 |
Wilkens |
Jenny |
1.1.2007 |
23.3.1970 |
| 1030 |
Forster |
Charles |
1.10.2010 |
31.7.1985 |
| 1005 |
May |
Lisa |
1.7.2009 |
21.9.1970 |
| 1040 |
Winter |
Angelika |
1.2.2007 |
17.9.1965 |
| 1007 |
Miller |
Igor |
1.5.2008 |
22.11.1962 |
| 1090 |
Stepper |
Rolf |
1.7.2013 |
15.4.1974 |
| |
Zur Schlüsselkennzeichnung: Ich nutze hier für die Kennzeichnung des Schlüssels einer Relation die Raute (#) und nicht die Unterstreichung, wie in der US-amerikanischen Literatur, weil die Unterstreichung in der relationalen Datenbanktheorie für Fremdschlüssel reserviert ist. Im übrigen erfolgt die Kennzeichnung des Schlüssels in der ER-Modellierung durch Unterstreichung. Somit hilft diese Festlegung, Missverständnisse zu vermeiden. |
|
Betrachten wir noch ein zweites Beispiel, die Objektklasse Abteilungen mit den Attributen: |
|
- Bezeichnung der Abteilung (AbtBez)
- Leiter der Abteilung (AbtLeiter)
- Standort der Abteilung
|
|
Hier ergibt sich folgende Tabelle |
|
Tabelle Abteilungen |
|
| AbtBez |
AbtLeiter |
Standort |
| PW |
Sommer |
München |
| IT |
Winter |
Ulm |
| RE |
Müller |
München |
| VB |
Stepper |
München |
| |
PW=Personalwesen, IT=Datenverarbeitung, RE=Rechnungswesen, VB=Vertrieb |
|
Nun noch die Objektklasse der Projekte. Für diese wird eine Bezeichnung (Bez), der Tag der Einrichtung (TagEinr), die Dauer und das Budget erfasst. |
|
Tabelle Projekte |
|
| Bez |
TagEinr |
Dauer |
Budget |
| LiefPortal |
1.10.2013 |
60 |
200 |
| Ind4p0 |
1.1.2014 |
48 |
600 |
| BPM |
1.4.2013 |
48 |
150 |
| |
Abschließend noch die Objektklasse PC. Sie beschreibt die imUnternehmen benutzten PCs. |
|
Tabelle PC |
|
| InvNr |
PCBez |
Typ |
| pc2012 |
HP xyz |
Desktop Büro |
| pc3015 |
Acer zyx |
Desktop Entwickler |
| Pc1414 |
HP Envy xxx |
Laptop |
| |
Genau solche Tabellen werden, wenn sie bestimmte Eigenschaften haben, Relationen genannt. Relationen sind also - auf dieser Ebene der Modellierung - nichts anderes als nach bestimmten Regeln gestaltete Tabellen, mit denen jeweils eine Objekt- oder Beziehungsklasse beschrieben wird. |
|
3.2 Eigenschaften und Darstellung von Relationen |
|
Folgendes sind die Eigenschaften, die eine Tabelle erfüllen muss, um zur Relation zu zu werden: |
|
|
(1) Jede Zeile (auch "Reihe" oder "Tupel") beschreibt ein Objekt (bzw. eine Beziehung), die Tabelle als Ganzes beschreibt die Objekt- oder Beziehungsklasse.
|
|
|
(2) In jeder Spalte steht als Kopf der Name eines Attributs, darunter stehen die Attributsausprägungen, die das jeweilige Objekt (die Beziehung) beschreiben.
|
|
|
(3) Eine Relation hat immer einen Schlüssel, der auch aus mehr als einem Attribut bestehen kann, und mindestens ein beschreibendes Attribut.
|
|
|
(4) Es gibt keine zwei identischen Tupel, d.h. jedes Tupel beschreibt ein anderes Objekt.
|
|
|
(5) Im Schnittpunkt jeder Zeile und Spalte wird genau eine Attributsausprägung festgehalten, nicht mehr. Dies macht die Tabelle zur ::i::flache Tabelle (Def.)::j::flachen Tabelle.
|
|
Zu 1: Dies ist am Anfang der Erstellung eines Datenmodells richtig. Später, wenn eventuelle Redundanzen in den Modellentwürfen beseitigt werden - Stichwort Normalisierung (vgl. die Kapitel 7 - 13 in [Staud 2021]) - werden die Attribute zu einem Objekt u.U. auf mehrere Relationen und damit auf mehrere Tupel verteilt. |
|
Zu 2: So wurden die Tabellen ja oben bereits eingeführt. |
|
Zu 3: Denn ein Schlüssel alleine hat nicht allzuviel Aussagekraft. |
|
Zu 4: Dies kann man auch mit der mathematischen Herleitung der relationalen Theorie begründen, vgl. [Staud 2006, Abschnitt 3.22]. Es genügt aber auch, sich klar zu machen, dass zwei Tupel einer Relation mit demselben Schlüssel und denselben Attributen keinen Sinn machen, denn sie beschreiben ja dasselbe Objekt bzw. die dieselbe Beziehung. |
|
Zu 5: Die letztgenannte Eigenschaft ist besonders wichtig in der relationalen Theorie und bereitet beim Aufbau einer Datenbank (bei der Erstellung des Datenmodells) auch einige Schwierigkeiten. Sie bedeutet konkret, dass eine Tabelle umorganisiert werden muss, wenn einem Objekt mehr als eine Ausprägung eines Attributs zugeordnet werden kann. Man spricht dann von Mehrfacheinträgen oder auch Wiederholungsgruppen (repeating groups).). Wäre z.B. in der folgenden Abbildung auch das Attribut BezProj (Projektbezeichnung) mitaufgeführt (Projekte, in denen die Angestellten mitarbeiten), könnten Mehrfacheinträge entstehen, wenn ein Angestellter in mehreren Projekten mitarbeitet. |
|
Die oben eingeführten Tabellen erfüllen alle diese Anforderungen und können deshalb als Relationen weiter geführt werden. |
|
Im Mittelpunkt: Flache Tabellen |
|
Auf diesen Relationen und nur auf ihnen beruht die relationale Theorie und auf diesem wiederum die Relationalen Datenbanksysteme (RDBS). Alle Objekt- und Beziehungsklassen werden durch Relationen erfasst und nur durch diese. |
|
Auch die relationalen Datenbanksysteme sind voll auf diesen Informationstyp zugeschnitten. Sie besitzen Befehle zum Einrichten dieser Relationen, zum Festlegen der Attribute usw. Sie erlauben dann, Relationen miteinander zu verknüpfen und auszuwerten, usw. |
|
Die folgende Abbildung zeigt, wie Relationen als Tabellen dargestellt werden können und wie sie aufgebaut sind. Zu jeder Relation gehört eine Bezeichnung, hier Angestellte. In der obersten Zeile stehen die Bezeichnungen der Attribute. Hier sind schon mal Schlüssel (identifizierendes Attribut) und Fremdschlüssel markiert, sie werden unten erläutert. In den Zeilen darunter stehen die Ausprägungen der in der Kopfzeile angegebenen Attribute. Diese Zeilen werden in der relationalen Theorie Tupel genannt. Somit beschreibt ein Tupel ein Objekt oder eine Beziehung (vgl. dazu den nächsten Abschnitt). Die Attribute, die Fremdschlüssel sind, dienen zur Verknüpfung, vgl. die Definition oben und die genauere Darstellung im nächsten Abschnitt. |
|
Darstellung 1: didaktisch motivierte grafische Darstellung |
|
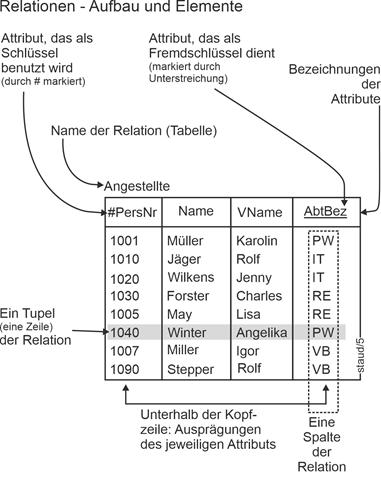
|
|
Abbildung 3.2-1: Aufbau von Relationen. |
|
Abteilungen:
PW: Personalwesen
IT: Information Technologie (EDV)
RE: Rechnungswesen
VB: Vertrieb
Attribute:
PersNr: Personalnummer
VName: Vorname
AbtBez: Abteilungsbezeichnung |
|
Darstellung 2: textliche Darstellung |
|
Neben dieser grafischen Darstellung wird für Relationen auch die folgende textliche Schreibweise benutzt: |
|
Relationenname (#A1, A2, A3, ...) |
|
Dabei stehen A1, A2 usw. für die Attribute der Relation. Die Raute kennzeichnet das Schlüsselattribut, die Unterstreichung den Fremdschlüssel. Für das Beispiel oben also: |
|
Angestellte (#PersNr, Name, VName, ..., AbtBez) |
|
Mehrere Attribute im Schlüssel. Es kommt vor, dass der Schlüssel einer Relation aus mehreren Attributen besteht, z.B. bei bestimmten Beziehungen (vgl. dazu den nächsten Abschnitt). Dann werden die Schlüsselattribute (hier A1 und A2) in Klammern gefasst: |
|
Relationenname (#(A1, A2), A3, A4, ...) |
|
SQL. Soll ein Attributsnamen um die Angabe seiner Relation ergänzt werden (z.B. in SQL, wo es teilweise unabdingbar ist), wird der Relationenname voran gestellt: |
|
Relationenname.Attributname |
|
Also z.B. Angestellte.Name oder Abteilungen.AbtLeit. |
|
Hier nun alle obige Relationen zum Anwendungsbereich Angestellte in dieser textlichen Darstellungsweise: |
|
Angestellte (#PersNr, Name, VName, DatEinst, GebTag) |
|
Abteilungen (#AbtBez, AbtLeiter, Standort) |
|
Projekte (#Bez, TagEinr, Dauer, Budget) |
|
PC (#InvPC, PCBez, Typ) |
|
Die Schlüssel bedeuten: |
|
- PersNr: Personalnummer
- AbtBez: Kurzbezeichnung der Abteilung
- InvPC: Inventarnummer des PC
- Bez: Bezeichnung des Projekts
|
|
Darstellung 3: Korrekte grafische Darstellung von Relationen in Datenmodellen |
|
Die eigentliche grafische Darstellungsweise für Relationen in Datenmodellen ist wie in der folgenden Abbildung angegeben. In einem Rechteck wird in der oberen Hälfte der Relationenname angegeben, darunter die Schlüssel und Fremdschlüssel (und nur diese). Diese Darstellung wird benötigt, wenn ganze Datenmodelle (also viele Relationen mit ihren Verknüpfungen) dargestellt werden sollen (vgl. hierzu Kapitel 7 bis 13 und insbesondere die zahlreichen Beispiele in den Kapiteln 16 und 17 von [Staud 2021]; Auszüge: https://www.staud.info/rm2/rm_t_1.php). |
|
Fremdschlüssel dienen der Verknüpfung verschiedener Relationen miteinander und sind deshalb von großer Bedeutung in der relationalen Modellierung. Sie werden im nächsten Kapitel erläutert. |
|

|
|
Abbildung 3.2-2: Grafische Darstellung von Relationen |
|
Beispiele aus dem Anwendungsbereich Angestellte |
|
In dem in diesem Abschnitt eingeführten Beispiel soll es um den Anwendungsbereich Angestellte eines Unternehmens (in vereinfachter Form) gehen. Hier die grafische Darstellung der vier Relationen. |
|

|
|
Abbildung 3.2-3: Relationen aus dem Anwendungsbereich Angestellte |
|
Soweit die Relationen des Beispiels und ihre Darstellung. Die folgende Tabelle fasst die Grundbegriffe zu Relationen zusammen. Dabei sind die Begriffe der datenbanktheoretischen Diskussion um die informellen Begriffe ergänzt, soweit solche existieren. |
|
Relationale Begrifflichkeit |
|
| Informell |
Formell |
Englisch |
| Tabelle |
Relation |
Table |
| Zeile |
Tupel |
row, tuple |
| Eigenschaft - Bezeichnung |
Attribut(sname) |
attribute |
| Eigenschaft - Ausprägung |
Attributsausprägungen |
domain |
| |
3.3 Warum werden diese Tabellen Relationen genannt? |
|
Im Deutschen wird Relation mit Beziehung assoziiert. Deshalb verwechseln einige Autoren hier die Tabellenbezeichnung mit der relationalen Verknüpfung, die ja auch eine Beziehung darstellt. In der relationalen Datenbanktheorie bezeichnet Relation aber die oben beschriebenen Tabellen. Das kommt von den Urhebern der relationalen Theorie, Codd und Date. Nehmen wir den Begriff relationship als Anknüpfungspunkt, dann war die Idee auszudrücken, dass die Attribute einer Relation in einer engen Beziehung stehen. Sie beschreiben jeweils ein Objekt bzw. ein Tupel. |
|
Relationen sind insbesondere nicht die relationalen Verknüpfungen zwischen den Tabellen, wie es in der populären Literatur oft ausgeführt wird. |
|
Vgl. zu den Urhebern der relationalen Datenbanktheorie beispielhaft: |
|
Codd 1970
Codd, E. F. A relational model of data for large shared data banks, in: Communication ACM, ACM, Vol. 13, No. 6, S. 377-387, Juni 1970 |
|
Date 1990
Date, C.J.: An Introduction to Database Systems. Volume I (5. Auflage), Reading u.a. 1990 |
|
3.4 Attribute und funktionale Abhängigkeiten |
|
Die folgenden Ausführungen stützen sich auf die Relation Aufträge, die ganz normale kaufmännische Aufträge erfasst und die folgenden Aufbau hat: |
|
Aufträge (#(AuftrNr, PosNr), AuftrDatum, KuNr, KuName, ProdNr, ProdBez, Menge) |
|
AuftrNr: Auftragsnummer
PosNr: Positionsnummer
KuNr: Kundennummer
AuftrDatum: Auftragsdatum
KuName: Kundenname
ProdNr: Produktnummer
ProdBez: Produktbezeichnung
Menge: Anzahl Artikel je Position |
|
Attribute können unterschiedliche Rollen in relationalen Datenmodellen einnehmen und sie stehen untereinander in Beziehung. Im einzelnen: |
|
- ::i::Schlüssel (Definition)::j::Sie können die einzelnen Tupel identifizieren. Dann werden sie Schlüssel genannt. Gibt es mehrere Schlüssel, ist einer der Primärschlüssel. Schlüssel können auch aus mehreren Attributen zusammengesetzt sein.
- ::i::Schlüsselattribut (Definition)::j::Falls sie Teil eines zusammengesetzten Schlüssels sind, werden sie Schlüsselattribute(SA) genannt
- ::i::Nichtschlüsselattribut (Definition)::j::Attribute, die nicht Teil eines Schlüssels sind, werden Nichtschlüsselattribute(NSA) genannt
- ::i::Determinante::j::Attribute können voneinander funktional abhängig sein. Dies bedeutet, dass von einem Attribut (z.B. Personalnummer) auf ein anderes (Name) geschlossen werden kann. Jedes Attribut, von dem andere funktional abhängig sind, wird Determinante (D) genannt.Im obigen Beispiel Angestellte wäre also Personalnummer die Determinante, weil jeder Schlüssel auch eine Determinante ist. Aber natürlich gibt es auch Determinanten, die keine Schlüssel sind. Dazu gleich mehr.
