Semantische Datenmodellierung für effiziente Datenbanken: ERM, SERM, SAP-SERM. (in Arbeit, Stand 2022/02).
| |
©2021, 2022 Josef L. Staud |
|
Autor: Josef L. Staud |
|
Stand: Februar 2022 |
|
Umfang des gedruckten Textes: 194 Seiten |
|
Dieser Text richtet sich an meine Studierenden und die Teilnehmer meiner Seminare.
Geplanter Erscheinungstermin: 2022 |
|
Aufbereitung für’s Web |
|
Diese HTML-Seiten wurden mithilfe eines von mir erstellten Programms erzeugt: WebGenerator2 (Version 2021). Es setzt Texte in HTML-Seiten um und ist noch in der Entwicklung. Die „maschinelle“ Erstellung erlaubt es, nach jeder Änderung des Textes diesen unmittelbar neu in HTML-Seiten umzusetzen. Da es nicht möglich ist, nach jeder Neuerstellung alle Seiten zu prüfen, ist es durchaus möglich, dass irgendwo auf einer „abgelegenen“ Seite Fehler auftreten. Ich bitte dafür um Verzeihung und um Hinweise (hs@staud.info). |
|
Die Veröffentlichung im Web erfolgt ab 2022 in zwei Versionen: Mit und ohne Frame-Technologien. Zu meinem Bedauern wird die Frame-Technologie inzwischen von den Verantwortlichen als unerwünscht angesehen und es häufen sich die Hinweise, dass bestimmte Browser Frame-basierte Seiten nicht mehr korrekt interpretieren können. Deshalb habe ich eine zweite Version meines Programms WebGenerator erstellt, die ohne Frames realisiert ist. Sie ist derzeit (Februar 2022) in der ersten Version fertig, aber noch nicht perfekt („grüne Banane“). Das sollte sie aber im Laufe des Jahres 2022 werden. |
Frames? |
Urheberrecht |
|
Dieser Text ist urheberrechtlich geschützt. Die dadurch begründeten Rechte, insbesondere die der Übersetzung, des Nachdrucks, des Vortrags, der Entnahme von Abbildungen und Tabellen oder der Vervielfältigung auf anderen Wegen und der Speicherung in Datenverarbeitungsanlagen, bleiben, auch bei nur auszugsweiser Verwertung, vorbehalten. Eine Vervielfältigung dieses Textes oder von Teilen dieses Textes ist auch im Einzelfall nur in den Grenzen der gesetzlichen Bestimmungen des Urheberrechtsgesetzes der Bundesrepublik Deutschland vom 9. September 1965 in der jeweils geltenden Fassung zulässig. Sie ist grundsätzlich vergütungspflichtig. Zuwiderhandlungen unterliegen den Strafbestimmungen des Urheberrechtsgesetzes. |
|
Warenzeichen und Markenschutz |
|
Alle in diesem Text genannten Gebrauchsnamen, Handelsnamen, Marken, Produktnamen, usw. unterliegen warenzeichen-, marken- oder patentrechtlichem Schutz bzw. sind Warenzeichen oder eingetragene Warenzeichen der jeweiligen Inhaber. Die Wiedergabe solcher Namen und Bezeichnungen in diesem Text berechtigt auch ohne besondere Kennzeichnung nicht zu der Annahme, dass solche Namen im Sinne der Gesetzgebung zu Warenzeichen und Markenschutz als frei zu betrachten wären und daher von jedermann benutzt werden dürften. |
|
Prof. Dr. Josef L. Staud |
|
|
|
Abkürzungsverzeichnis |
|
| Abkürzung |
Langfassung |
| DBMS |
Datenbankmanagementsystem |
| DBS |
Datenbanksystem |
| ER-Modell |
Entity Relationship - Modell (- Modellierung) |
| SER-Modell |
Strukturiertes Entity Relationship - Modell |
| |
|
|
Vorwort |
|
Spricht man von Effizienz ("das Richtige tun") im Zusammenhang mit Datenbanken bedarf dies der Erläuterung. |