|
|
Stellt man die Attribute einer Relation als beschriftete Rechtecke dar und trägt die funktionalen Abhängigkeiten als Pfeillinie zwischen den Attributen ein, entsteht eine Abbildung wie die folgende, die sehr viel zur inneren Struktur der Relation aussagt. Sie wird FA-Diagramm genannt. In der Abbildung wurden zusätzlich noch die Rollen der Attribute vermerkt. |
|
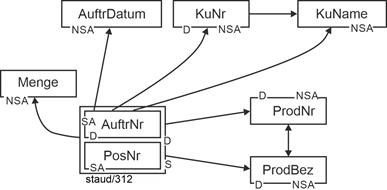
|
|
Abbildung 3.4-1: Funktionale Abhängigkeiten der Relation Aufträge |
|
S: Schlüssel
SA: Schlüsselattribut
NSA: Nichtschlüsselattribut
D: Determinante |
|
3.5 Volle und nicht-volle funktionale Abhängigkeit |
|
Wenn die Determinante aus mehreren Attributen besteht und wenn darin Attribute sind, die man für die Betrachtung einer bestimmten funktionalen Abhängigkeit nicht benötigt, dann ist die funktionale Abhängigkeit eine nicht volle. |
|
Umgekehrt: Sind alle Attribute der Determinante für die betrachtete funktionale Abhängigkeit nötig, spricht man von einer vollen funktionale Abhängigkeit. |
|
Beispiel: |
|
Betrachten wir die Relation Aufträge(#AuftrNr, KuNr, KuName, Ort). |
|
- Funktionale Abhängigkeit: (AuftrNr, KuNr) => KuName
|
|
Hier liegt eine nicht volle funktionale Abhängigkeit vor, da KuNr allein schon ausreicht, um KuName zu bestimmen. AuftrNr wird dafür nicht benötigt. |
|
- Funktionale Abhängigkeit: (AuftrNr) => AuftrDatum
|
|
Dies ist eine volle funktionale Abhängigkeit, da AuftrNr allein notwendig und hinreichend ist, um AuftrDatum zu bestimmen. |
|
Vgl. [Staud 2021, Kapitel 8] für eine ausführliche Darstellung (https://www.staud.info/rm2/rm_t_1.php#Kapitel9). |
|
3.6 Anomalien |
|
Wir betrachten hier nochmals die Relation Aufträge: |
|
Aufträge (#(AuftrNr, PosNr), AuftrDatum, KuNr, KuName, ProdNr, ProdBez, Menge) |
|
Relationen können eine ordentlich aussehende Tabelle darstellen und doch fehlerhafte Strukturen aufweisen. Dies rührt daher dass die in Abschnitt 2.2 definierten Regeln für korrekte Relationen nicht beachtet werden. Dies wird mit der oben schon angeführten Relation Aufträge erläutert, die zur Veranschaulichung mit erfundene Daten befüllt wurde. |
|
Diese Relation hält Informationen zu Aufträgen fest. Die AuftrNr identifiziert den Auftrag, die PosNr die einzelnen Positionen eines Auftrags. Jede Position bezieht sich auf ein Produkt, das durch ProdBez(eichnung) benannt und zusätzlich durch die ProdNr identifiziert wird. Menge gibt an, wieviele Produkte in der Position aufgeführt sind. Das Attribut KuNr identifiziert den Kunden, auf den sich der Auftrag bezieht. Die Kundennamen (KuName) sind nicht eindeutig. |
|
Aufträge_1NF |
|
| AuftrNr |
PosNr |
ProdNr |
ProdBez |
Menge |
AuftrDatum |
KuNr |
KuName |
| 0001 |
1 |
9901 |
Laser Dru x |
1 |
30.06.22 |
1700 |
Müller |
| 0001 |
2 |
9910 |
Toner xyz |
3 |
30.06.22 |
1700 |
Müller |
| 0001 |
3 |
9905 |
Papier abc |
5.000 |
30.06.22 |
1700 |
Müller |
| 0010 |
1 |
9905 |
Papier abc |
30.000 |
01.07.24 |
1201 |
Sammer |
| 0010 |
2 |
9910 |
Toner xyz |
1 |
01.07.24 |
1201 |
Sammer |
| 0011 |
1 |
9901 |
Laser Dru x |
1 |
02.07.25 |
1600 |
Stanzl KG |
| 0011 |
2 |
9911 |
Tintenpatr x |
20 |
02.07.25 |
1600 |
Stanzl KG |
| 0011 |
3 |
9905 |
Papier abc |
5.000 |
02.07.25 |
1600 |
Stanzl KG |
| 0011 |
4 |
9906 |
InkJet-Dru y |
2 |
02.07.25 |
1600 |
Stanzl KG |
| 0012 |
1 |
9998 |
z-Bildschirm |
1 |
04.07.23 |
1900 |
Max OHG |
| ... |
|
|
|
|
|
|
|
| |
Schlüssel: #(AuftrNr, PosNr) |
|
Schlüssel der Relation. Es ist unschwer zu erkennen, dass die beiden Attribute AuftrNr und PosNr den Schlüssel der Relation darstellen, weil mit den Ausprägungen dieser Attribute jedes Tupel (jede Zeile) eindeutig identifiziert werden kann. |
|
Betrachten wir nun die Defizite dieser Relation. Die folgenden drei Anomalien wurden in der Literatur beschrieben: Aktualisierungsanomalie, Einfügeanomalie und Löscheanomalie. |
|
Aktualisierungsanomalie |
|
Eine Aktualisierung, mehrere zu ändernde Tupel. Eine sogenannte Aktualisierungsanomalie liegt vor, wenn die Änderung einer Information dazu führt, dass in mehreren Tupeln die Ausprägung des entsprechenden Attributs verändert werden muss. Dies ist grundsätzlich unerwünscht. Es hat bei der Aktualisierung des Werts die Konsequenz, dass die Zahl der zu ändernden Tupel im Vornehinein unbekannt ist. Unter Umständen muss die gesamte Relation durchsucht werden. |
|
Ursache für eine solche Struktur ist, dass eine bestimmte Information mehrfach in der Datenbank abgespeichert ist. Im obigen Beispiel: Werden die Produktbezeichnungen geändert, indem z.B. der Produktnummer 9901 statt "Laser Dru(cker) x" jetzt "HP Laser Dru Serie 5" zugeordnet wird, dann muss die Prdouktbezeichnung nicht nur in einem Tupel, sondern in mehreren geändert werden. Dies führt leicht dazu, dass die eine oder andere Stelle vergessen wird. |
|
Gleiches gilt für das AuftrDatum. Müssen wir dieses aus irgendwelchen Gründen ändern, muss dies mehrfach geschehen. Auch die Kundennamen weisen diese Eigenschaft auf. Ändert sich der Kundenname des Kunden 1700 von "Müller" nach "Müller amp; Paul", sind bei der Aktualisierung wieder mehrfache Änderungen nötig. |
|
Es ist klar, wodurch diese Anomalie verursacht ist. Durch einen Verstoß gegen die oben angeführte zentrale Regel des Datenbankentwurfs, wonach die Datenbank so zu gestalten ist, dass jede Information nur an einer Stelle gespeichert wird. |
|
Einfügeanomalie |
|
Einfügbarkeit gefährdet. Redundanzen bereiten auch Schwierigkeiten beim einfachen Einfügen von Daten, dies führt zur Einfüge-Anamolie. Eine solche liegt vor, wenn ein neues (noch) unvollständiges Tupel nicht in die Relation eingetragen werden kann, z.B. weil unter den fehlenden Attributen ein Schlüsselattribut ist oder ein Fremdschlüssel. Diese Anomalie beruht also auch auf der oben dargelegten Festlegung, dass ein Tupel in die Relation nur eingetragen werden darf, wenn die Ausprägungen für die Schlüsselattribute (die Attribute, die den Schlüssel ausmachen) vorhanden sind (vgl. Abschnitt 5.9 zur Forderung nach Objektintegrität). |
|
Im obigen Beispiel: Nehmen wir neue Produkte mit ProdNr und ProdBez auf, so können wir sie in der Relation erst erfassen, wenn wir zumindest einen Auftrag mit Positionsnummer haben, in dem sie erscheinen. Sonst wäre eine Erfassung nicht möglich, da ja kein Schlüsselattribut vorliegen würde. Ähnlich gilt für das AuftragsDatum. Es kann erst erfasst werden, wenn die erste Position des Auftrags bekannt ist. Gleiches gilt für KuNr und KuName. |
|
Verschmelzung von Objekten, Objektklassen. Die Ursache für diese Anomalie liegt darin, dass in obiger Relation mehrere verschiedene "Dinge" zusammen beschrieben werden: die Objektklassen Aufträge, Produkte und Kunden, sowie die Beziehungsklasse Aufträge-Kunden. Diese Strukturschwäche wird mit Hilfe des Konzepts der funktionalen Abhängigkeit gelöst (vgl. das nächste Kapitel). |
|
Löscheanomalie |
|
Probleme beim Löschen. Die letzte Anomalie beschreibt Schwierigkeiten, die aus den Redundenzen beim Löschen von Datensätzen auftreten. Von einer Löscheanomalie wird gesprochen, wenn beim Löschen einer Information, die nur einen Teil des Tupels betrifft, auch die übrigen Attributswerte verloren gehen. Im obigen Beispiel: Löscht man den Auftrag 0012, der nur eine Position hat, geht auch die Information verloren, dass z-Bildschirme die Produktnummer 9998 haben. |
|
Wiederum liegt die Ursache in der Vermischung mehrerer Objekt- und Beziehungsklassen in einer Relation. |
|
Ziel |
|
Ordnung in den "Attributshaufen". Was ist das Ziel bei der Erkennung und Beseitigung der Anomalien? Selbst dieses sehr einfachen Beispiele machen deutlich, wohin die drei Anomalien zielen: sie dienen zur Klärung, welche Attribute am besten zusammen erfasst werden und welche besser getrennt werden. Sie bringen also Ordnung in den zu Beginn jeder Modellierung entstehenden "Attributs- und Merkmalshaufen", der sog. Universalrelation. |
|
Während die 1NF dazu führte, dass die Attribute zusammen bleiben, deren Ausprägungen so den Objekten zugeordnet werden können, dass je genau eine Ausprägung mit den anderen kombiniert wird, liegt hier eine andere Situation vor. Hier geht es darum, die Attribute zusammenfassen, die zusammen mit einem Schlüssel einen "homogenen" Block bilden, indem sie genau die vom Schlüssel identifizierten Objekte beschreiben und keine anderen. |
|
Dies wird erreicht durch Beseitigung der Redundanz, die in solchen Relationen angelegt ist. Deren Beseitigung klärt auch die Anordnung der Attribute in der Relation. Ein sehr hilfreiches Mittel für die Klärung der inneren Struktur von Relationen sind die sog. funktionalen Abhängigkeiten, die im nächsten Kapitel betrachtet werden. |
|
3.7 Wie geht es weiter? |
|
Das Festlegen der Relationen ist der erste wichtige Schritt. Danach ist noch folgendes zu leisten: |
|
|
(1) Flache Tabellen herbeiführen. D.h., sicherstellen, dass für jede Ausprägung des Schlüssels genau eine Ausprägung bei jedem Nichtschlüsselattribut (NSA) vorhanden ist. Oben wurde beschrieben, wie die ersten Entwürfe von Relationen entstehen. Beispiel: Angestellte mit #PersNr und Name, Vorname. Projektmitarbeit mit #(PersNr, ProjBez), Beginn, Rolle. Bei jeder solchen Zusammenstellung zu Relationen ist sicherzustellen, dass für jeweils eine Ausprägung des Schlüssels genau eine Ausprägung bei jedem Nichtschlüsselattribut vorhanden ist. Denn: Ein Attribut hat in relationalen Datenbanken pro Objekt nur genau eine Ausprägung. Das bringt die Relationen in die erste Normalform (1NF).
|
|
|
(1) Sicherstellen, dass die für eine Relation ausgewählten Attribute wirklich alle Objekte oder Beziehungen der Relation beschreiben. D.h.: Das Attribut muss auf alle anwendbar sein, so dass keine semantisch bedingten Leereinträge (vgl. [Staud 2021, S. 183f]) auftreten. Beispiel: ProgrSpr (beherrschte Programmiersprache) in einer Datenbank zu Angestellten, in der auch Nicht-Programmierer erfasst sind.
|
|
|
(3) Die durch obige Schritte entstehenden Beziehungen (Schlüssel-/Fremdschlüssel-Beziehungen) präzisieren. Wegweisend ist hierfür die grundsätzliche Regel: Alle Relationen sind (zumindest lose miteinander verknüpft. Diese bedeutet nicht, dass jede Relation mit allen anderen direkt verbunden ist, sondern, dass jede Relation mit dem Gesamtmodell verknüpft sein muss.
|
|
|
(4) Gefundene Relationen hinsichtlich der weiteren Normalformen präzisieren. Dabei entstehen i.d.R. weitere Schlüssel-/Fremdschlüssel-Beziehungen. Die Zerlegungen im Rahmen der Normalisierung dürfen zu keinem Informationsverlust führen. D.h., es ist immer darauf zu achten, dass durch relationale Verknüpfungen entlang von Schlüsseln und Fremdschlüsseln die in der Ausgangsrelation vorhandene Information erhalten bleibt.
|
|
|
(5) Weitere Beziehungen klären und im Datenmodell anlegen. Dies betrifft semantisch begründete Beziehungen, die sich nicht direkt aus der Attributkonstellation oder der Methode ergeben.
|
|
|
(6) Muster Generalisierung / Spezialisierung (Gen/Spez) erkennen und anlegen.
|
|
|
(7) Weitere Muster (Einzel/Typ, Aggregation, Komposition) abklären und anlegen.
|
|
|
(8) Zeitliche Aspekte klären und modellieren, auch die in der Anforderung vergessenen.
|
|
Die Methoden und Vorgehensweisen dafür werden in den folgenden Kapiteln beschrieben. |
|
4 Muster überall |
|
Mit Mustern sind hier solche gemeint, die sich in relationalen Datenmodellen ergeben. Dabei können Muster, die sich durch die Methode und Muster, die sich aus der Semantik des Anwendungsbereichs ergeben, unterschieden werden. |
|
Methodische Muster - "Methode sucht Syntax" |
|
Das sind z.B. solche, die sich aus den Normalformen ergeben. Deren Realisierung führt sehr oft zu Zerlegungen, die realisiert und bewältigt werden müssen. So muss z.B. eine neue weitere Relation erstellt werden, wenn in der Ausgangsrelation Mehrfacheinträge vorliegen. Grundlage sind die relationalen Verknüpfungen, von 1:1- bis zu n:m-Beziehungen. Vgl. für eine vertieftere Darstellung Kapitel 5 in [Staud 2021] und |
|
www.staud.info/rm2/rm_t_1.htm#Kapitel6 |
|
Semantische Muster - "Semantik sucht Syntax" |
|
Das sind solche, die sich aus der Erfassung und Modellierung semantischer Beziehungen ergeben. Z.B. Angestellte arbeiten in Abteilungen, Angestellte haben zugeordnete PCs, Dozenten halten Vorlesungen. Auch diese werden über die relationalen Verknüpfungen realisiert. Vgl. für eine grundsätzliche Darstellung der Umsetzung von Beziehungen in Datenmodellen |
|
https://www.staud.info/Beziehungen/bz_t_1.php |
|
|
|
|
|
5 Beziehungen und Kardinalitäten |
|
In den folgenden Kapiteln wird gezeigt, dass im Rahmen der Datenmodellierung zahlreiche einzelne Relationen entstehen, die miteinander in Beziehung stehen und die im Rahmen von Auswertungen u.U. miteinander verknüpft werden müssen. Die methodischen Grundlagen dafür werden hier erläutert. |
|
Die Beziehungen sind hier Beziehungen zwischen den Tupeln verschiedener Relationen. Diese werden durch Schlüssel-/Fremdschlüssel - Kombinationen ausgedrückt. Dabei werden folgende Wertigkeiten unterschieden: |
|
- 1:1. Ein Tupel der einen Relation steht mit einem der anderen in Beziehung. Beispiel: Rechnungen und Kunden.
- 1:n. Ein Tupel der einen Relation steht mit mehreren der anderen in Beziehung. Beispiel: Rechnungsköpfe und Rechnungspositionen.
- N:m. Ein Tupel der einen Relation steht mit mehreren der anderen in Beziehung und umgekehrt. Beispiel: Projekte und Angestellte.
|
|
Diese Wertigkeiten werden Kardinalitäten genannt. |
|
Hier werden sie im folgenden noch präzisiert, indem angegeben wird, ob auch eine optionale Teilhabe möglich ist und wieviele maximal teilhaben. Diese Min-/Max-Angaben sind datenbanktechnisch sinnvoll, weil dadurch die Semantik des jeweiligen Ausschnitts besser beschrieben wird. Sie bestehen aus zwei durch ein Komma getrennten Werten, bei denen der erste Wert die minimale Teilhabe und der zweite Wert die maximale Teilhabe ausdrückt. Diese Notaiton ist der objektorientierten Theorie entlehnt. |
|
Dabei entstehen dann folgende Varianten für die Beziehungswertigkeiten: |
|
Für die Kardinalität 1:1 |
|
- 1,1 : 1,1
- 0,1 : 1,1
- 1,1 : 0,1
- 0,1 : 0,1
|
|
Für die Kardinalität 1:m |
|
- 1,1 : 1,n
- 0,1 : 1,n
- 1,1 : 0,m
- 0,1 : 0,n
|
|
Für die Kardinalität n:m |
|
- 1,n : 1,m
- 0,n : 1,m
- 1,n : 0,m
- 0,n : 0,m
|
|
|
|
5.1 Kardinalität 1:1 |
|
Mehr dazu in [Staud 2021, Abschnitt 5.3] und https://www.staud.info/rm2/rm_t_1.php#Kapitel6 |
|
Ist die Semantik so, dass ein Tupel der einen Relation mit einem der anderen verknüpft ist und umgekehrt, dann liegt die Kardinalität 1:1 vor. Als Beispiel können aus einer Personaldatenbank die Relationen Angestellte und PC genommen werden, wenn durch die Semantik festgelegt ist, dass jeder Mitarbeiter nur genau einen PC zugewiesen bekommt und jeder PC von nur einem Mitarbeiter genutzt wird. |
|
Auch hier kann durch die Min-/Max-Angaben präzisiert werden: |
|
- 1,1 : 1,1 bedeutet, dass jedes Tupel der einen Relation mit genau einem der anderen verknüpft wird und umgekehrt (Angestellte - Adressen).
|
|
Im Beispiel: Ein Angestellter bekommt genau einen PC zugewiesen und jeder PC ist nur einem Angestellten zugeordnet. |
|
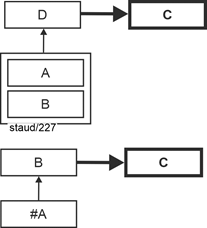
Die relationale Theorie lässt dafür zwei Lösungen zu, die in der folgenden Abbildung angegeben sind. Eine der beiden Relationen "liefert" ihren Schlüssel als Fremdschlüssel in die andere. Damit ist die Semantik und die Verknüpfung korrekt in der Datenbank verankert. Hier die grafische Darstellung. |
|
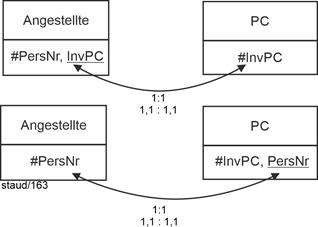
|
|
Abbildung 5.1-1: Zwei methodisch gleichwertige Lösungen für:
Kardinalität 1:1 mit Min-/Max-Angaben 1,1 : 1,1 |
|
Nun die weiteren Varianten: |
|
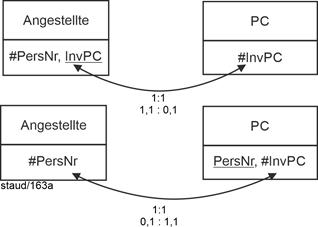
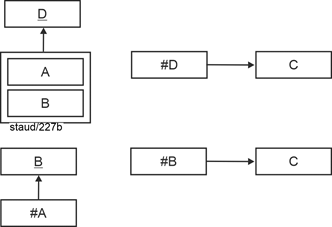
- 1,1 : 0,1 oder 0,1 : 1,1 bedeutet, dass von der Relation mit dem optionalen Attribut (Minimum 0) der Schlüssel als Fremdschlüssel in die andere Relation kommt.
|
|
Im Beispiel: Falls nicht jeder PC einen Angestellten zugewiesen bekommt, wird InvPC zum Fremdschlüssel in Angestellte. Falls nicht jeder Angestellte einen PC hat, wird PersNr zum Fremdschlüssel in PC. Vgl. die folgende Abbildung für die grafische Realisierung. |
|
|
|
Abbildung 5.1-2: Kardinalität 1:1 mit Min-/Max-Angaben 0,1 : 1,1 oder 1,1 : 0,1 |
|
Die letzte Variante: |
|
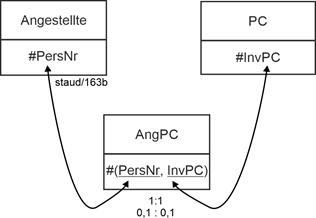
- 0,1 : 0,1 bedeutet, dass in beiden Relationen die Teilnahme an der Beziehung optional ist. Die relationale Theorie verlangt dafür die Einrichtung einer eigenen Relation mit einem aus den Schlüsseln der beiden Relationen bestehenden Schlüssel.
|
|
Im Beispiel: Die neue Relation AngPC (Angestellte/PC) erhält den Schlüssel #(PersNr, InvPC). Jeder Fremdschlüssel stellt die Verbindung zu der Relation her, in der er Schlüssel ist. Vgl. die folgende Abbildung für die grafische Realisierung. |
|
|
|
Abbildung 5.1-3: Kardinalität 1:1 mit Min-/Max-Angaben 0,1 : 0,1 |
|
Zu vermeidende Fehlerquelle: Obiges ist keine Verbindungsrelation, wie sie weiter unten bei n:m-Beziehungen entsteht. |
|
5.2 Kardinalität 1:n |
|
Vgl. https://www.staud.info/rm2/rm_t_1.php#Abschnitt6.5 für eine vertiefte Darstellung. |
|
1,1 : 1,n. Die erste Variante ist der Fall, an den man denkt, wenn man die Kardinalität 1:n wahrnimmt. In der Realität ist sie aber eher die Ausnahme. Bei ihr nimmt jedes Tupel der beiden Relationen an der Beziehung teil. |
|
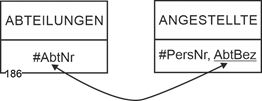
Im Beispiel Abteilungen / Angestellte bedeutet dies - durchaus nachvollziehbar - dass jede Abteilung Angestellte hat (mindestens eine/n) und jede/r Angestellte in einer Abteilung ist. Dementsprechend kann der Schlüssel von Abteilungen in der Angestelltenrelation hinterlegt werden: |
|
Abteilungen (#AbtBez, AbtLeiter, Standort) |
|
Angestellte (#PersNr, Name, VNname, DatEinst, GebTag, AbtBez) |
|
Umgekehrt geht dies nicht. Der Schlüssel von Angestellte in Abteilungen würde zu Mehrfacheinträgen führen, was für relationale Datenmodelle verboten ist. Die folgende Abbildung zeigt die Umsetzung in ein Datenmodell. |
|
|
|
Abbildung 5.2-1: Relationale Verknüpfung für Abteilungen / Angestellte und die Min-/Max-Angaben 1,n : 1,1 |
|
Kardinalität: 1:n
Min-/Max-Angaben: 1,n : 1,1
Semantik:
- Eine Abteilung hat mindestens einen Angestellten.
- Ein Angestellter ist genau einer Abteilung zugeordnet. |
|
1,1 :0,n. Diese Variante bedeutet, dass der Fremdschlüssel in der Relation mit Pflichtteilnahme hinterlegt werden muss. Dies ist dann die, von der jedes Tupel genau eine Beziehung eingeht. Sie bedeutet in diesem Beispiel, dass es Abteilungen gibt, denen (noch) keine Angestellten zugeordnet sind, z.B. weil sie zwar eingerichtet aber noch nicht mit Personal ausgestattet wurden. Andererseits nehmen alle Angestellten an der Beziehung teil. Deshalb kann die Umsetzung hier genauso wie im vorigen Fall sein. |
|
0,n : 1,1. Neue Relation. Diese Variante bedeutet, dass der Fremdschlüssel in der Relation hinterlegt werden müsste, bei der jedes Tupel eine mehrfache Beziehung eingehen könnte. Dies ist aber nicht möglich, weil dabei Mehrfacheinträge entstehen würden. Damit ergibt sich hier die Notwendigkeit für die relationale Beziehung eine neue Relation (Abteilungszughörigkeit; AbtZug) einzurichten. |
|
0,1 : 0,n. Genau dasselbe gilt für die Variante 0,1 : 0,n. Sie bedeutet ja, dass der Fremdschlüssel in keiner der beiden Relationen untergebracht werden kann, da es dann in beiden Fällen Tupel gäbe, bei denen der Fremdschlüssel keinen Eintrag haben könnte und ein Fall sowieso wegen drohender Mehrfacheinträge nicht in Frage kommt. Also auch hier die neue Relation. Für beide obigen Fälle ergibt sich damit die folgende Lösung. |
|
Abteilungen (#AbtBez, AbtLeiter, Standort) |
|
Angestellte (#PersNr, Name, VNname, DatEinst, GebTag) |
|
AbtZug (#(AbtBez, PersNr)) |
|
Die neue Relation hat einen zusammengesetzten Schlüssel, bestehend aus den zwei Fremdschlüsseln. Die folgende Abbildung zeigt das dabei entstehende kleine Datenmodell. |
|
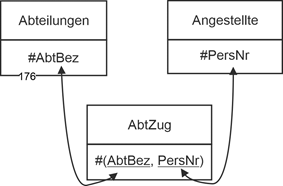
|
|
Abbildung 5.2-2: Relationale Verknüpfung für Abteilungen / Angestellte und die Min-/Max-Angaben 0,1 : 1,n sowie 0,1 : 0,n |
|
Kardinalität: 1:n
Min-/Max-Angaben: 0,1 : 1,n oder 0,1 : 0,n.
Semantik 0,1 : 1,n:
- Einer Abteilung ist kein Angestellter, einer oder es sind mehrere zugewiesen.
- Ein Angestellter ist keiner oder genau einer Abteilung zugewiesen.
Semantik 0,1 : 0,n:
- Einer Abteilung ist ein Angestellter zugewiesen oder mehrere ("mindestens einer").
- Ein Angestellter ist keiner oder genau einer Abteilung zugewiesen |
|
5.3 Umsetzung von n:m |
|
Vgl. https://www.staud.info/rm2/rm_t_1.php#Abschnitt6.6 für eine vertiefte Darstellung. |
|
Eine Kardinalität von n:m bedeutet, dass mehrere Tupel der einen Relation mit mehreren der anderen in Beziehung stehen und dies in beide Richtungen. |
|
Realisierung der Verknüpfung durch eine Verbindungsrelation |
|
Die Lösung besteht hier immer aus der Einrichtung einer neuen Relation, da jede Übernahme eines Schlüssels in die andere Relation zu Mehrfacheinträgen führen würde. In der neuen Relation, die Verbindungsrelation genannt wird, sind die beiden Schlüssel der zu verknüpfenden Relationen zusammen Schlüssel und dabei einzeln jeweils Fremdschlüssel. Hier ergibt die Betrachtung der verschiedenen Min-/Max-Angaben keine Notwendigkeit für spezielle Lösungen. In allen Varianten leistet die Verbindungsrelation die problemfreie Verknüpfung. |
|
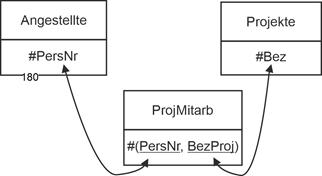
Beispiel Projektmitarbeit. So bei einer Beziehung "Projektmitarbeit" zwischen Angestellten und Projekten einer Organisation. Ein Angestellter kann in mehreren Projekten mitarbeiten, ein Projekt kann mehrere Angestellte zugewiesen haben: |
|
Angestellte (#PersNr, Name, VNname, DatEinst, GebTag) |
|
Projekte (#Bez, TagEinr, Dauer, Budget) |
|
Die Verbindungsrelation ergibt sich wie folgt: |
|
ProjMitarb (#(PersNr, BezProj)) |
|
Zusammen mit den Ausgangsrelationen ergibt sich ein kleines Datenmodell, das die n:m-Beziehung in allen Min-/Max-Varianten erfasst. |
|
|
|
Abbildung 5.3-1: Relationale Verknüpfung für Angestellte / Projekte und die Kardinalität n:m |
|
Zur Verdeutlichung hier die konkrete Semantik: |
|
1,n : 1,m: Eine Angestellte ist mindestens einem Projekt zugeordnet. Ein Projekt hat mindestens einen zugewiesenen Angestellten. |
|
1,n : 0,n: Eine Angestellte ist keinem, einem oder mehreren Projekten zugewiesen. Ein Projekt hat mindestens einen zugewiesenen Angestellten. |
|
0,n : 1,m: Eine Angestellte ist mindestens einem Projekt zugeordnet. Ein Projekt hat keinen, einen oder mehrere zugewiesene Angestellte. |
|
0,n : 0,m: Eine Angestellte ist keinem, einen oder mehreren Projekten zugewiesen. Ein Projekt hat keinen, einen oder mehrere zugewiesene Angestellte. |
|
Der Schlüssel ist hier immer aus zwei Attributen zusammengesetzt. Für jedes Tupel müssen beide Attribute Einträge haben. |
|
6 Normalformen |
|
In diesem Kapitel geht es um die Optimierung des ersten Entwurfs bzgl. der Vorgaben der relationalen Theorie. Dabei entstehen Zerlegungen von Relationen, die durch die Methode bedingt sind, also methodische Muster. Da meist der Wunsch besteht, die Daten auch in bestimmten Auswertungssituationen wieder zusammenzuführen, werden Verknüpfungen angelegt. Dies erfolgt über Schlüssel und Fremdschlüssel. |
|
Bei den Relationen werden jetzt auch die erreichten Normalformen angegeben. Z.B. Angestellte_1NF, Angestellte_2NF usw. oder auch Angestellte_UN (unnormalisiert, nicht 1NF; vgl. unten). |
|
|
|
6.1 Erste Normalform - 1NF |
|
Für eine vertiefte Darstellung vgl. https://www.staud.info/rm2/rm_t_1.php#Kapitel8 |
|
Oben - bei der Definition von Relationen - wurde bereits beschrieben, dass Relationen flache Tabellen (d.h. ohne Mehrfacheinträge) mit den angeführten Eigenschaften sind. Dann sind sie auch gleich in erster Normalform (1NF). Solange sie diese Eigenschaften nicht voll erfüllen werden sie, sprachlich nicht ganz korrekt, als unnormalisierte Relationen bezeichnet. |
|
Definition 1NF |
|
Eine Relation ist in 1NF, falls sie keine Mehrfacheinträge aufweist. |
|
Betrachten wir das folgende Beispiel. |
|
Die Relation Prod_UN erfasst abstrahiert und vereinfacht Hersteller von Datenbanksystemen, mit den Datenbanksystemen und Adressangaben. |
|
Prod_UN |
|
| #NameProd |
BezDBS |
Ort |
Straße |
Land |
| Microsoft |
FoxPro, ACCESS |
AAA |
... |
... |
| CA |
INGRES |
CCC |
... |
... |
| Oracle |
Oracle |
DDD |
... |
... |
| ... |
|
|
|
|
| |
CA: Computer Associates / Broadcom
NameProd = Name des Herstellers eines Datenbanksystems.
BezDBS = Name des Datenbanksystems.
Land = Adressangaben zum Produzenten. |
|
Tupelvermehrung |
|
Eine Methode, eine unnormalisierte Relation in die 1NF zu bringen, ist die Tupelvermehrung. Dabei wird für jeden Mehrfacheintrag ein eigenes Tupel angelegt. Sie führt hier zu folgender Lösung: |
|
Prod_1NF |
|
| NameProd |
#BezDBS |
Ort |
Straße |
Land |
| Microsoft |
FoxPro |
AAA |
... |
... |
| Microsoft |
ACCESS |
AAA |
... |
... |
| CA |
IDMS |
CCC |
... |
... |
| CA |
Datacom |
CCC |
... |
... |
| Oracle |
Oracle |
DDD |
... |
... |
| ... |
|
|
|
|
| |
Zu beachten ist der neue Schlüssel. Mit der semantischen Festlegung, dass jedes Datenbanksystem von genau einem Unternehmen hergestellt wird, ist der neue Schlüssel #BezDBS. Wäre die Semantik so, dass u.U. auch mehrere Unternehmen zusammen ein Datenbanksystem herstellen, wäre der Schlüssel #(NameProd, BezDBS). |
|
Wie man sieht, führt das obige Verfahren erstmals zu Redundanzen bei den Nichtschlüsselattributen (NSA), die dann aber im nächsten Schritt beseitigt werden. Will man dieses vorübergehende Auftreten von Redundanzen nicht, muss man eines der Verfahren wählen, die in den nächsten zwei Abschnitten vorgestellt werden. Diese erfordern allerdings ein vertieftes Verständnis relationaler Beziehungen. |
|
Zerlegung nach 1:n |
|
Oftmals rühren Mehrfacheinträge daher, dass eine 1:n - Verknüpfung nicht erkannt wurde. Erkennt man dies, kann man sich den Umweg über die Tupelvermehrung sparen
 und gleich die Zerlegung durchführen. Dann wird also die Ausgangsrelation in zwei miteinander verknüpfte Relationen zerlegt.
und gleich die Zerlegung durchführen. Dann wird also die Ausgangsrelation in zwei miteinander verknüpfte Relationen zerlegt. |
|
Zu erkennen ist dieses Strukturdefizit daran, dass es mindestens ein Attribut gibt, das gegenüber dem Schlüssel Mehrfacheinträge aufweist. Die Lösung ist dann wie folgt: |
|
- Ist es nur ein Attribut, muss dieses identifizierenden Charakter haben. Es wird in eine eigene Relation ausgelagert, zusammen mit dem Schlüssel der Ausgangsrelation. Dieser bildet den Fremdschlüssel für die relationale Verknüpfung. Hier drückt die neue Relation also die Beziehung aus. Vgl. das folgende Beispiel Prod_UN.
- Sind es mehrere, bilden diese eine eigene Relation. Eines ist der Schlüssel, der Schlüssel der Ausgangsrelation bildet den Fremdschlüssel.