|
Datenbanken sind schon seit langem nicht mehr nur Informationsspeicher, die von Zeit zu Zeit abgefragt werden, sondern Werkzeuge für Aufgaben aller Art. Für die Planung der Geschäftstätigkeit, die Analyse von Märkten, von Kundenverhalten, von Marketingaktionen und vielem mehr. |
Werkzeuge |
Diese Werkzeuge funktionieren besser, sie erlauben eine höhere Effektivität, wenn sie auf einem qualitativ hochwertigen Design beruhen. Wenn also z.B. nicht vergessen wurde, alle semantisch wichtigen Strukturen zu erfassen. Dann erlauben sie, die „richtigen Dinge“ zu tun. Z.B. nicht nur die Durchführung einfacher Auswertungen, sondern tiefgehende Finanzanalysen nach dem neuesten Stand der Technik oder KI-gestützte Analysen. |
Effektivität |
Dann kann die Arbeit mit ihnen auch effizienter sein: Es ist dann möglich, die Dinge richtig und mit möglichst wenig Aufwand zu erledigen. |
Effizienz |
Der Weg zu effizienten Datenbanken mit der Aussicht auf Effektivität beginnt mit einem hochwertigen Datenbankdesign. Dabei gemachte Fehler führen zu erschwerten Abfragen, wenn die für die Abfrage notwendigen Strukturen nicht ausreichend vorgedacht und eingerichtet wurden. Zu Redundanz in den Daten, die Abfragen und Auswertungen schwieriger macht und letztendlich zu Widersprüchen in den Daten. Im Grenzfall werden durch solche Fehler sogar Abfragen unmöglich gemacht. |
Datenbankdesign |
Werden solche Fehler vermieden, ist die Datenbank von hoher Qualität. Dann ist die Arbeit mit ihr effizient und kann auch effektiv sein. |
Qualität |
Dieser Text soll bei der Erreichung dieses Ziels helfen. Denn am Anfang des Datenbankdesigns, gleich nach oder mit den konzeptionellen Überlegungen, folgt die semantische Datenmodellierung. Sozusagen die erste Fixierung der konzeptionellen Überlegungen in Richtung Datenbank. Noch ganz allgemein, noch ohne Ausrichtung an einer Datenbanktheorie. |
Semantische Datenmodellierung |
Mit einer kompetenten semantischen Datenmodellierung leistet man einen wesentlichen Schritt für ein qualitativ hochwertiges Datenbankdesign und damit für eine effiziente Datenbank. |
|
|
|

|
|
|
|
|
|
1 Einleitung |
|
1.1 Grundstruktur |
|
Jede Modellierungstechnik für Datenbanken bildet Aspekte des zu modellierenden Anwendungsbereichs in ein Modell ab. In ein semantisches, logisches, objektorientiertes, usw. Die Technik der Entity Relationship - Modelle (ER-Modelle) gehört zu denen, die im Anwendungsbereich Objekte und Beziehungen zwischen diesen mit Hilfe von Attributen identifizieren und beschreiben. |
|
Für die Objekte wird bei dieser Methode auch in deutschen Texten der Begriff Entity (Entität), für Beziehungen der Begriff Relationship (Beziehung) gewählt. |
|
Wie bei diesen Methoden üblich werden die einzelnen Entitäten und Beziehungen klassifiziert. Alle mit derselben Attributausstattung werden zu Typen zusammengefasst, wodurch Entitätstypen und Beziehungstypen entstehen. Aus diesen sind ER-Modelle aufgebaut. |
|
1.2 Mehr Semantik ins Datenmodell |
|