|
|
Beispiele |
|
Betrachten wir nochmals die Relation Prod_UN von oben: |
|
Prod_UN (#NameProd, BezDBS, Ort, Straße, Land) |
|
Die Semantik soll so sein [Anmerkung] , dass ein Datenbanksystem auch nur von einem Produzenten hergestellt wird. Dann handelt es sich um eine eindeutige 1:n - Beziehung zwischen Produzenten und Datenbanksystemen [Anmerkung] . Die Zerlegung führt zu folgenden Relationen: |
|
Prod_1NF |
|
| #NameProd |
Ort |
Straße |
Land |
| Microsoft |
... |
... |
... |
| Borland |
... |
... |
... |
| CA |
... |
... |
... |
| ... |
|
|
|
| |
|
|
DBS_1NF |
|
| #BezDBS |
NameProd |
| FoxPro |
Microsoft |
| ACCESS |
Microsoft |
| Visual dBase |
Borland |
| Paradox |
Borland |
| INGRES |
CA |
| ... |
|
| |
Fremdschlüssel: NameProd |
|
Nicht verwirrt sein: Tatsächlich sind diese beiden Relationen, wie im weiteren zu sehen sein wird, bereits in 5NF. |
|
Zerlegung nach n:m |
|
Oftmals gehen Mehrfacheinträge auch darauf zurück, dass in den Daten eine n:m - Beziehung vorliegt und nicht erkannt wird. Dann muss eine Zerlegung in drei Relationen erfolgen. Eine für die erste Objektklasse, eine für die zweite und eine für die Verknüpfung. Letztere wird zur Verbindungsrelation. |
|
Beispiele |
|
Das erste Beispiel betrifft die Angestellten eines Unternehmens und ihre Programmierkenntnisse: |
|
Pers_UN (#PersNr, Name, ProgSpr, Stellenwert) |
|
Die Semantik ist so, dass eine Person mehrere Programmiersprachen beherrschen kann und eine Programmiersprache u.U. von mehreren beherrscht wird. Dann handelt es sich um eine n:m - Beziehung zwischen Angestellten und Programmiersprachen. Das könnte zu folgender Relation führen: |
|
Pers_UN |
|
| #PersNr |
Name |
ProgSpr |
Stellenwert |
| 123 |
Maier |
C, COBOL, PHP, C++ |
1, 4, 2, 3 |
| 456 |
Müller |
C++, Java, C |
3, 5, 10 |
| ... |
|
|
|
| |
Das Attribut Stellenwert beschreibt die Bedeutung, den die Programmiersprache für das Unternehmen hat. Mit diesem Attribut werden also die Programmiersprachen beschrieben. Insgesamt sind die Angestellten, die Programmiersprachen und ihre Programmierkompetenz in dieser Relation erfasst. Zu erkennen ist das Vorliegen einer n:m - Beziehung in den Mehrfacheinträgen entweder aus der Semantik des Anwendungsbereichs heraus, wenn es sich in Wirklichkeit um zwei Objektklassen A und B handelt, die zusammen in einer Relation beschrieben werden, oder durch die einfache Analyse der Daten. Hier machen z.B. die drei folgenden Beziehungen bereits den n:m-Charakter deutlich: |
|
- Maier mit C
- Müller mit C
- Müller mit C++
|
|
D.h., ein Angestellter beherrscht mehrere Sprachen und eine Sprache wird von mehreren Angestellten genutzt. In einem solchen Fall wird die unnormalisierte Relation in drei Relationen zerlegt: eine für die eine Objektklasse, eine für die andere und eine für die Beziehung zwischen ihnen. Die Relationen, die die Objektklassen repräsentieren, erhalten als Schlüssel jeweils eines der Attribute mit Mehrfacheinträgen und alle Attribute, die dieselbe Objektklasse beschreiben. Die Relation für die Beziehungsklasse, die Verbindungsrelation, enthält die beiden Schlüssel, die in ihr zusammen Schlüssel und allein Fremdschlüssel sind. |
|
Im obigen Beispiel entstehen dann folgende Relationen: Personal beschreibt die Objektklasse der Personen, ProgSprachen die der Programmiersprachen und Kompetenz ist die Verbindungsrelation die festhält, welche Person welche Programmiersprache beherrscht. |
|
Personal |
|
| #PersNr |
Name |
| 123 |
Maier |
| 456 |
Müller |
| ... |
|
| |
|
|
ProgSprachen |
|
| #ProgSpr |
Stellenwert |
| C |
1 |
| COBOL |
4 |
| Fortran |
2 |
| Prolog |
3 |
| C++ |
10 |
| ... |
|
| |
|
|
Kompetenz |
|
| ProgSpr |
PersNr |
| C |
123 |
| COBOL |
456 |
| Fortran |
456 |
| Prolog |
789 |
| C++ |
789 |
| ... |
|
| |
Schlüssel: #(ProgSpr, PersNr) |
|
6.2 Zweite Normalform - 2NF |
|
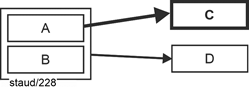
Die zweite Normalform besteht darin, die funktionalen Abhängigkeiten, die von einem Teil des Schlüssels herrühren, zu beseitigen. Nach dessen Beseitigung ist die jeweilige Relation in 2NF und damit redundanzfreier. Ganz abstrakt und auf das Wesentliche reduziert, drückt die folgende Abbildung das Problem bei Relationen aus, die nicht in 2NF sind: Es gibt eine Determinante, die Teil des Schlüssels ist (Schlüsselattribut; SA). Da eine solche Determinante typischerweise mehrere gleiche Ausprägungen hat, wird die davon abhängige Attributsausprägung in C auch mehrfach erfasst. Das Strukturdefizit ist hervorgehoben. |
|
|
|
Abbildung 6.2-1: 1NF und nicht 2NF - abstrakt |
|
6.2.1 Redundanz trotz 1NF |
|
Wo steckt die Redundanz bei einer Relation, die in 1NF und nicht in 2NF ist? Betrachten wir dazu eine Relation zum Vorlesungsbetrieb einer Hochschule: |
|
VorlBetrieb (#(MatrNr, LVNr, DozNr, Tag, Beginn), Name, LVBez) |
|
MatrNr: Matrikelnummer (für Studierende eindeutig)
LVNr: Nummer der Lehrveranstaltung (für Lehrveranstaltungen eindeutig)
DozNr: Personalnummer des Dozenten (für Dozenten eindeutig)
Name: Name des Dozenten
LVBez: Bezeichnung der Lehrveranstaltung |
|
Tag und Beginn identifizieren jeden einzelnen Vorlesungstermin. Es geht also nicht um die Lehrveranstaltungen also solche, sondern um die einzelnen Termine. Der Schlüssel besteht aus zahlreichen Attributen. Jedes Tupel hält fest, dass ... |
|
ein Studierender eine bestimmte Lehrveranstaltung bei einem bestimmten Dozenten an einem Tag mit einem bestimmten Startzeitpunkt ... |
|
besucht. Damit ist ein bestimmter Lehrveranstaltungstermin und sein Besuch durch einen Studierenden eindeutig festgehalten. Es gelten die im FA-Diagramm angegebenen funktionalen Abhängigkeiten. Dies sind beides einfache funktionale Abängigkeiten. |
|
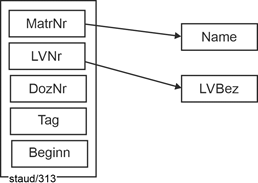
|
|
Abbildung 6.2-2: FA-Diagramm zur Relation VorlBetrieb_1NF |
|
Die Redundanz entsteht dadurch, dass für jeden Lehrveranstaltungstermin der Name des Studierenden und die Bezeichnung der Lehrveranstaltung festgehalten wird. Ursache ist, dass Nichtschlüsselattribute (NSA; Name und VBez) funktional abhängig sind von einem Teil des Schlüssels. |
|
Wird dieses Strukturdefizit beseitigt, entstehen die in den folgenden Abbildungen als FA-Diagramme angegebenen redundanzfreien Relationen. Für die Studierenden und Lehrveranstaltungen je eine neue, die alte bleibt erhalten, erhält aber Fremdschlüssel. Alle angegebenen funktionalen Abängigkeiten sind volle. Die Relationen sind alle bereits in der 5NF. |
|
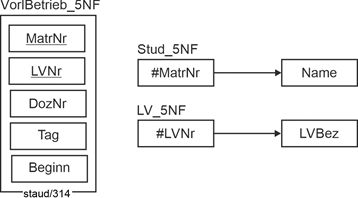
|
|
Abbildung 6.2-3: FA-Diagramme zu den Relationen Vorlesungsbetrieb (VorlBetrieb_5NF), Studierende (Stud_5NF) und Lehrveranstaltungen (LV_5NF). |
|
6.2.2 Definition |
|
Damit kann die 2NF wie folgt definiert werden: |
|
Eine Relation ist in zweiter Normalform (2NF), falls jedes Nichtschlüsselattribut voll funktional abhängig ist vom (gesamten) Schlüssel. |
|
Alternativ: ... falls kein (echtes) Schlüsselattribut Determinante für Nichtschlüsselattribute ist. |
|
Somit müssen in einer Relation mit 1NF und ohne 2NF einfache funktionale Abhängigkeiten bestehen. Werden diese beseitigt, beschreibt jedes Attribut dann das Objekt, das durch den Primärschlüssel identifiziert wird und nicht ein anderes, das durch einen Teil des Schlüssels identifiziert wird. Ist diese Bedingung erfüllt, können die oben angeführten Anomalien nicht auftreten. |
|
Was oben gezeigt wurde, gilt grundsätzlich. Relationen in 1NF, die nicht in 2NF sind, können in diese überführt werden. Dies erreicht man dadurch, dass die Attribute der Relation so in verschiedenen Relationen neu angeordnet werden, dass a) obige 2NF-Bedingung erfüllt ist und b) keine Information verloren geht. Etwas konkreter: Jedes Schlüsselattribut, das Determinante ist, wird Schlüssel einer neuen Relation. Ihr werden die von diesem Schlüssel funktional abhängigen Attribute zugeordnet. Die Determinante selbst bleibt in der 1NF-Relation, wird aber zum Fremdschlüssel. |
|
Vgl. die Beispiele in |
|
- https://www.staud.info/rm2/rm_t_1.php#Abschnitt10.3 und
- https://www.staud.info/r m2/rm_t_1.php#Abschnitt10.4
|
|
6.3 Dritte Normalform - 3NF |
|
6.3.1 Redundanz trotz 2NF |
|
Ganz abstrakt und auf das Wesentliche reduziert, drückt die folgende Abbildung das Problem bei Relationen aus, die nicht in 3NF sind: Es gibt eine Determinante, die nicht Schlüssel und nicht Schlüsselattribut ist (im ersten Beispiel D, im zweiten B). Da eine solche Determinante typischerweise mehrere gleiche Ausprägungen hat, wird die davon abhängige Attributsausprägung in C mehrfach erfasst. |
|
|
|
Abbildung 6.3-1: 2NF und nicht 3NF - abstrakt |
|
Solche "fortgesetzten" funktionalen Abhängigkeiten werden transitive genannt (vgl. unten). Relationen mit einem solchen Strukturmerkmal werden wie folgt normalisiert: |
|
Die Determinante, die nicht Schlüsselattribut ist, bildet zusammen mit dem von ihr abhängigen Attribut eine neue Relation. In der Ursprungsrelation muss diese Determinante (die nach der Normalisierung keine mehr ist) ebenfalls stehen bleiben. Dort wird sie zum Fremdschlüssel und sichert so den Zusammenhalt zwischen den Daten bzw. verhindert Datenverluste. |
|
Hierzu die obigen Relationen in 3NF: |
|
|
|
Abbildung 6.3-2: Relationen in 3NF - abstrakt |
|
6.3.2 Beispiel Auftragsköpfe |
|
Im vorigen Abschnitt ergab sich bei der Herbeiführung der 2NF u.a. die folgende Relation, die hier um ein Attribut und einige Tupel ergänzt wurde: |
|
AuftrKöpfe (#AuftrNr, AuftrDatum, KuNr, KuName, Ort) |
|
Einige beispielhafte Daten: |
|
AuftrKöpfe_2NF |
|
| #AuftrNr |
AuftrDatum |
KuNr |
KuName |
Ort |
| 0001 |
30.06.15 |
1700 |
Müller |
München |
| 0010 |
01.07.14 |
1201 |
Sammer |
Ravensburg |
| 0011 |
02.07.15 |
1600 |
Stanzl KG |
Berlin |
| 0012 |
04.07.16 |
1900 |
Max OHG |
Passau |
| 1001 |
19.05.14 |
1700 |
Müller |
München |
| 1010 |
20.03.15 |
1201 |
Sammer |
Ravensburg |
| 1011 |
05.09.15 |
1600 |
Stanzl KG |
Berlin |
| 1012 |
20.12.14 |
1900 |
Max OHG |
Passau |
| ... |
|
|
|
|
| |
AuftrNr: Auftragsnummer
AuftrDatum: Datum des Auftrags
KuNr: Kundennummer
KuName: Kundenname |
|
Sie hält Informationen zu Aufträgen fest, genauer zu den Auftragsköpfen, und zu den Kunden. Es gelten die folgenden funktionalen Abhängigkeiten: |
|
AuftrNr => AuftrDatum |
|
AuftrNr => KuName |
|
AuftrNr => KuNr |
|
AuftrNr => Ort |
|
KuNr => KuName |
|
KuNr => Ort |
|
Die Relation ist ohne Zweifel in 2NF. Die trotzdem noch vorliegende Redundanz kommt daher, dass dieselbe Kundennummer natürlich sehr oft vorkommen kann und für jedes Vorkommen der Kundennamen und der Wohnort des Kunden erfasst wird. Die Ursache liegt darin, dass ein Nichtschlüsselattribut (NSA), KuNr, Determinante ist und dass es "fortgesetzte" funktionale Abhängigkeiten gibt: |
|
AuftrNr => KuNr => KuName und |
|
AuftrNr => KuNr => Ort |
|
Die Bezeichnung transitive Abhängigkeit, erfolgt in Anlehnung an den entsprechenden Begriff der Mathematik. |
|
Zur Erinnerung (an die Schulalgebra): transitiv bedeutet eine Beziehung über ein anderes Element hinweg. A und B sind in (irgendeiner) transitiven Beziehung (bez), wenn für diese gilt. A bez C bez B. |
|
Sie wird so dargestellt: |
|
AuftrNr --> :: --> KuName |
|
AuftrNr --> :: --> Ort |
|
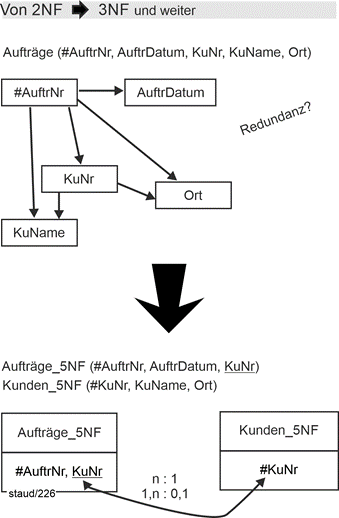
Um dieses Defizit beseitigen zu können, muss die Relation in zwei Relationen zerlegt werden. Die "NSA-Determinante" zusammen mit dem funktional abhängigen Attribut Ort ergibt die neue Relation Kunden_5NF. |
|
Kunden_5NF (#KuNr, KuName, Ort) |
|
Die "alte" Relation verliert das Attribut KuName und behält die ursprüngliche Determinante KuNr als Fremdschlüssel. |
|
Aufträge_5NF (#AuftrNr, AuftragsDatum, KuNr) |
|
Die folgende Abbildung zeigt den ganzen Normalisierungsschritt einschließlich des dabei entstehenden kleinen Modellfragments. |
|
|
|
Abbildung 6.3-3: Von 2NF zu 3NF - am Beispiel Aufträge / Kunden |
|
KuNr: Kundennummer
KuName: Name des Kunden |
|
6.3.3 Definition 3NF |
|
Hier nun die formale Fassung der oben eingeführten Definitionen. Zuerst die der transitiven Abhängigkeit: |
|
A, B und C seien Attribute einer Relation R. C heißt transitiv abhängig von A, in Zeichen: |
|
A --->::---> C, |
|
falls es ein Attribut B aus R gibt mit dem gilt: |
|
A => B => C (für A <> B <> C) |
|
Entsprechendes gilt für Attributkombinationen, wenn also für A, B oder C mehrere Attribute stehen. Liegen solche Strukturen nicht vor oder wurden sie beseitigt, ist eine Relation in dritter Normalform: |
|
Eine Relation ist in dritter Normalform (3NF), falls sie in 2NF ist und falls keine transitiven Abhängigkeiten zwischen dem Schlüssel und Nichtschlüsselattributen (NSA) bestehen (alternativ: ... falls kein NSA Determinante ist). |
|
Somit gilt: |
|
- in einer 3NF-Relation ist kein Nichtschlüsselattribut (NSA) transitiv von einem Schlüssel abhängig, d.h. jedes NSA beinhaltet eine Eigenschaft, die dem zugrundeliegenden Objekt als Ganzes zukommt.
- Eine Relation ist genau dann in 3NF, wenn alle NSA gegenseitig unabhängig und voll abhängig vom Schlüssel sind.
- "A relation R is in third normal form (3NF) if and only if, for all time, each tuple of R consists of a primary key value that identifies some entity, together with a set of zero or more mutually independent attribute values that describe the entity in some way" [Date 1990, S. 367].
|
|
Damit ist dann der Bezug auf ein Objekt im relationalen Sinn voll hergestellt. Im FA-Diagramm äußert sich dies so, dass Pfeile nur vom Schlüssel ausgehen. |
|
6.4 Boyce-Codd - Normalform - BCNF |
|
6.4.1 Redundanz trotz 3NF |
|
Schlüssel, die aus zwei oder mehr Attributen bestehen, kamen oben schon vor. Sie bedeuten immer, dass jedes der Attribute (z.B. PersNr und BezProj) einen Aspekt des erfassten Realweltphänomens (z.B. Projektmitarbei) identifizierend beschreibt und dass sie zusammen das Realweltphänomen selbst beschreiben ("wer in welchem Projekt"). |
|
Es kommt nun vor, wenn auch nicht oft, dass eine Relation überlappende Schlüssel hat. Dann besteht jeder Schlüssel aus mindestens zwei Attributen (z.B. #(A,B) und #(B,C)), die mindestens ein Attribut gemeinsam haben (hier B). Die folgende Abbildung zeigt, wie diese Situation in einem FA-Diagramm ausgedrückt wird. |
|

|
|
Abbildung 6.4-1: Redundanzen in der 3. Normalform - 3NF und nicht BCNF |
|
So weit so gut. Wenn dies von den Notwendigkeiten des Anwendungsbereichs gefordert ist, muss man so modellieren. Redundanzen entstehen, wenn es funktionale Abängigkeiten zwischen den Schlüsseln gibt, wenn also z.B. ein Attribut des einen Schlüssels von einem des anderen funktional abhängig ist. Dies ist dann auch umgekehrt der Fall, da beide ja als Schlüsselbestandteil für einen Teilaspekt des beschriebenen Phänomens identifizierenden Charakter haben. Die folgende Abbildung zeigt eine solche Situation. |
|
|
|
Abbildung 6.4-2: Redundanzen in der 3. Normalform - F.A. zwischen Schlüsselattributen |
|
Für jede Ausprägung von A gibt es eine entsprechende von C. Da in A eine bestimmte Ausprägung mehrfach vorkommt (Schlüsselbestandteil), kommt die zugehörige in B auch mehrfach vor. Diese Beziehung muss auch umgekehrt gelten, weil A und B in einer solchen Anordnung Schlüsselcharakter für Teilaspekte haben müssen. Diese Redundanz wird noch vergrößert, wenn Nichtschlüsselattribute (NSA) hinzukommen. Die folgende Abbildung zeigt dies am Beispiel eines einzelnen NSAs. |
|
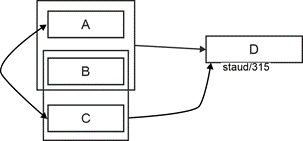
|
|
Abbildung 6.4-3: 3NF und nicht BCNF - abstrakt |
|
Erinnerung: NSA = Nichtschlüsselattribut |
|
Bei einer solchen Schlüsselkonstellation ist jedes NSA von zwei Schlüsseln abhängig. Für jedes mehrfache Auftreten einer Attributsausprägung in A bzw. C liegen auch mehrfache Einträge in D vor. Auch dies ist redundant, wenn auch von den bisherigen Schritten der Normalisierungstheorie nicht bedacht. |
|
2NF und 3NF erfüllt. Trotz dieser Defizite ist eine solche Relation in 2NF, denn es gibt keine funktionalen Abhängigkeiten von einem Schlüsselattribut zu einem NSA und auch in 3NF, da kein NSA Determinante ist. |
|
Die Lösung besteht darin, den Zusammenhang zwischen den beiden Attributen, der durch die gegenseitigen funktionalen Abängigkeiten ausgedrückt wird, in eine eigene Relation auszulagern. In unserem abstrakten Beispiel entsteht dadurch die Relation A-C. Da kommt jede Ausprägung des einen und des anderen Attributs nur einmal vor, der Zusammenhang wird nur einmal festgehalten. |
|
Die Semantik, die sich durch die funktionale Abhängigkeit zum NSA ausdrückte, wird durch eine neue Relation mit einem der "alten" zusammengesetzten Schlüssel (egal mit welchem) und dem NSA festgehalten. Im Beispiel entsteht dabei die Relation A-B. Das Attribut, das aus dem zusammengesetzten Schlüssel auch in der anderen Relation vorkommt, wird dort zum Fremdschlüssel und erlaubt damit die Verknüpfung mit der anderen entstehenden Relation. |
|
Endlich die BCNF |
|
|
|
Abbildung 6.4-4: Relationen A-C und A-B in BCNF - als FA-Diagramme |
|
Diese neuen Relationen sind dann in der Boyce-Codd - Normalform (BCNF), benannt nach ihren Entdeckern. Auch sie dient dem Zweck der Optimierung der relationalen Struktur, d.h. der optimierten Anordnung der Attribute in flachen Tabellen. |
|
Mit ihr werden Defizite beseitigt, die in Bezug auf die Coddsche dritte Normalform im Laufe der Jahre entdeckt wurden. Konkret waren dies Schwierigkeiten die auftreten, falls eine Relation mehrere zusammengesetzte (aus mehreren Attributen bestehende) und sich überlappende Schlüssel hat und zwischen einzelnen Schlüsselattributen funktionale Abhängigkeiten bestehen. Denn die 3NF verlangt nicht die volle funktionale Abhängigkeit eines Attributs vom Primärschlüssel, falls es selbst Attribut eines Schlüssels ist. |
|
6.4.2 Beispiel Projektmitarbeit |
|
Betrachten wir als Beispiel die folgende Relation zu Projektmitarbeit (ProjMitarb). |
|
ProjMitarb |
|
| AngName |
PersNr |
Funktion |
BezProj |
Zugeh |
| Stein |
12345 |
Leiter |
BPR |
24 |
| Maier |
12346 |
DV |
BPR |
18 |
| Müller |
23456 |
Leiter |
ITIL |
18 |
| Bach |
54321 |
InfMan |
ERP-Einf |
10 |
| Bach |
54321 |
DV |
Portal |
24 |
| Bach |
54321 |
InfMan |
SDK |
6 |
| ... |
|
|
|
|
| SA |
SA |
NSA |
SA |
NSA |
| |
Schlüssel: #(AngName, BezProj) oder #(PersNr, BezProj) |
|
Primärschlüssel sei #(AngName, ProjName) |
|
SA: Schlüsselattribut, NSA: Nichtschlüsselattribut |
|
Es gelte folgende Semantik: |
|
- Das Attribut AngName sei eindeutig(!). Es kann sich also nur um ein kleines Unternehmen handeln.