Entity Relationship - Modelle (ER-Modelle) sind Semantische Datenmodelle. Das Hauptziel bei deren Entwicklung war, mehr von der Semantik eines Anwendungsbereichs zu erfassen als in älteren oder näher an den Dateistrukturen befindlichen Modellierungsansätzen, weshalb die ganze Gruppe dieser datenbanktheoretischen Modellierungsansätze so genannt wird. |
Vgl. zum Begriff Semantik den nächsten Absatz |
Semantische Datenmodelle wurden vor allem in den 1970er Jahren entwickelt. Dies führte zu einer großen Zahl von Vorschlägen, von denen nur einer dauerhaft Bedeutung für die Datenbankpraxis erlangt hat, die Entity Relationship - Modellierung. |
|
Sie entstanden als Antwort auf die semantische Armut relationaler Datenmodelle. Die relationale Datenmodellierung ist im Kern reduziert auf attributbasierte Tabellen, die bestimmte Bedingungen erfüllen (sie werden dann Relationen genannt) und auf Verknüpfungen dieser Relationen durch Schlüssel/Fremdschlüssel. Vgl. [Staud 2021, Kapitel 5] für eine umfassende Einführung. Diese semantische Armut sollte durch die semantische Modellierung überwunden werden. |
Entstehung |
Zu dem Mehr an Semantik gehört die grundsätzliche Unterscheidung von Entitäten und Beziehungen, die in der relationalen Theorie durch ein gemeinsames Konzept (Relationen) erfasst werden. Außerdem die Erfassung zahlreicher semantischer Muster im Anwendungsbereich, z.B. Ähnlichkeit (Generalisierung / Spezialisierung), Enthaltensein (part_of, Teil_von), Existenzabhängigkeit (singuläre Entitätstypen), usw., die im übrigen danach auch in der objektorientierten Datenbanktechnologie Verwendung fanden. |
Mehr Semantik |
Abgrenzungen sollte man v.a. in zweierlei Hinsicht machen. Erstens zur objektorientierten Datenmodellierung. Die Modellierungstechnik ist hier eine ähnliche, wenn auch mit anderer Begrifflichkeit, z.B. Klasse statt Typ. V.a. aber kommen bei der objektorientierten Modellierung, sei es für Datenbanken oder Systeme, die sog. Methoden mit dazu. Damit werden die statischen Aspekte des Anwendungsbereichs, die durch Datenbanken erfasst werden, durch dynamische ergänzt. Für eine umfassende Einführung in die objektorientierte Modellierung mit der UML 2.5 vgl. [Staud 2019]. |
Abgrenzungen |
Die zweite Abgrenzung ist gegenüber den Datenbanken und ihren Modellierungstechniken notwendig, die nicht auf dem Attributsbegriff basieren. Diese gibt es schon sehr lange unter unterschiedlichen Bezeichnungen. Heute wird diese Thematik größtenteils unter der Bezeichnung NoSQL-Datenbanken behandelt. Vgl. für einen Überblick [Staud 2021, Kapitel 24]. |
|
1.3 Syntax, Semantik, Pragmatik |
|
Was genau ist mit dem bei dieser Modellierungstechnik eine große Rolle spielenden Begriff Semantik gemeint? |
|
Die im Datenbankkontext verwalteten Informationen werden i.d.R. durch Daten ausgedrückt, weshalb wir von diesem Begriff ausgehen. |
|
Solche Daten haben einen bestimmten Aufbau (Syntax), eine Bedeutung (Semantik) und dienen einem Zweck (Pragmatik): |
|
- Semantik meint hier im Datenbankkontext die Bedeutung, den Bedeutungsgehalt der Informationen, die über den Anwendungsbereich gewonnen wurden.
- Den korrekten Aufbau legt die sog. Syntax fest, die dafür die Regeln vorgibt.
- Mit Pragmatik ist der zielgerichtete Zweck gemeint, durch den Daten zu einer (eindeutig interpretierbaren) Information werden.