- Die Funktion beschreibt die Stellung der Angestellten (Leiter: Projektleiter, InfMan: Informationsmanager, DV: DV-Spezialist). Angestellte können in verschiedenen Projekten unterschiedliche Funktionen haben.
- BezProj ist die (eindeutige) Bezeichnung des Projekts (z.B. BPR: Business Process Reengineering)
- Zugeh erfasst die Dauer der Projektzugehörigkeit in Monaten.
|
|
Die textliche Notation: |
|
ProjMitarb (#(AngName, (BezProj), PersNr), Funktion Zugeh) //überlappender Schlüssel |
|
Zwischen den Attributen bestehen folgende vollen funktionalen Abhängigkeiten: |
|
(AngName, BezProj) => Funktion |
|
(AngName, BezProj) => Zugeh |
|
(PersonalNr, BezProj) => Funktion |
|
(PersonalNr, BezProj) => Zugeh |
|
AngName => PersNr |
|
PersNr => AngName |
|
Die folgende Abbildung zeigt im oberen Teil das FA-Diagramm. PersNr und AngName sind gegenseitig funktional abhängig. Die Relation ist in der 3NF, weil die Nichtschlüsselattribute voll funktional abhängig sind vom Schlüssel und weil es zwischen den NSAs keine weiteren vollen funktionalen Abhängigkeiten gibt. |
|
Vermischung |
|
Trotzdem weist diese Relation Redundanzen auf und vermischt Konzepte zweier Realweltphänomene, was zu den schon diskutierten Anomalien führt: Zum einen erfasst sie die Funktion und Projektzugehörigkeit der Personen, zum anderen erfasst sie, welche Personalnummer die Personen haben. Das Problem liegt hier also darin, dass die 1:1 - Beziehung zwischen den beiden Schlüsselattributen AngName und PersNr mehrfach erfasst wird. Z.B. dass Bach die Personalnummer 54321 hat. |
|
Diese Redundanz wird von der 3NF nicht beseitigt, da dort funktionale Abhängigkeiten zwischen Schlüsselattributen nicht betrachtet werden. Die Anomalien hier im einzelnen: |
|
- Einfüge-Anomalie: Dörrer wird neu eingestellt und erhält eine Personalnummer. Sie ist allerdings noch keinem Projekt zugeordnet. Ihre Daten können nicht erfasst werden (wegen der Forderung der Objektintegrität), da zum Schlüssel ja auch ein Projekt gehört.
- Lösche-Anomalie: Stein verlässt das Projekt "LCD", sein Datensatz wird gelöscht. Damit verschwindet auch die Information, welche Personalnummer er hat.
- Aktualisierungs-Anomalie: Bach erhält eine neue Personalnummer. Um diese Information in die Datenbank einzutragen, muss für jeden Eintrag "Bach/54321" die Änderung vorgenommen werden. Es wird also gegen die Regel verstoßen, dass jede in der Datenbank gespeicherte Information nur an einer Stelle stehen sollte.
|
|
Wieder besteht die Lösung in der Zerlegung der Relation. Zum einen in eine Relation ProjMitarb, zum anderen in eine Relation Angestellte (vgl. die Abbildung), die natürlich mit einer entsprechenden evtl. schon existierenden verschmelzen würde. |
|
Da die entstehenden Relationen die Probleme mit der 4NF und 5NF nicht aufweisen, sind die Ergebnisrelationen hier gleich in 5NF. |
|
|
|
Abbildung 6.4-5: Von 3NF zu BCNF - am Beispiel Projektmitarbeit |
|
Die Relationen:
ProjMitarb_3NF (#(AngName, (BezProj), PersNr), Funktion Zugeh)
ProjMitarb_5NF (#(BezPro, PersNr), Funktion Zugeh)
Angestellte_5NF (#AngName, #PersNr) |
|
Die Abbildung enthält im unteren Teil auch die FA-Diagramme der neuen Relation. Diese machen nochmals deutlich, dass die erreichte Normalform optimal (redundanzfrei) ist. Endgültig klärt dies wohl die tabellarische Darstellung. Die in den neuen Relationen überflüssigen Tupel wurden zur Verdeutlichung durchgestrichen stehen gelassen. |
|
Angestellte_5NF |
|
| #AngName |
#PersNr |
| Stein |
12345 |
| Maier |
12346 |
| Müller |
23456 |
| Bach |
54321 |
| Bach
|
54321
|
| Bach
|
54321
|
| ... |
|
| SA |
SA |
| |
Schlüssel: #AngName oder #PersNr) |
|
|
|
ProjMitarb |
|
| PersNr |
Funktion |
BezProj |
Zugeh |
| 12345 |
Leiter |
BPR |
24 |
| 12346 |
DV |
BPR |
18 |
| 23456 |
Leiter |
ITIL |
18 |
| 54321 |
InfMan |
ERP-Einf |
10 |
| 54321 |
DV |
Portal |
24 |
| 54321 |
InfMan |
SDK |
6 |
| � |
|
|
|
| SA |
NSA |
SA |
NSA |
| |
Schlüssel: #(PersNr, BezProj) |
|
6.4.3 Definition BCNF |
|
Relationen, die in der 3NF sind und kein oben beschriebenes Strukturdefizit aufweisen, befinden sich in der Boyce-Codd-Normalform (BCNF). Diese kann wie folgt definiert werden: |
|
Eine Relation ist in Boyce/Codd-Normalform (BCNF), falls jede Determinante Schlüssel ist (Primär- oder Sekundärschlüssel). |
|
Diese Definition umfasst auch die 2NF und die 3NF. Sie geht weiter, als die der 3NF, wo ja nur verhindert wird, dass ein NSA zur Determinante wird. Hier wird auch verhindert, dass ein SA, das nicht selbst Schlüssel ist, Determinante wird. Mit anderen Worten: Nimmt man diese Definition als Grundlage der Modellierungsbemühungen sind alle Normalformen einschließlich der BCNF realisiert. |
|
6.5 Weitere Normalformen |
|
4NF |
|
Die vierte Normalform betrifft Sonderfälle, die bei einem kompetenten Entwurf selten auftreten. Eine Beschreibung in deutsch findet sich hier: |
|
https://www.staud.info/rm2/rm_t_1.php#Kapitel13 |
|
5NF |
|
Dasselbe gilt für die 5NF, die ebenfalls in der Praxis kaum zu realisieren ist. Eine Beschreibung in deutsch findet sich hier: |
|
https://www.staud.info/rm2/rm_t_1.php#Kapitel14 |
|
7 Muster Einzel/Typ |
|
Vgl. für eine vertiefte Darstellung https://www.staud.info/rm2/rm_t_1.php#Abschnitt15.2 |
|
|
|
7.1 Das Konzept |
|
Der Begriff Einzel/Typ beschreibt den Gegensatz von einzelner Wahrnehmung irgendwelcher Phänomen und Wahrnehmung der Phänomene als Ganzes. |
|
Andere Bezeichnungen sind |
|
- Individuum/Typ
- Objekt/Typ
- Instanz/Klasse (in Anlehnung an die objektorientierte Theorie)
- Entity/Entity-Typ
- Einzelobjekt/Objektklasse
|
|
Dieses Muster taucht in vielen Anwendungsbereichen auf: |
|
- Einzeltier/Tiergattung
- Einzelgerät/Gerätetyp
- Komponente/Komponententyp
- Einzelperson/Gruppe
- Mitarbeiter/Abteilung
|
|
7.2 Umsetzung |
|
Oben wurde gezeigt, wie einzelne Objekte zu Objektklassen zusammengefasst werden. In einer Klasse sind dann Objekte, die genau dieselben Attribute besitzen. Diese werden dann in der Datenbank verwaltet. Jedes Attribut beschreibt somit alle einzelnen Objekte der Klasse, jedem Objekt kann eine Attributsausprägung zugewiesen werden. Nun gibt es aber Situationen in Anwendungsbereichen, wo der Klasse als Ganzes ebenfalls Attribute und Attributsauswertungen zugewiesen werden müssen. Insgesamt liegen dann Attribute für die Einzelobjekte und für die Objektklasse vor. |
|
In der objektorientierten Theorie wird dieses Muster durch die sog. Klassenattribute erfasst. Vgl. [Staud 2019, Abschnitt 2.3]. |
|
Dieses Muster - es wird hier Muster Einzel/Typ genannt - ist in den Anwendungsbereichen ständig präsent und muss dementsprechend auch in den Datenmodellen der Anwendungsbereiche umgesetzt werden. Leider wird es oft übersehen, was zu Redundanz in den Datenbeständen führt. Seine Grundlage ist also, dass es Objekte (aller Art) gibt, die sich sehr ähneln und die demzufolge gleiche Attribute haben (Tiere einer Gattung, technische Geräte eines Typs, Menschen einer Gruppe,...), bei denen aber auch gleichzeitig die Gattungen / Gerätetypen / Menschengruppen Attribute aufweisen. |
|
Je nach Anwendungsbereich und Objekttyp wird die Gesamtheit aller Objekte auf abstrakte Weise unterschiedlich benannt: Ganz allgemein und zurückgreifend auf die objektorientierte Theorie Klassen (Objektklassen). Falls es sich um Tiere handelt Gattungen, bei Geräten Typen (Gerätetypen), bei Menschen Gruppen, usw. |
|
Will man bei solchen Objekten die Informationen der einzelnen Objekte mit denen der Klasse ergänzen und fügt man diese einfach der Relation mit den Einzelinformationen hinzu, ist dies redundant. Einige Beispiele: |
|
- In einem Zoo werden evtl. die einzelnen Tiere (Schimpanse Eddi, Orang Utan Franz, Elefant Paul, ...) durch Attribute erfasst, zum anderen auch die Gattungen (Schimpansen, Orang Utans, Elefant der Gattung, ...). Natürlich nur für Großtiere, die als Individuen in Erscheinung treten.
- In der Technik wird in bestimmten Situationen das einzelne Stück erfasst (einzelne Kraftfahrzeuge, Festplatten, Flugzeugersatzteile, ...), zum anderen auch die gleichartigen Gruppen (Kraftfahrzeuge, Festplatten, Flugzeugersatzteile eines Typs, ...).
- Bei Menschen wird oftmals der einzelne Mensch erfasst (mit Personalnummern, Namen, usw.) und auch die Gruppe, zu der er gehört (Mitarbeiter IT, Leiharbeiter, Leitendes Management, ...).
|
|
Liegt eine solche Situation vor, gibt es drei Möglichkeiten: |
|
- In der Datenbank und damit im Datenmodell werden nur Attribute zu den einzelnen Objekten erfasst. Dann gibt es eine Relation zu diesen und alles ist in Ordnung. Das entspricht der Standardsituation.
- Es werden nur Attribute zur Klasse (Typ, Gattung, Gruppe) erfasst. Dann gibt es eine Relation zu diesen und die Sache ist ebenfalls geklärt. Lediglich bei einer eventuellen relationalen Verknüpfung mit einer anderen Relation muss aufgepasst werden. Vgl. dazu die Beispiele unten.
- Zu beidem, zu den einzelnen Objekten und zur Klasse sind Attribute zu erfassen. Dann müssen zwei Relationen angelegt werden (eine für die einzelnen Objekte, eine für die Klasse) und die Attribute müssen auf diese aufgeteilt werden. Attribute, die einzelne Objekte beschreiben, kommen in die Relation mit den Einzelinformationen. Beschreiben sie die Klasse als Ganzes, kommen sie in eine Relation mit den Typinformationen.
|
|
Es gibt also in der Datenbank u.U. einzelne Objekte, zum anderen aber auch die Zusammenfassung gleichartiger Objekte. Die Zusammenfassung wird hier einheitlich für alle im jeweiligen Bereich üblichen Bezeichnungen (Typ, Gattung, Gruppe, usw.) Typ genannt. Das Muster soll dann Muster Einzel/Typ genannt werden. |
|
Beispiel: Zootiere - einzeln und als Gattung |
|
Die folgende Abbildung zeigt das Muster in einem Anwendungsbereich, in dem es um Tiere geht, z.B. in einem Zoo. Die Tiergattungen des Zoos könnten aus Schimpansen, Orang Utans, Elefanten usw. bestehen. Für sie wird die Relation Tiere-Gattung mit den Attributen Bezeichnung (Bez), Anzahl der Mitglieder (Anzahl), einer Angabe zur Klassifikation (Klassif) und Hinweisen zur Art der Unterbringung (ArtUnt) erfasst. Für die einzelnen Tiere in der Relation Tiere-Einzeln gibt es eine Tiernummer (TNr), einen Namen (Name), den Geburtstag (GebTag), das Geschlecht und die Nummer des Gebäudes, in dem sie untergebracht sind (GebNr). Zur Verbindung der beiden Relationen wird die Gattungsbezeichnung (Gattung) in Tiere-Einzeln als Fremdschlüssel aufgenommen. Diese beiden Relationen beschreiben den Sachverhalt absolut redundanzfrei. |
|
|
|
Abbildung 7.2-1: Muster Einzel/Typ zu Zootieren |
|
8 Muster Gen/Spez |
|
Gen/Spez bedeutet Generalisierung/Spezialisierung
Mehr dazu in [Staud 2021, Abschnitt 14.1] und https://www.staud.info/rm2/rm_t_1.php#Abschnitt15.1 |
|
|
|
8.1 Das Konzept |
|
Basis sind auch hier wieder Objekte des Anwendungsbereichs. Bei der Generalisierung / Spezialisierung geht es um Ähnlichkeit von Objekten, gemessen an identischen und spezifischen Attributen. Die identischen Attribute sind: |
|
- Das Schlüsselattribut
- Mindestens ein deskriptives Attribut
|
|
Neben diesen gibt es bei den Objekten aber auch noch spezifische Attribute. Daraus entstehen Probleme bei der Erfassung, Speicherung und Auswertung der Daten (vgl. dazu unten die Beispiele), weshalb bei der Datenmodellierung angemessene Lösungen gefunden werden müssen. |
|
Die Generalisierung als Vorgang kann auch so gesehen werden, dass Objekte, die gemeinsame Attribute haben, zu einem übergeordneten Entitätstyp zusammengefasst werden. |
|
Umgekehrt kann Spezialisierung so gesehen werden, dass ein allgemeiner Entitätstyp in mehrere spezialisierte Untertypen zerlegt wird, die zusätzliche Attribute besitzen. |
|
In relationalen Datenbanken wird dieses Muster meist durch mehrere Relationen umgesetzt: |
|
- eine für die Generalisierung
- je eine für die Spezialisierungen, die denselben Schlüssel übernehmen.
|
|
8.2 Umsetzung |
|
Es gibt also Objekte in Anwendungsbereichen, die sich in vielen Attributen gleichen, in einigen aber nicht. Betrachten wir die Angestellten eines Unternehmens. Gemeinsam könnten sie die Attribute |
|
- Personalnummer (PersNr), Name, Vorname (VName), Abteilungsbezeichnung (AbtBez), Einstellungsdatum (EinstDat)
|
|
haben. Für die Softwareentwickler wären noch die Attribute |
|
- Entwicklungsumgebung (EntwU), Programmiersprache (ProgSpr) (jeweils nur eine, die meist genutzte)
|
|
denkbar. Für das leitende Management könnte noch das |
|
|
|
|
festgehalten werden. |
|
Wie bewältigt man ein solches Muster? Nimmt man alle Attribute zusammen in eine Relation, gibt es für Nicht-Entwickler und Nicht-Manager Attribute, die nicht belegt werden können ("semantisch bedingte Leereinträge", Das ist eine höchst unzulängliche Struktur in (attributbasierten) Dateien und Datenbanken. |
|
In der semantischen Modellierung und in der objektorientierten Theorie wurde deshalb für dieses Muster die sog. Generalisierung / Spezialisierung (Gen/Spez) entwickelt. Diese kann in der relationalen Theorie ebenfalls wie folgt umgesetzt werden: Für alle gemeinsamen Attribute wird eine eigene Relation angelegt, dies ist die sog. Generalisierung, und für die Attribute der jeweiligen spezialisierten Gruppen eine eigene, die Spezialisierungen. In unserem Beispiel entstehen damit folgende Relationen: |
|
Angestellte (#PersNr, Name, VName, AbtBez, EinstDat) |
|
Entwickler (#PersNr, EntwU, ProgSpr) |
|
TopManagement (#PersNr, Entgelt) |
|
Als Schlüssel wird jeweils PersNr genommen. Auf diese Weise erhält man Relationen, bei denen für jedes Objekt und jedes Attribut eine Attributsausprägung vorliegen kann, es braucht also keine semantisch bedingten Leereinträge geben. |
|
Ein abstraktes Beispiel |
|
Im folgenden Beispiel gehen wir von einer Standardsituation in Modellierungsprojekten aus: Mehrere Relationen liegen vor und plötzlich "entdeckt" man, dass sie gemeinsame Attribute haben. Betrachten wir die drei Relationen R1, R2 und R3 mit den angeführten Attributen: |
|
R1 (#A1, A2, A3, A4, A5) |
|
R2 (#A1, A2, A3, A6, A7, A8) |
|
R3 (#A1, A2, A3, A6, A9, A10) |
|
Offensichtlich haben die drei Relationen die Attribute A1, A2 und A3 gemeinsam, während ihre übrigen Attribute verschieden sind. In einem solchen Fall wird man die gemeinsamen Attribute in eine eigene Relation tun, die "oberste" Generalisierung. Sie soll R4 genannt werden. |
|
R4 (#A1, A2, A3) |
|
Das macht ein weiteres Motiv für die Gen/Spez deutlich: Ein bestimmtes Attribut soll nur einmal im Datenmodell und dann in der Datenbank auftauchen und nicht mehrfach. R4 stellt die Generalisierung der anderen drei Relationen dar. Diese behalten den Schlüssel, verlieren aber die übrigen gemeinsamen Attribute: |
|
R1 (#A1, A4, A5) |
|
R2 (#A1, A6, A7, A8) |
|
R3 (#A1, A6, A9, A10) |
|
Diese drei Relationen stellen damit Spezialisierungen dar. Grafisch lässt sich dieses Datenmodell wie in der folgenden Abbildung ausdrücken. Die grafische Notation für dieses Muster hat kein eigenes grafisches Element, wie dies bei Entity Relationship - Modellen (ERM) und in Klassendiagrammen der objektorientierten Theorie der Fall ist. Man erkennt sie nur daran, dass die Relationen denselben Schlüssel haben und an den Min-/Max-Angaben zwischen diesen. |
|
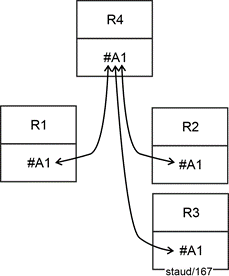
|
|
Abbildung 8.2-1: Generalisierung / Spezialisierung - Abstrakt |
|
Betrachtet man die textliche Fassung dieses Datenmodells genauer, bemerkt man, dass R2 und R3 ein weiteres Attribut gemeinsam haben, R6. Dies erfordert eine weitere Zerlegung. Das gemeinsame Attribut wird nach R5 ausgelagert. R5 ist dann Spezialisierung von R4 und Generalisierung von R2 und R3. Insgesamt gilt damit: |
|
Generalisierung aller Relationen, "oberste" Generalisierung: |
|
R4 (#A1, A2, A3) |
|
Spezialisierung von R4: |
|
R1 (#A1, A4, A5) |
|
Spezialisierung von R4, Generalisierung von R2 und R3: |
|
R5 (#A1, A6) |
|
Spezialisierungen von R5: |
|
R2 (#A1, A7, A8) |
|
R3 (#A1, A9, A10) |
|
Obige textliche Darstellung zeigt die Aufteilung der Attribute auf die Relationen. Die folgende Abbildung klärt den Zusammenhang zwischen den Relationen. Die evtl. nötige Verknüpfung erfolgt über die Primärschlüssel. Benötigt nun eine Anwendung oder Auswertung, die auf R2 fokussiert auch die Attribute von R5 und R4 bzw. deren Ausprägungen, kann sie sich diese durch die relationale Verknüpfung von den dortigen Relationen holen. Diese Technik nennt man in der objektorientierten Theorie Vererbung (die obere Relation "gibt" den "unteren" ihre Attribute im Bedarfsfall). Vgl. [Staud 2019, Abschnitt 6.6]. |
|
Die Primärschlüssel der Generalisierungen und Spezialisierungen stehen in folgendem Verhältnis zueinander: Die oberste Generalisierung enthält alle Schlüsselausprägungen. Jede ihrer Spezialisierungen enthält eine Teilmenge davon. Dies ist in der nächsten Abbildung auch durch die Wertigkeiten ausgedrückt. Die Kardinalität ist 1:1, die Min-/Max-Angaben sind 0,1 und 1,1 da nicht jedes Objekt der Generalisierung an einer bestimmten Spezialisierung teilnehmen muss, umgekehrt aber jedes Objekt der Spezialisierung verknüpft sein muss. Auch R5 als Generalisierung enthält alle Schlüsselausprägungen von R5, R3 und R2, die beiden letztgenannten aber nur Teilmengen von R5. |
|
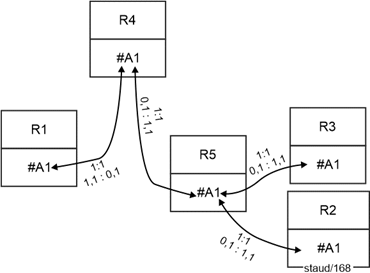
|
|
Abbildung 8.2-2: Generalisierung / Spezialisierung - Zweistufig und abstrakt |
|
Bleiben noch zwei Fragen: |
|
- Überlappen sich die Spezialisierungen (ist ihre Teilmenge nicht leer) oder tun sie es nicht (Überlappung).
- Decken die Spezialisierungen alle Ausprägungen der Generalisierung ab, ist also die Vereinigungsmenge der Spezialisierungen gleich der Generalisierung, oder ist sie es nicht (Überdeckung).
|
|
Beides muss bedacht und (bei Abfragen, Auswertungen) berücksichtigt werden, schlägt sich aber im Datenmodell nicht nieder. Eine Detailbetrachtung hierzu findet sich für die objektorientierte Modellierung in [Staud 2019, Abschnitt 6.4]. |
|
9 Muster Aggregation |
|
Mehr dazu in [Staud 2021, Abschnitt 14.3] sowie https://www.staud.info/rm2/rm_t_1.php#Abschnitt15.3 |
|
|
|
9.1 Das Konzept |
|
Hier geht es um das Muster, das in der semantischen Datenmodellierung und in der objektorientierten Theorie Aggregation genannt wird. Es drückt aus, dass ein Objekt in einem anderen enthalten ist. Es drückt nicht Existenzabhängigkeit aus, das ist Aufgabe der Komposition, die im nächsten Abschnitt beschrieben wird. |
|
Typisch für dieses Muster ist, dass die enthaltenen Teile eine eigene Existenz besitzen. Das kann auf zweierlei Weise modelliert werden. Entweder betrachtet man die Komponenten auf Typ-Ebene oder als individualisierte Komponenten. Die folgenden Beispiele rund um die Welt der PCs mögen dies verdeutlichen. |
|
9.2 Umsetzung |
|
Zuerst die Variante mit individualisierten Komponenten. |
|
Anwendungsbereich PC - Aggregation mit individualisierten Komponenten |
|
Hier soll es um Komponenten gehen, mit denen ein PC ausgestattet werden kann und die mit ihm fest, aber nicht untrennbar (vgl. dazu das Muster Komposition im nächsten Abschnitt) verbunden sind. Also z.B. Grafikkarten, interne Festplatten. Die Komponenten sind individualisiert, d.h. sie haben jeweils einen Schlüssel. |
|
Die folgende Abbildung zeigt das (kleine) Datenmodell. Es gibt eine Relation PC und eine PCKomp für die Komponenten. InvNr bedeutet jeweils Inventarnummer. Sind PC und Komponenten die Ausgangsrelationen, muss die Aggregation durch eine eigene Relation PCKomp ausgedrückt werden: |
|
PCKomp (#InvNrKomp, InvNrPC) |
|
Damit kann die Komponente in Komponenten auch "existieren�, falls sie nicht mehr in einen PC eingebaut ist. |
|
|
|
Abbildung 9.2-1: Muster Komposition mit individualisierten Komponenten |
|
PCComp hat eine auf den ersten Blick erstaunliche Struktur. Sie verbindet ja PCs mit ihren Komponenten, trotzdem hat das Attribut InvNrKomp alleine bereits Schlüsselcharakter. Dies kommt von der individualisierten Ebene. Jede Komponente ist über ihre Inventarnummer InvNrKomp einzigartig. |
|
Das Datenmodell zeigt auch die Besonderheit des Musters Aggregation: Es kann Komponenten geben, die keinem PC zugeordnet sind und PCs, die keine Komponente haben (was aber eher unwahrscheinlich ist). |
|
Dann die Variante für die Typ-Ebene. |
|
Anwendungsbereich PC - Komponenten auf Typebene |
|
Auch hier soll es wieder um die Ausstattung jedes einzelnen PCs mit Komponenten gehen, die Komponenten sollen aber nur über ihre Bezeichnung ("Grafikkarte xyz"), also auf Typebene, erfasst werden. Damit verändert sich die Relation zu den Komponenten: |
|
Komponenten-Typen (#BezKomp, Funktion) //BezKomp : Bezeichnung Komponente |
|
Dann ergibt sich die unten angegebene Lösung. Die Agregation wird durch die Relation PCKomp wie folgt ausgedrückt: |
|
PCKomp (#(InvNrPC, BezKomp)) |
|
Ein PC kann also mehrere Komponenten zugeordnet bekommen, eine Komponente ("Festplatte IBM 123") kann mehreren PCs zugeordnet werden. Diese Modellierung auf Typebene ist allerdings ungenau, da die konkrete Anzahl von Komponenten des gleichen Typs so nicht erkannbar ist. Sollte auch dies ausgedrückt werden, müßte die Anzahl (z.B. der "Typ-gleichen" Festplatten ) noch angegeben werden: |
|
PCKomp (#(InvNrPC, BezKomp), Anzahl) |
|
|
|
Abbildung 9.2-2: Muster Aggregation mit Komponenten auf Typebene |
|
|
|
10 Muster Komposition |
|
Mehr dazu in [Staud 2021, Abschnitt 14.4] und www.staud.info/rm1/rm_t_1.htm#Abschnitt15.4 |
|
|
|
10.1 Das Konzept |
|
Bei diesem Muster Komposition geht es auch um Enthaltensein, wie bei der Aggregation, allerdings sind die enthaltenen Teile untrennbar mit dem übergeordneten Teil verbunden. Zumindest datenbanktechnisch aber manchmal auch ganz real im Anwendungsbereich sind die enthaltenen Teile existenzabhängig vom "Ganzen": Wird ein "Ganzes" gelöscht, verschwinden auch die Komponenten. |
|
10.2 Umsetzung |
|
Am leichtesten kann man sich dies mit den Anwendungsbereichen Rechnungsstellung und Gebäude vorstellen: |
|
- Wird der Rechnungskopf gelöscht, verschwinden auch die Rechnungspositionen
- Wird das Gebäude aus der Datenbank genommen, z.B. weil es verkauft wurde, müssen auch die zugehörigen Büros herausgenommen werden (falls sie datenbanktechnisch erfasst waren).
|
|
Typisch für alle Varianten ist, dass der Schlüssel der übergeordneten Relation als Schlüsselattribut und Fremdschlüssel in die untergeordnete eingefügt wird. |
|
Anwendungsbereich Rechnungsstellung |
|
Das klassische Beispiel für dieses Muster ist die Beziehung zwischen Rechnungsköpfen (ReKöpfe) und Rechnungspositionen (RePos) der jeweiligen Rechnung. Sie gehören untrennbar zusammen und die Rechnungspositionen verschwinden auch, wenn die Rechnung aus der Datenbank gelöscht wird. |
|
Modelliert werden kann dies wie im folgenden Beispiel gezeigt. RePos erhält einen zusammengesetzten Schlüssel, bestehend aus Rechnungsnummer (ReNr) und Positionsnummer (PosNr). ReNr ist gleichzeitig auch Fremdschlüssel. |
|
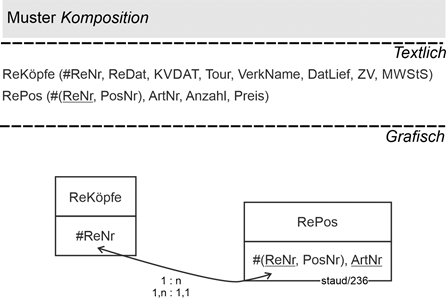
|
|
Abbildung 10.2-1: Muster Komposition im Anwendungsbereich Rechnungsstellung |
|
Der Fremdschlüssel RePos.ArtNr verweist auf die Notwendigkeit, in einem umfassenden Modell die Artikel mit dem Schlüssel ArtNr näher zu beschreiben. |
|
Anwendungsbereich PC |
|
Hier soll es um Komponenten gehen, die mit dem PC fest verbunden sind und mit ihm (normalerweise) zu existieren aufhören. Z.B. die WLAN-Komponente, das Kartenlesegerät, usw. Diese sind datenbanktechnisch existent, haben also eine eigene Beschreibung, ausgedrückt durch Attribute. Die Modellierung erfolgt so, dass der Schlüssel der übergeordneten Relation PC zum Fremdschlüssel in der untergeordneten Relation Komponenten wird. Da ein Tupel ohne Fremdschlüsseleintrag nicht existieren kann, verschwinden die Einträge in Komponenten, wenn der entsprechende PC ausgemustert wird. |
|
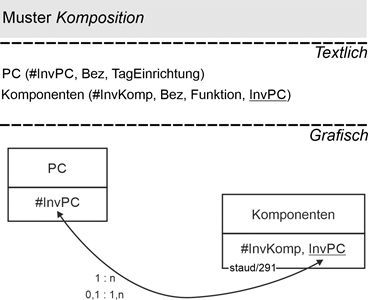
|
|
Abbildung 10.2-2: Muster Komposition im Anwendungsbereich PC |
|
11 Muster Beziehungsattribute |
|
|
|
11.1 Das Konzept |
|
In Kapitel 4 wurde gezeigt wie in relationalen Datenbanken einfache Beziehungen, das sind Beziehungen, mit denen Tupel verschiedener Relationen verknüpft werden, ins Datenmodell gebracht werden. Nun kommt es aber durchaus vor, dass solche Beziehungen selbst auch Eigenschaften (sprich: Attribute) haben. Hier wird gezeigt, wie dies in relationalen Datenbanken umgesetzt wird. |
|
Vgl. https://www.staud.info/Beziehungen/bz_t_1.php für eine umfassende Beschreibung von Beziehungen in Datenbanken. |
|
11.2 Umsetzung |
|
Die Lösung ist wie immer hier attributbasiert. Es gibt eine Relation, mit der die Verbindung hergestellt wird, eine Verbindungsrelation. Dieser Relation fügt man die Beziehungsattribute hinzu. Die Realisierung ist wie folgt: Eine Verbindungsrelation hat typischerweise einen zusammengesetzten Schlüssel, wobei jedes Schlüsselattribut auf eine zu verknüpfende Relation verweist ("n:m", vgl. Abschnitt 4.3). Zusätzlich zur einfachen Verknüpfung werden jetzt aber noch Attribute zur Beziehungsrelation hinzugefügt. Im einfachsten Fall mit zwei zu verknüpfenden Relationen ergibt sich dann: |
|
Beziehungsrelation (#(SA_1, SA_2), NSA_1, NSA_2, ...) |
|
SA: Schlüsselattribut, Teil des Schlüssels
NSA: Nichtschlüsselattribut |
|
D.h., die Attribute, durch die die Beziehung beschrieben wird, werden einfach an den zusammengesetzten Schlüssel angehängt. |
|
Zu beachten ist: Die Attribute, die hinzugefügt werden sollen, müssen die Beziehung beschreiben, nicht die beteiligten Partner, bzw. deren Relationen! |
|
Beispiel DBS und Händler |
|
Stellen wir uns eine Datenbank zu Datenbanksytemen (DBS) für Personal Computer vor. Eine Relation DBS beschreibt dann die Datenbanksysteme. Hier ganz einfach so: |
|
DBS (#BezDBS, Produzent, Typ) |
|
BezDBS: Bezeichnung des Datenbanksystems
Produzent: Unternehmen, von dem das Datenbanksystem progrmmiert und auf den Markt gebracht wurde.
Typ: Typ des Datenbanksystems |
|
Eine zweite Relation beschreibt die Händler, die Datenbanksysteme an die Endkunden verkaufen: |
|
Händler (#HaeNr, Bez, PLZ, Ort, Straße) |
|
HaeNr: Identifizierende Nummer für jeden Händler
Bez: Firmenname des Händlers
PLZ: Postleitzahl |
|
Die Beziehung beschreibt, welcher Händler welches Datenbanksystem anbietet, wobei wir hier von einer n:m-Beziehung ausgehen. Sie soll Angebot genannt und in eine gleichnamige Relation gepackt werden: |
|
Angebot (#(BezDBS, HaeNr)) |
|
Diese Fassung erfasst dann aber nur die Verknpüfung: Wer bietet welches System an? Typische Eigenschaften dieser Beziehung sind der Marktpreis (MPreis) und der gebotene Service (Service): |
|
- Marktpreis: Zu welchem Preis wird ein bestimmtes Datenbanksystem von einem bestimmten Händler angeboten?