|
|
Betrachten wir einige Beispiele, zuerst Datumsangaben. Diese haben eine schlichte Struktur. Sie bestehen aus einer Tages-, einer Monats- und einer Jahresangabe. Z.B. könnte die Syntax folgenden Aufbau vorschreiben: 4. Mai 2021 oder auch 2021/05/04. Also z.B. dass die Tagesangabe aus einer maximal zweistelligen positiven Zahl besteht, die Monatsangabe ebenfalls (oder aus einer Zeichenfolge) und die Jahresangabe entweder ebenfalls als zweistellige oder als vierstellige positive Zahl erfasst wird. Damit legt die Syntax den korrekten Aufbau dieser Information schon etwas fest, würde aber auch den 31. April 2024 oder den 35. 12. 2022 zulassen. |
Datumsangaben: Tag, Monat, Jahr |
Dies unterbindet die Semantik, die zur weiteren Festlegung der Datumsangaben führt: |
|
- Tagesangaben liegen nur zwischen 1 und 31
- Monatsangaben nur zwischen 1 und 12
- Die Monate April, Juni, September, November haben maximal 30 Tage
- Der Monat Februar hat maximal 28 Tage mit Ausnahme der Schaltjahre
- Das Jahr 2004 ist ein Schaltjahr, der Februar hat also 29 Tage
- Das Jahr 2000 war ebenfalls ein Schaltjahr (die Schaltjahrregelungen sind recht kompliziert, so gibt es Schaltjahre, die nur in großem Abstand auftreten).
|
|
usw. |
|
Solche Festlegungen stellen also die Semantik der Datumsangaben dar. Genauer formuliert ist es so, dass die Realwelt (Datumsangaben) eine Semantik hat, die durch die Datumsangaben im Datenbestand möglichst genau erfasst werden soll. Dem Datenbanksystem liefert damit die Semantik weitere Regeln für die Korrektheit der Information. Dabei spricht man auch von Semantischen Integritätsbedingungen (englisch: constraints) . |
Semantik von Datumsangaben |
Noch präziser wird die Information durch die Pragmatik beschrieben. Eine Datumsangabe kann zum Beispiel einen Auftragseingang, ein Zahlungsziel oder den Abgabetermin für die Bachelorarbeit bedeuten. Das weiß die jeweilige Nutzerin und richtet ihr Verhalten daran aus. |
|
Betrachten wir ein weiteres Beispiel. Die Ausprägung einer Information sei die Zahl "19". Ein solches Datenelement kann verschiedene Bedeutungen haben: |
Beispiel
Zahl 19 |
- eine Hausnummer
- eine Uhrzeit
- ein Kalendertag
- die Nummer einer Buslinie
|
|
Die Semantik wird erst durch den Zusammenhang klar: |
|
- Steht 19 neben der Eingangstür an einer Hauswand, weiß man: Es ist die "Hausnummer 19".
- Steht 19:00 auf einer digitalen Armbanduhr, so weiß man: Es ist "7 Uhr abends".
- Steht 19 auf der Anzeige vorne in der S-Bahn, so weiß man: Es ist "die Linie 19".
|
|
In einer Hochschule könnten folgende Grundsätze unserer Daseins zur Semantik gehören und bei der Gestaltung einer Datenbank zum Lehrbetrieb wichtig sein: |
Beispiel
Lehrbetrieb |
- In einem Raum kann in einer Zeitspanne nur eine Veranstaltung stattfinden.
- Ein Dozent kann in einer Zeitspanne nur einen Kurs abhalten.
- Ein Dozent sollte pro Tag nicht mehr als 6 Stunden Vorlesungen und Übungen geben.
- Veranstaltungen, die das lokale PC-Netz zum Absturz bringen könnten (z.B. Programmierkurse) sollten nicht am Freitag Nachmittag stattfinden, da ab 13.00 Uhr die Rechenzentrumsmitarbeiter nicht mehr da sind, um einen evtl. Netzzusammenbruch "zu reparieren".