- Service: Welchen Service bietet ein bestimmter Händler für ein bestimmtes Datenbanksystem?
|
|
Der korrekte Platz für diese zwei Attribute ist die Relation Angebot, die dann so aussieht: |
|
Angebot (#(BezDBS, HaeNr), MPreis, Service) |
|
MPreis: Marktpreis
Service: Service, der von Händlern angeboten wird |
|
Diese Beziehungsattribute beziehen sich tatsächlich auf die Beziehung (die Kombination DBS/Händler), nicht auf Händler oder Datenbanksysteme alleine. Wäre eine Preisangabe in der Relation DBS, wäre es ein Listenpreis, der für das Datenbanksystem vom Produzenten vorgeschlagen wird. Wäre Service in Händler, würde diese Angabe festhalten, welchen Serice der Händler unabhäng von einem konkreten Datenbanksystem bietet. |
|
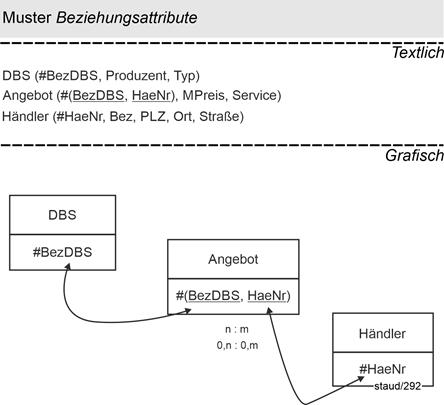
|
|
Abbildung 11.2-1: Muster Beziehungsattribute im Anwendungsbereich DBS |
|
Die Attribute Angebot.Mpreis und Angebot.Service bescheiben die Beziehung. |
|
12 Regeln für die Erstellung relationaler Datenmodelle |
|
Vgl. [Staud 2021, Abschnitt 13.3] und www.staud.info/rm1/rm_t_1.htm#Abschnitt14.3 |
|
Hier nun - kurz zusammengefasst - die aus dem obigen Text ableitbaren Regeln für die Erstellung relationaler Datenmodelle: |
|
- Jede Relation muss in 5NF sein. Dafür genügt meist ein Herbeiführen der 3NF und ein Prüfen, ob die BCNF erfüllt ist und ob keine mehrfachen mehrwertigen Attribute oder fehlerhafte Verbundabhängigkeiten vorliegen.
- Die Zerlegungen im Rahmen der Normalisierung dürfen zu keinem Informationsverlust führen. D.h., es ist immer darauf zu achten, dass durch relationale Verknüpfungen entlang von Schlüsseln und Fremdschlüsseln die in der Ausgangsrelation vorhandene Information erhalten bleibt.
- In jede Relation kommen nur die Attribute, die für alle Objekte Gültigkeit haben. Dies ergibt sich auch aus den Normalformen, soll aber nochmals deutlich gemacht werden. Es darf also keine semantisch bedingten Leereinträge geben. Ausnahmen sind Attribute zu Anfang und Ende bei zeitlichen Dimensionsangaben.
- Normalerweise gibt es keine unterschiedlichen Relationen mit identischem Schlüssel. Ausnahmen sind Relationen im Rahmen einer Generalisierung / Spezialisierung und große Relationen mit sehr lückenhaften Daten. Hier greift man u.U. ganz pragmatisch zu einer Aufteilung, damit die Leereinträge nicht vervielfacht werden. Ein Beispiel könnte eine Relation zu Datenbanksystemen sein, bei der man alle "kaufmännischen" Attribute hat, aber nur sehr wenige technische. Dann könnte in DBS-Kfm und DBS-Tech aufgeteilt werden.
|
|
Wird dies alles realisiert, ist auch eine zentrale Regel des Datenbankentwurfs umgesetzt: |
|
Jede (hier ja immer attributbasierte) Information darf in einer Datenbank nur einmal vorkommen. |
|
Da wir in den sog. SQL-Datenbanken, wie relationale Datenbanken neuerdings genannt werden, nur Attributsausprägungen von Objekten und Beziehungen abspeichern, ist die präzisere Formulierung folgende: |
|
Jede Attributsausprägung, die ein Objekt oder eine Beziehung beschreibt, darf in einer Datenbanken nur einmal erfasst werden. |
|
Klassisches Gegenbeispiel: Kunden, die mit aktuellen und früheren Adressen in der Datenbank erfasst sind. |
|
Bei den NoSQL-Datenbanken sieht es anders aus. Vgl. für einen Einblick https://www.staud.info/nosql2/no_t_1.php |
|
|
|
13 Beispiel: Rechnungen |
|
|
|
13.1 Anforderungsbeschreibung |
|
Vgl. das Vorwort zur Typographie. |
|
Es geht, stark vereinfacht, um die Verwaltung von Rechnungen von Kunden. Erfasst werden sollen die Rechnungen mit ihren Positionen und dem Rechnungsdatum (ReDatum). Außerdem die Artikel, die in den Rechnungspositionen auftauchen mit ihrer Anzahl. Für die Artikel werden eine Beschreibung, der Preis und der Standort der Ware im Lager erfasst. Für die Kunden werden Name, Vorname, Postleitzahl (PLZ), Ort, Straße und ein Festnetztelefonanschluss (FestTelefon) sowie ein Mobiltelefon (MobilTelefon) erfasst. Von einem Kunden werden maximal zwei Adressen in die Datenbank genommen. |
|
13.2 Lösungsschritte |
|
Relationen festlegen |
|
Sofort erkennbar als Relationen ("Identifikation + Beschreibung") sind Rechnungen, Artikel und Kunden. |
|
Für die Rechnungen wird eine Rechnungsnummer (ReNr) ergänzt und als Schlüsselattribut gewählt. Das Rechnungsdatum kommt hinzu (ReDatum). Bei den Positionen ergibt sich ein Problem. Wie wir wissen hat eine Rechnung typischerweise mehrere Positionen, auf denen die gekauften Artikel vermerkt sind - je einer pro Position. Also müssen die Positionen getrennt verwaltet werden. Wir teilen daher das Realweltphänomen Rechnung auf in Rechnungsköpfe (RechKöpfe) und Rechnungspositionen (RechPos). |
|
In die Relation RechKöpfe kommen erstmal die Attribute ReNr und ReDatum: |
|
RechKöpfe(#ReNr, ReDatum) |
|
Für die Rechnungspositionen (RechPos) führen wir eine Positionsnummer ein (PosNr). Dieses Ergänzen von Attributen ist zulässig und auch immer wieder notwendig. Auch die Artikelnummer des Artikels (ArtNr), der auf der Position auftaucht (immer nur einer, normalerweise), wird hinzugefügt. Er wird Fremdschlüssel und leistet die Verknüpfung mit der später zu erstellenden Relation zu Artikeln (vgl. unten). Hinzugefügt wird noch die Anzahl der Artikel in der Position. Die Artikelbeschreibung wird deshalb nicht einfach bei den Positionen angeführt, weil (hoffentlich) derselbe Artikel auf mehreren Positionen auftaucht, was dann zu Redundanzen und zu einem Verstoß gegen die 3NF führen würde. |
|
Erinnerung:
Schlüssel: identifizierendes Attribut bzw. identifizierende Attributskombination
Schlüsselattribut: Attribut eines Schlüssels
Nichtschlüsselattribut: die übrigen Attribute einer Relation
Fremdschlüssel: ein Attribut, das der relationalen Verknüpfung dient. Es ist in "seiner" Relation nicht Schlüssel, aber in der anderen zu verknüpfenden Relation.
Mehr dazu in [Staud 2021, Abschnitt 8.2] |
|
Bleibt noch der unabdingbare Schlüssel. Die Positionsnummer kann es nicht sein, denn diese wiederholt sich über die Rechnungen hinweg. Nehmen wir allerdings die Rechnungsnummer dazu, entsteht Eindeutigkeit. Die Kombination aus ReNr und PosNr ergibt den zusammengesetzten Schlüssel. Das darin enthaltene Attribut ReNr ist Fremdschlüssel, es leistet die Verknüpfung mit der Relation RechKöpfe: |
|
RechPos (#(ReNr, PosNr), ArtNr, Anzahl) |
|
Anmerkungen:
- Will man im Schlüssel auf die Positionsnummer verzichten, nimmt man stattdessen die Artikelnummer.
- Schlüssel sind unabdingbar. Wenn sie in den Anforderungen vergessen werden, sind sie zu ergänzen. |
|
Die Beziehung zwischen Rechungsköpfen und -positionen hat die Kardinalitä 1:n und die Min-/Max-Angaben 1,n : 1,1. Es liegt also Existenzabhängigkeit (eine Komposition) vor. |
|
Für die Kunden führen wir als Schlüssel eine Kundennummer ein (KuNr). Wir fügen Name und Vorname hinzu und ebenfalls den Mobilanschluss, denn dieser ist personenspezifisch, d.h. diese Information ist funktional abhängig vom Kunden, nicht von seiner Adresse. Damit ergibt sich: |
|
Kunden(#KuNr, Name, Vorname, MobilTelefon) |
|
Normalerweise würden wir hier die Adressattribute ergänzen. Da es aber nach der Anforderungsbeschreibung mehr als eine Adresse je Kunde geben kann, müssen die Adressangaben in einer eigenen Relation verwaltet werden (keine Mehrfacheinträge!). Wir legen wieder einen Schlüssel fest, eine Adressnummer (AdrNr): |
|
Adressen (#AdrNr, PLZ, Ort, Straße, FestTelefon) |
|
FestTelefon wurde zu den Adressen genommen, weil ein Festnetztelefon ortsspezifisch ist, d.h., dieses Attribut ist funktional abhängig von den Adressen. |
|
Als letztes sind noch die Artikel zu klären. Für sie werden in der Beschreibung eine Beschreibung, der Preis und der Standort der Ware im Lager (Standort) verlangt. Wir ergänzen noch den oben schon angelegten Schlüssel, Artikelnummer (ArtNr), und erhalten damit: |
|
Artikel (#ArtNr, Beschreibung, Preis, Standort) |
|
Insgesamt liegen damit folgende Relationen vor: |
|
Adressen (#AdrNr, PLZ, Ort, Straße, FestTelefon) |
|
Artikel (#ArtNr, Beschreibung, Preis, Standort) |
|
Kunden(#KuNr, Name, Vorname, MobilTelefon) |
|
RechKöpfe(#ReNr, ReDatum . . . |
|
RechPos (#(ReNr, PosNr), ArtNr, Anzahl) |
|
Restliche Verknüpfungen |
|
Eine wichtige relationale Verknüpfung wurde oben schon eingefügt, die Komposition zwischen Rechnungsköpfen und -positionen. Denn es gilt: Eine Rechnung hat mindestens eine Position und eine Position gehört zu genau einer Rechnung. Es liegt also eine 1:n-Beziehung zwischen Rechnungsköpfen und Rechnungspositionen vor. Der oben angelegte zusammengesetzte Schlüssel (ReNr, PosNr) drückt diese Existenzabhängigkeit aus, da durch den zusammengesetzten Schlüssel festgelegt wird, dass jede Rechnungsposition auch zu einem Rechnungskopf gehören muss (Komposition). |
|
Verknüpfungen sind oft nicht explizit in den Anforderungsbeschreibungen enthalten, sondern müssen aus der Semantik des Anwendungsbereichs oder von der Methodik abgeleitet werden. Hier z.B. für die Verknüpfung von Rechnungen und Kunden. Für diese gilt folgende Semantik: Jede Rechnung gehört zu genau einem Kunden. Ein Kunde kann mehrere Rechnungen haben. Eine solche 1:n-Verknüpfung zwischen Kunden und Rechnungen wird mit den Min-/Max-Angaben 0,n : 1,1 oder 1,n : 1,1 so umgesetzt: Die Kundennummer (KuNr) wird der Relation Rechnungsköpfe als Fremdschlüssel hinzugefügt: |
|
RechKöpfe(#ReNr, KuNr, ReDatum) |
|
Die Verknüpfung zwischen den Artikeln und Rechnungspositionen beruht ebenfalls auf einer 1:n-Verknüpfung: auf einer Rechnungsposition ist genau ein Artikel, ein Artikel kann auf mehreren Positionen auftreten. Die Min-/Max-Angaben (Artikel/Rechnungspositionen) sind entsprechend 0,n : 1,1. Dies wurde bereits oben durch Einfügen der Artikelnummer (ArtNr) in die Relation RechPos realisiert. ArtNr ist dort Fremdschlüssel. |
|
RechPos (#(ReNr, PosNr), ArtNr, Anzahl) |
|
Bleibt noch die Verbindung von Kunden und Adressen. Hier wird in der Anforderungsbeschreibung ausgeführt, dass jeder Kunde in der Datenbank zwei Adressen haben kann. Z.B. eine Liefer- und eine Rechnungsadresse. Dies wäre eine 1:n-Beziehung. Da wir aber gleich noch berücksichtigen, dass unter einer Adresse mehrere Kunden wohnen können, wird diese Beziehung zu einer n:m-Beziehung und bedarf einer eigenen Relation, einer Verbindungsrelation. Wenn wir festlegen, dass ein Kunde nur angelegt wird, wenn mindestens eine Adresse vorliegt und eine Adresse nur, wenn sie tatsächlich zu einem Kunden gehört, sind die Min-/Max-Angaben (Kunden/Adressen) 1,2 : 1,m. |
|
Dies führt zu einer Relation Kundenadressen (KuAdr). Sie hat den zusammengesetzten Schlüssel aus Adressnummer und Kundenummer: |
|
KuAdr (#(AdrNr, KuNr)) |
|
Restliche Prüfung |
|
Die gefundenen Relationen sind in der jeweils letzten Fassung vollständig. Es müssen keine weiteren Attribute ergänzt werden, wir können die Relationenbeschreibungen schließen. |
|
Sie sind auch alle bereits in der höchsten Normalform: Es gibt einen Schlüssel und weitere Attribute, die nur von diesem vollumfänglich funktional abhängig sind (BCNF). Probleme mit der 4NF und 5NF gibt es augenscheinlich nicht. Vgl. auch die FA-Diagramme unten. |
|
13.3 Lösung |
|
Damit ergibt sich folgendes Datenmodell. |
|
Textliche Notation |
|
Adressen(#AdrNr, PLZ, Ort, Straße, FestTelefon) |
|
Artikel (#ArtNr, Beschreibung, Preis, Standort) |
|
KuAdr (#(AdrNr, KuNr)) |
|
Kunden(#KuNr, Name, Vorname, MobilTelefon) |
|
RechKöpfe(#ReNr, ReDatum, KuNr) |
|
RechPos(#(PosNr, ReNr), ArtNr, Anzahl) |
|
Grafische Notation |
|
Die Frage, ob wirklich alle Verknüpfungen umgesetzt wurden, beantwortet sehr anschaulich die grafische Ausprägung des Datenmodells. |
|
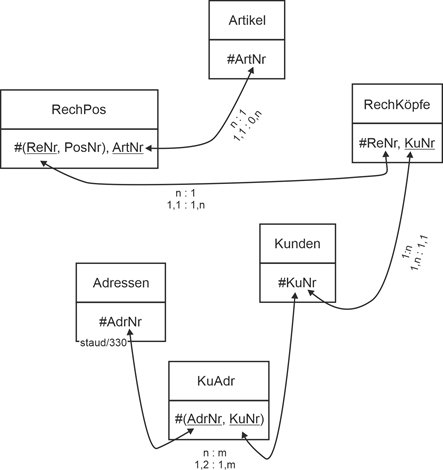
|
|
Abbildung 13.3-1: Relationales Datenmodell Rechnungen |
|
Oben wurden ja schon Fragmente von Datenmodellen in dieser grafischen Notation gezeigt. Hier nun ein ganzes (wenn auch kleines) Datenmodell. Wie oben schon ausgeführt, wird bei diesen grafischen Darstellungen für jede Relation ein Rechteck angelegt mit der Relationenbezeichnung in der oberen Hälfte und den Schlüsseln und Fremdschlüsseln in der unteren. Durch Pfeillinien werden die relationalen Verknüpfungen angegeben. Die Beschriftung der relationalen Verknüpfungen mit Kardinalitäten und Min-/Max-Angaben ist optional. |
|
13.4 FA - Diagramme |
|
Kurze Anmerkungen zu FA-Diagrammen sind hier oben, eine umfassende Einführung findet sich in [Staud 2021, Kapitel 8] und http://www.staud.info/rm1/rm_t_1.htm#Kapitel9 |
|
Die Betrachtung der funktionalen Abhängigkeiten der Relationen ist von großem Nutzen. Sie zeigen insbesondere auf, ob wirklich die höchste Normalform bei den Relationen erreicht wurde. |
|
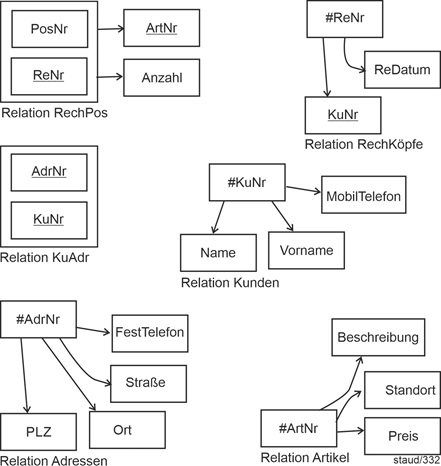
|
|
Abbildung 13.4-1: FA-Diagramme der Relationen zum Datenmodell Rechnungen. |
|
Die FD-Diagramme bestätigen, dass sich alle Relationen in der höchsten Normalform (BCNF) befinden. Jede Relation besitzt einen eindeutig definierten Schlüssel und jedes Nichtschlüsselattribut hängt vollständig und ausschließlich von diesem Schlüssel ab. Es bestehen keine transitiven oder mehrwertigen Abhängigkeiten mehr; ebenso sind keine offensichtlichen Verstöße gegen die vierte oder fünfte Normalform erkennbar. Damit ist die konzeptionelle und logische Entwurfsphase des Beispieldatenmodells abgeschlossen. |
|
14 Umsetzung mit mySQL |
|
Hier wird mySQL unter XAMPP verwendet. Um die Beispiele nachzuvollziehen muss man also XAMPP runterladen und dann Apache und MySQL starten: |
|
|
|
Damit ist es dann mit einem beliebigen Browser möglich, durch den Befehl |
|
http://localhost/phpmyadmin |
|
phpMyAdmin zu starten: |
|
|
|
Das SQL-Fenster wird im Weiteren benutzt. Das Verzeichnis in der linken Spalte zeigt die angelegten Datenbanken. Vgl. auch den Anhang. |
|
SQL und Groß-/Kleinschreibung |
|
SQL-Befehle sind nicht case-sensitiv. Das bedeutet, dass man Anweisungen in Groß-, Klein- oder Mischschreibung erstellen kann. Zum Beispiel funktionieren: |
|
SELECT * FROM customers; und select * from customers; genau gleich. |
|
Diese Regel gilt jedoch nur für SQL-Schlüsselwörter und Parameter, nicht für die eigentlichen Daten. Textwerte, die in Tabellen gespeichert sind - etwa Namen oder Adressen - werden so behandelt, wie sie eingegeben wurden. Daher werden "Smith" und "smith" als unterschiedliche Werte betrachtet. |
|
|
|
14.1 Aufgabe |
|
Die Aufgabe könnte wie folgt formuliert sein: |
|
- Erstellen Sie zu obigem Datenmodell die Datenbank mit SQL-Befehlen.