|
|
usw. Wenigstens ein kleiner Teil solcher Semantikaspekte kann in Datenmodellen erfasst werden. Allerdings wirklich nur ein kleiner, wie im Folgenden zu sehen sein wird, weshalb die diesbezüglichen Anstrengungen weitergehen. |
|
Woher kommt der Wunsch, möglichst viel Semantik des jeweiligen Weltausschnitts in einem Datenmodell und dann in der Datenbank zu erfassen? Nun, die Semantik gehört zur Anwendung. Sie muss auf jeden Fall berücksichtigt werden, soll die Anwendung leistungsstark sein. Entweder wird sie in der Datenbank hinterlegt oder in den Programmen softwaretechnisch realisiert (dann ist sie Gegenstand der Systemanalyse). |
Mehr Semantik in das Datenmodell |
Es geht natürlich nur um den Teil der Semantik, der für die jeweilige Anwendung bzw. für die Geschäftsprozesse, denen die Datenbank "dient", Bedeutung hat. |
|
Die Hinterlegung in der Datenbank, aufbauend auf der vorangehenden Berücksichtigung beim Datenbankentwurf, hat aber Vorteile: Sie ist sehr übersichtlich (z.B. als Semantische Integritätsbedingungen (constraints) auf den Relationen) und leicht änderbar. Man kann es auch so formulieren: Alle (zu berücksichtigende) Semantik, die nicht in der Datenbank hinterlegt wird, muss bei der Systemanalyse für die Anwendungsprogramme berücksichtigt werden. |
|
Fehlt noch die Pragmatik von Daten bzw. Informationen. Daten, die eine Bedeutung haben, sind immer noch keine (eindeutige) Information. Dazu fehlt der praktische Wert, den eine Angabe für den Empfänger der Information bekommt. Eine Datumsangabe zum Beispiel kann einen Auftragseingang, ein Zahlungsziel oder den Abgabetermin für die Bachelorarbeit bedeuten. Das weiß der jeweilige Nutzer. Daten und ihre Bedeutung müssen also über einen zielgerichteten, pragmatischen Zweck verfügen, um zu einer (eindeutig interpretierbaren) Information zu werden. Diesen Aspekt von Daten nennt man auch Pragmatik. |
Pragmatik |
1.4 Thematische Einordnung |
|
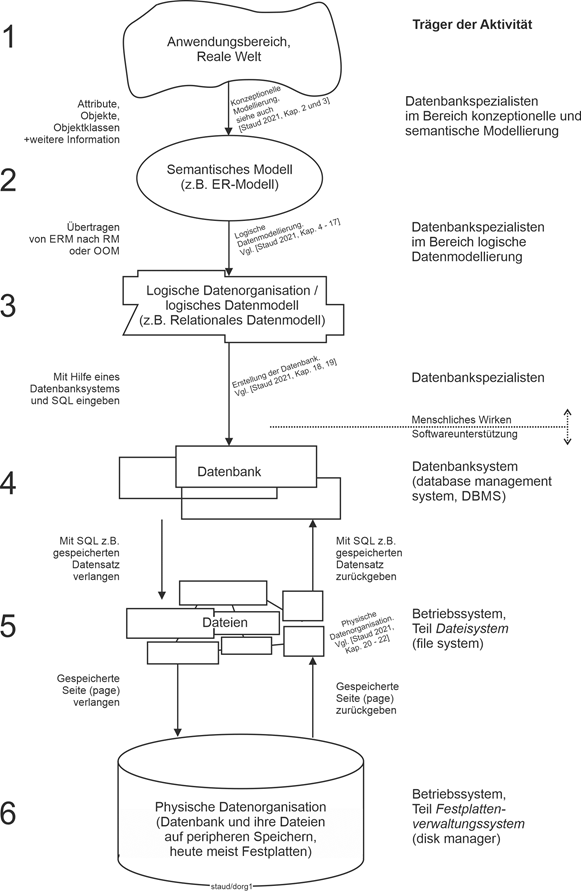
In diesem Text geht es um die aktuell bedeutsamen Ausprägungen der semantischen Datenmodellierung: ERM, S-ERM und SAP-SERM. Die Einbettung dieser Thematik in das Datenbankgeschehen kann anhand der folgenden Abbildung geklärt werden. Sie stammt aus [Staud 2021, S. 17] und zeigt den Gesamtweg eines Datenbankprojekts, von der Analyse des Anwendungsbereichs bis zu den Dateien der Datenbank. |
Inhalt und Einbettung |
Alles beginnt mit einem Anwendungsbereich, für den eine Datenbank zu erstellen ist. Sie ist in der Abbildung ganz oben als Wolke dargestellt (Position 1). Die Auseinandersetzung mit dem Anwendungsbereich, das Gewinnen der für die Datenbank wichtigen Informationen, wird konzeptionelle Modellierung (conceptual modeling) genannt. Mit ihrer Hilfe werden Objekte und Objektklassen (im umgangssprachlichen Sinn, nicht im Sinn der objektorientierten Theorie) erkannt, Attribute gefunden und zugeordnet sowie Beziehungen geklärt. |
Konzeptionelle Modellierung |
Die konzeptionelle Modellierung führt zu einem semantischen Datenmodell (Position 2). Mit einem solchen ist es möglich, Objekte, Beziehungen und Attribute unabhängig von einem konkreten Datenbanksystem und seinen Datenbanktechniken zu beschreiben. Von den vielen, die in den letzten Jahrzehnten hierfür vorgeschlagen wurden, blieb nur das sog. Entity Relationship - Modell (ER-Modell) übrig. Seine Aufgabe ist eine erste mit viel Aussagekraft erstellte Modellierung. Oder auch eine für Überblicksnotationen. |
Semantische Datenmodelle |
Genau hier ist dieser Text angesiedelt, wobei der Schwerpunkt auf dem klassischen ER-Ansatz nach Chen liegt, ergänzt um den Vorschlag von Sinz, ER-Modelle zu strukturieren (vgl. Kapitel 12) und die davon abgeleitete Variante der SAP (SAP-SERM; vgl. Kapitel 13). |
|
|
|
Abbildung 1.4-1: Der Weg vom Anwendungsbereich zur Datenbank und ihren Dateien. Quelle: [Staud 2021, S. 17]. |
|
Dass damit ein zwar wichtiger Schritt zur Datenbank geleistet wird, einige weitere aber noch fehlen, zeigt der Rest der Abbildung, der hier nur des Überblicks wegen skizziert werden soll. |
|
Im nächsten Schritt (Position 3) entsteht ein logisches Datenmodell. Damit werden Modelle bezeichnet, die einer bestimmten Datenbanktheorie und damit einem bestimmten Datenbanksystemtyp entsprechen. Dies sind heutzutage i.w. relationale und objektorientierte Datenbanksysteme und weitere, die neueren Ansätzen zur Datenverwaltung entsprechen (vgl. Kapitel 23 in [Staud 2021]). |
Logisches Datenmodell |
Vgl. [Staud 2021] für eine umfassende Einführung in die relationale Theorie und [Staud 2019] für eine umfassende Darstellung der objektorientierten Theorie mit Blick auf Unternehmensmodellierung. |
|
Mit der Erstellung des logischen Datenmodells ist die Struktur der künftigen Datenbank festgelegt. Also ein relationales Datenmodell oder auch ein objektorientiertes. Für diese Datenmodelle gibt es Datenbanksysteme, die mehr oder weniger gut das jeweilige Datenmodell (die jeweilige Theorie) unterstützen und seine Umsetzung erlauben. |
Datenbankdesign vollzogen |
Nun gilt es, aufbauend auf dem logischen Datenmodell, die konkrete Datenbank mit einem geeigneten Datenbanksystem einzurichten (Position 4). Dabei entstehen viele Dateien auf dem peripheren Speicher (heute meist Festplatten), in denen die Daten und die Verwaltungsinformation abgelegt sind (Position 5) . |
|
Auf der rechten Seite der folgenden Abbildung ist angegeben, wer die jeweilige Aktivität umsetzt. Von 1 nach 2 ist Kompetenz in den Bereichen konzeptionelle und semantische Modellierung nötig. Hier ist dieser Text angesiedelt. Geht es weiter nach 3, ist Kompetenz in logischer Datenmodellierung gefragt, heute also v.a. in relationaler oder in objektorientierter Modellierung. |
Träger der jeweiligen Aktivität |
Die nächsten Schritte bis zum physischen Speichermedium werden dann durch Anwendungssysteme realisiert. Durch das Datenbanksystem(database management system; DBMS; hier DBS) und das Betriebsssystem. Letzteres v.a. durch die in der Abbildung angeführten Komponenten Dateisystem (file system) und Festplattenverwaltungssystem (disk manager). |
Datenbanksystem – Betriebssystem |
1.5 Typographische Festlegung |
|
Um im Text die Übersichtlichkeit zu erhöhen, wird folgende typographische Festlegung getroffen: |
|
- Bezeichnungen von Anwendungsbereichen werden in normaler Größe, in Kapitälchen und in Arial gesetzt: Hochschule, Personalwesen, WebShop. In der Web-Version dieses Textes sind sie zusätzlich in roter Farbe gehalten.