- Füllen Sie Demo-Daten ein, in denen die Verknüpfungen sichtbar werden.
- Führen Sie dann Auswertungen aus, auch über die relationalen Verknüpfungen.
|
|
14.2 Lösung |
|
Datenbank und Relationen einrichten |
|
Die Datenbank soll ReKu (Rechnungen/Kunden) genannt werden. Umlaute werden umgewandelt. Einige Attributsbezeichnungen wurden gekürzt. |
|
Beim Nachvollziehen aufpassen: Reihenfolge beachten! Bei Verknüpfungen zuerst die Relation mit dem Schlüssel, dann die mit dem Fremdschlüssel. |
|
Der folgende Befehl legt die Datenbank an: |
|
|
create database reku default character set latin1 collate latin1_german1_ci;
|
|
Zum Einrichten der eigenen Datenbank:
Obigen Befehl kopieren und ins SQL-Fenster eingeben. Go drücken. |
|
Nun die Relationen: |
|
Relation Kunden |
|
Kunden(#KuNr, Name, Vorname, MobilTelefon) |
|
|
create table kunden (KuNr smallint(5), name char(10), vorname char(10), mobil char(12), primary key (KuNr));
|
|
Zum Nachvollziehen:
Datenbank ReKu anwählen
Obigen Befehl per Copy/Paste ins SQL-Fenster und ausführen. |
|
Anzeige der Struktur der Relation. |
|
Die untenstehende Abbildung zeigt einen Teil der Tabelle, die mySQL zur Struktur der Relation ausgibt. Das Schlüsselsymbol in gelb (farbig nur in der Web-Version, nicht in den Print-Versionen) gibt einen Primärschlüssel an. Für diesen wird hier standardmäßig die BTREE-Architektur verwendet. |
|
|
|

|
|
Relation Artikel |
|
Artikel (#ArtNr, Beschreibung, Preis, Standort) |
|
|
create table artikel (ArtNr smallint(4), beschreibung varchar(10), preis decimal(7,2), standort char(5), primary key (ArtNr));
|
|
Zum Einrichten der eigenen Datenbank:
Obigen Befehl per Copy/Paste ins SQL-Fenster und ausführen. |
|
Anzeige der Relationenstruktur |
|
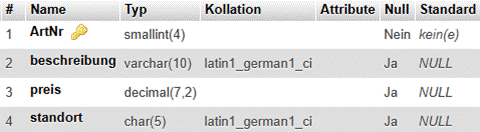
|
|

|
|
Relation Adressen |
|
Adressen(#AdrNr, PLZ, Ort, Straße, FestTelefon) |
|
|
create table adressen (AdrNr smallint(7), plz char(5), ort char(10), strasse char(10), FestTelefon char(15), primary key (adrnr));
|
|
Zum Einrichten der eigenen Datenbank:
Obigen Befehl per Copy/Paste ins SQL-Fenster und ausführen. |
|
Anzeige der Relationenstruktur |
|
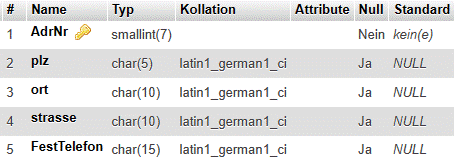
|
|

|
|
Relation RechKoepfe |
|
RechKöpfe(#ReNr, ReDatum, KuNr) |
|
|
create table RechKoepfe (ReNr smallint(6), KuNr smallint(5), primary key (ReNr), ReDatum date, foreign key (KuNr) references kunden(KuNr))
|
|
Zum Einrichten der eigenen Datenbank:
Obigen Befehl per Copy/Paste ins SQL-Fenster und ausführen. |
|
Anzeige der Relationenstruktur |
|
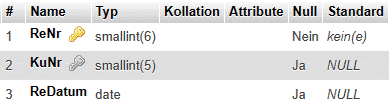
|
|

|
|
RechPos |
|
Relation RechPos |
|
RechPos(#(PosNr, ReNr), ArtNr, Anzahl) |
|
|
create table RechPos (ReNr smallint(6), PosNr tinyint(3) unsigned, ArtNr smallint(4), anzahl smallint(2),
|
|
|
primary key (ReNr, PosNr),
|
|
|
foreign key (ArtNr) references artikel(ArtNR),
|
|
|
foreign key (ReNr) references RechKoepfe(ReNr));
|
|
Zum Einrichten der eigenen Datenbank:
Obigen Befehl per Copy/Paste ins SQL-Fenster und ausführen. |
|
Anzeige der Relationenstruktur |
|
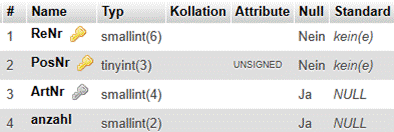
|
|

|
|
KuAdr |
|
Relation KuAdr |
|
KuAdr (#(AdrNr, KuNr)) |
|
|
create table KuAdr (AdrNr smallint(7), KuNr smallint(5),
|
|
|
primary key (adrnr, kunr),
|
|
|
foreign key (kunr) references kunden(kunr),
|
|
|
foreign key (adrnr) references adressen(adrnr));
|
|
Zum Einrichten der eigenen Datenbank:
Obigen Befehl per Copy/Paste ins SQL-Fenster und ausführen. |
|
Anzeige der Relationenstruktur |
|

|
|

|
|
14.3 Einfüllen von Daten |
|
Relation Kunden |
|
|
insert into kunden (KuNr, Name, Vorname) values (1007, 'Aberer', 'Anton');
|
|
|
insert into kunden (KuNr, Name, Vorname) values (1008, 'Blauer', 'Guiseppe');
|
|
|
insert into kunden (KuNr, Name, Vorname) values (1009, 'Cäser', 'Filippa');
|
|
|
insert into kunden values (1010, 'Dodolo', 'Rita', '1234567890');
|
|
|
insert into kunden values (1011, 'Steiner', 'Sepp', '2345678901');
|
|
Zum Nachvollziehen:
Obige Befehle per Copy/Paste ins SQL-Fenster und ausführen.
Falls wegen Fehlern Wiederholung nötig ist, vorab: delete from kunden; |
|
Damit ergibt sich folgende Relation: |
|
|
select * from kunden;
|
|
| #KuNr |
name |
vorname |
mobil |
| 1007 |
Aberer |
Anton |
NULL |
| 1008 |
Blauer |
Guiseppe |
NULL |
| 1009 |
Cäser |
Filippa |
NULL |
| 1010 |
Dodolo |
Rita |
1234567890 |
| 1011 |
Steiner |
Sepp |
2345678901 |
| |
Die Schlüsselmarkierung wurde und im Folgenden ergänzt. |
|
Der Weg zur Tabelle: Unter phpMyAdmin mit SQL den Befehl select * from kunden eingeben. Dann die Operation IN ZWISCHENABLAGE KOPIEREN durchführen. Diese in den Text einfügen. Das sieht dann im Kern so aus:
KuNr name vorname mobil
1007 Aberer Anton NULL
1008 Blauer Guiseppe NULL
1009 Cäser Filippa NULL
1010 Dodolo Rita 1234567890
1011 Steiner Sepp 2345678901
Mit der Textverarbeitung darüber eine Tabelle legen, formatieren, letzte Spalte löschen, Raute beim Schlüssel ergänzen und schon ist die Tabelle da. |
|
Relation Adressen |
|
|
Insert into adressen (AdrNr, plz, ort) values (1001, '88333', 'Waldhausen');
|
|
|
Insert into adressen (AdrNr, plz, ort, strasse) values (1011, '99333', 'Buchen', 'Am Baum 7');
|
|
|
Insert into adressen values (2011, '11111', 'Karlstadt', 'Hauptstr. 77', '111-2222');
|
|
Zum Nachvollziehen:
Obige Befehle per Copy/Paste ins SQL-Fenster und ausführen.
Falls wegen Fehlern Wiederholung nötig ist, vorab: delete from adressen; |
|
|
Select * from adressen;
|
|
| #AdrNr |
plz |
ort |
strasse |
FestTelefon |
| 1001 |
88333 |
Waldhausen |
NULL |
NULL |
| 1011 |
99333 |
Buchen |
Am Baum 7 |
NULL |
| 2011 |
11111 |
Karlstadt |
Hauptstr. |
111-2222 |
| |
Relation KuAdr
|
|
|
insert into KuAdr values (1001, 1007);
|
|
|
insert into KuAdr values (2011, 1007);
|
|
|
insert into KuAdr values (1001, 1008);
|
|
|
insert into KuAdr values (1011, 1009);
|
|
|
insert into KuAdr values (2011, 1010);
|
|
Zum Nachvollziehen:
Obige Befehle per Copy/Paste ins SQL-Fenster und ausführen.
Falls wegen Fehlern Wiederholung nötig ist, vorab: delete from kuadr; |
|
|
select * from KuAdr;
|
|
| AdrNr |
KuNr |
| 1001 |
1007 |
| 1001 |
1008 |
| 1011 |
1009 |
| 2011 |
1010 |
| 2011 |
1010 |
| |
#(AdrNr, KuNr) |
|
|
|
Exkurs: Klappt die Verknüpfung von kunden und adressen über kuadr? |
|
|
select k.KuNr, k.Name, k.Vorname, k.mobil, a.AdrNr, a.PLZ, a.Ort, a.Strasse
|
|
|
from kunden k, adressen a, kuadr v
|
|
|
where k.kunr=v.kunr and a.adrnr=v.adrnr
|
|
|
order by kunr;
|
|
Kunden und ihre Adressen |
|
| KuNr |
Name |
Vorname |
mobil |
AdrNr |
PLZ |
Ort |
Strasse |
| 1007 |
Aberer |
Anton |
NULL |
1001 |
88333 |
Waldhausen |
NULL |
| 1007 |
Aberer |
Anton |
NULL |
2011 |
11111 |
Karlstadt |
Hauptstr. |
| 1008 |
Blauer |
Guiseppe |
NULL |
1001 |
88333 |
Waldhausen |
NULL |
| 1009 |
Cäser |
Filippa |
NULL |
1011 |
99333 |
Buchen |
Am Baum 7 |
| 1010 |
Dodolo |
Rita |
1234567890 |
2011 |
11111 |
Karlstadt |
Hauptstr. |
| |
#(KuNr, AdrNr) |
|
Die Tabelle zeigt, dass es klappt. |
|
Ende Exkurs |
|
|
|
Relation Artikel |
|
|
insert into artikel values (100, 'Gamer-PC', 2500.00, 'ST007');
|
|
|
insert into artikel values (101, 'Büro-PC', 1200.00, 'ST018');
|
|
|
insert into artikel values (102, 'Entwickler-PC', 3200.00, 'ST100');
|
|
Zum Nachvollziehen:
Obige Befehle per Copy/Paste ins SQL-Fenster und ausführen.
Falls wegen Fehlern Wiederholung nötig ist, vorab: delete from artikel; |
|
|
select * from artikel;
|
|
| #ArtNr |
beschreibung |
preis |
standort |
| 100 |
Gamer-PC |
2500.00 |
ST007 |
| 101 |
Büro-PC |
1200.00 |
ST018 |
| 102 |
Entwickler |
3200.00 |
ST100 |
| |
Relation RechKoepfe
|
|
|
insert into rechkoepfe values (23001, 1007, '2023-03-27');
|
|
|
insert into rechkoepfe values (23010, 1009, '2023-05-20');
|
|
Zum Nachvollziehen:
Obige Befehle per Copy/Paste ins SQL-Fenster und ausführen.
Falls wegen Fehlern Wiederholung nötig ist, vorab: delete from rechkoepfe; |
|
|
select * from rechkoepfe;
|
|
| #ReNr |
KuNr |
ReDatum |
| 23001 |
1007 |
2023-03-27 |
| 23010 |
1009 |
2023-05-20 |
| |
Die Kennzeichnungen von Schlüssel und Fremdschlüssel wurden ergänzt. |
|
Relation RechPos
|
|
|
insert into rechpos values (23001, 1, 100, 1);
|
|
|
insert into rechpos values (23001, 2, 101, 2);
|
|
|
insert into rechpos values (23001, 3, 100, 1);
|
|
|
insert into rechpos values (23010, 1, 101, 3);
|
|
|
insert into rechpos values (23010, 2, 102, 1);
|
|
Zum Nachvollziehen:
Obige Befehle per Copy/Paste ins SQL-Fenster und ausführen.
Falls wegen Fehlern Wiederholung nötig ist, vorab: delete from rechpos; |
|
|
Select * from rechpos;
|
|
| ReNr |
PosNr |
ArtNr |
anzahl |
| 23001 |
1 |
100 |
1 |
| 23001 |
2 |
101 |
2 |
| 23001 |
3 |
100 |
1 |
| 23010 |
1 |
101 |
3 |
| 23010 |
2 |
102 |
1 |
| |
#(ReNr, PosNr) |
|
14.4 Beispielhafte Abfragen |
|
Aufgabe 1
|
|
Gib alle Rechnungen mit rechnungsrelevanten Daten aus. Ohne doppelte Attribute wg. Schlüssel/Fremdschlüssel. Die Sortierung soll aufsteigend nach Rechnungsnummer und Positionsnummer erfolgen. |
|
Lösung |
|
|
select rk.renr as ReNr, rk.kunr as KuNr, rk.redatum as ReDatum,
|
|
|
rp.posnr as Position, rp.artnr as ArtNr, rp.anzahl as Anzahl,
|
|
|
a.beschreibung as Beschreibung, a.preis as Preis
|
|
|
from rechkoepfe rk, rechpos rp, artikel a
|
|
|
where rk.renr=rp.renr and rp.artnr=a.artnr
|
|
|
order by rk.renr, rp.posnr;
|
|
|
|
| ReNr |
KuNr |
ReDatum |
Position |
ArtNr |
Anzahl |
Beschreibung |
Preis |
| 23001 |
1007 |
2023-03-27 |
1 |
100 |
1 |
Gamer-PC |
2500.00 |
| 23001 |
1007 |
2023-03-27 |
2 |
101 |
2 |
Büro-PC |
1200.00 |
| 23001 |
1007 |
2023-03-27 |
3 |
100 |
1 |
Gamer-PC |
2500.00 |
| 23010 |
1009 |
2023-05-20 |
1 |
101 |
3 |
Büro-PC |
1200.00 |
| 23010 |
1009 |
2023-05-20 |
2 |
102 |
1 |
Entwickler |
3200.00 |
| |
Frage zum Grundverständnis der relationalen Theorie: Mal angenommen, wir akzeptieren diese Tabelle als Relation. Ist sie in Ordnung? In welcher Normalform wäre sie? Welches ist der Schlüssel? Gibt es Anomalien, falls ja, welche? Was wird insgesamt durch sie beschrieben? Gerne können Sie mir Ihre Lösungen zur Einschätzung zusenden (hs@staud.info). |
|
Aufgabe 2 |
|
Erstelle eine Liste aller Kunden mit ihren Adressen ohne doppelte Attribute wg. Schlüssel/Fremdschlüssel. |
|
Lösung |
|
|
select k.kunr as KuNr, k.name as Name, k.vorname as Vorname,
|
|
|
k.mobil as MobilTel, a.plz as PLZ, a.ort as Ort, a.strasse as
|
|
|
Straße,a.festtelefon as Festnetz
|
|
|
from kunden k, adressen a, kuadr ka
|
|
|
where k.kunr=ka.kunr and ka.adrnr=a.adrnr;
|
|
| KuNr |
Name |
Vorname |
MobilTel |
PLZ |
Ort |
Straße |
Festnetz |
| 1007 |
Aberer |
Anton |
NULL |
88333 |
Waldhausen |
NULL |
NULL |
| 1008 |
Blauer |
Guiseppe |
NULL |
88333 |
Waldhausen |
NULL |
NULL |
| 1009 |
Cäser |
Filippa |
NULL |
99333 |
Buchen |
Am Baum 7 |
NULL |
| 1007 |
Aberer |
Anton |
NULL |
11111 |
Karlstadt |
Hauptstr. |
111-2222 |
| 1010 |
Dodolo |
Rita |
1234567890 |
11111 |
Karlstadt |
Hauptstr. |
111-2222 |
| |
15 Anhang - Informationen von mySQL zur Datenbank |
|
|
|
15.1 Das Datenmodell der Datenbank ReKu von mySQL |
|
Wählt man in der horizotalen Leiste am oberen Rand des Fensters die Schaltfläche Designer wird die folgende Abbildung ausgegeben. Sie gibt umfassende Auskunft über die beteiligten Relationen, ihre Attribute und Verknüpfungen. Außerdem werden zu allen Attributen die Datentypen angegeben. |
|
Dies kann in vielen Situationen sehr hilfreich sein, insbesondere bei der Fehlersuche. Z.B. wenn die Datenbanken von Schlüssel / Fremdschlüssel verschieden sind. |
|
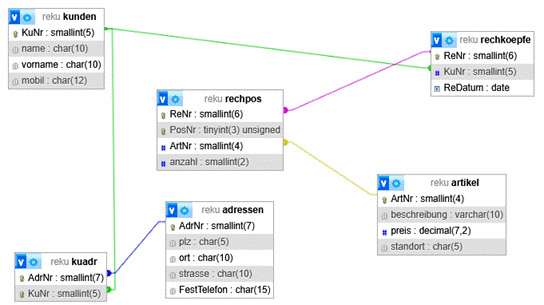
|
|
Abbildung 15.1-1: MySQL-Darstellung des relationalen Datenmodells Rechnungen |
|
|
|
|
|
Abbildung 15.1-2: MySQL-Darstellung des relationalen Datenmodells Rechnungen |
|
|
|
Abbildung 15.1-3: MySQL-Darstellung des relationalen Datenmodells Rechnungen |
|
Diese Abbildungen geben uns einen kleinen Eindruck von dem, was Data Dictionary genannt wird. Dieses enthält umfassende Informationen über alle Elemente der Datenbank und über ihren Aufbau. |
|
|