- Bezeichnungen von Datenmodellen und Datenbanken sind fett in normaler Größe und in Arial gesetzt: Vertrieb, Zoo, WebShop, Datenbanksysteme (Markt für Datenbanksysteme). In der Web-Version zusätzlich in rot.
- Bezeichnungen von Entitäts- und Beziehungstypen sind etwas verkleinert und in Arial gesetzt: Angestellte, Abteilungen, Projekte. In der Web-Version zusätzlich in rot.
- Bezeichnungen von Attributen sind etwas verkleinert, fett und in Arial gesetzt: Gehalt, Name, Datum. Bei zusammengesetzten Benennungen wird der nachfolgende Begriff wieder groß begonnen: PersNr (Personalnummer), BezProj (Bezeichnung Projekt).
- Attributsausprägungen werden in normaler Größe und in Courier gesetzt.
|
|
|
|
|
|
2 Entitäten, Beziehungen, Attribute |
|
Methoden zur Erstellung eines Modells für eine Datenbank (Datenmodell) haben zum einen ein Theoriegebäude, das die Theorieelemente und ihren Zusammenhang festlegt, zum anderen auch eine grafische Darstellungstechnik (Notation). Beides wird hier im Folgenden ausführlich dargestellt. |
|
|
|
2.1 Grundlage |
|
Ganz am Anfang eines jeden Datenbankdesigns steht die Betrachtung des Anwendungsbereichs und des Zwecks, für den die Datenbank erstellt werden soll. Diese konzeptionelle Modellierung führt u.a. zur Identifikation der für die Datenbank . wichtigen Realweltphänome. Dabei werden, so der Stand der Technik, Objekte und Beziehungen unterschieden. Gleich strukturierte Objekte werden zu Objektklassen [Anmerkung] , gleich strukturierte Beziehungen zu Beziehungsklassen. |
Realweltphänomen |
In der US-amerikanischen Literatur wird für „Objekt“ der Begriff entity verwendet, was teilweise auch in der deutschsprachigen Literatur übernommen wurde. |
|
Exkurs Entity: |
|
Der Begriff „Entity“ wird nach seinem Gebrauch besser mit „Ding“ übersetzt, da die angelsächsischen Autoren ihn als allgemeinen Begriff für alles, was wahrgenommen wird, benutzen. Geeignet wäre auch – aus dem Modellierungsblickwinkel – Informationsträger. Denn alles, was wir für Datenbanken wahrnehmen, nehmen wir durch Informationen wahr. In der modelltechnischen Nutzung entspricht er aber am besten dem Begriff Objekt. |
|
Hier eine Zusammenstellung der Begrifflichkeit. |
|
| ER-Modellierung |
Konzeptionelle Modellierung |
Englische Begriffe |
| Entität |
Objekt |
entity |
| Entitätstyp |
Objektklasse |
entity type |
| Beziehung |
Beziehung |
relationship |
| Beziehungstyp |
Beziehungsklasse |
relationship type |
| Typ |
Klasse |
type |
| |
Attributbasierte Methoden
|
|
Da die ER-Modellierung zu den attributbasierten Modellierungsmethoden gehört, werden die Realweltphänomene mit Hilfe der gefundenen Attribute zu Entitäten und Beziehungen, bzw. zu Entitäts- und Beziehungstypen. Diese werden durch deskriptive Attribute weiter beschrieben. Mehr zu Attributen unten und in [Staud 2021, Abschnitt 2.4]. |
|
Zur Entität wird ein Realweltphänomen, wenn es mit Hilfe eines Attributs (oder mehrerer) identifiziert („Kundennummer“) und mit Hilfe weiterer beschrieben werden kann. |
Entitätsfindung |
Dies ist eine wichtige Grundlage des Modellierungsprozesses und sollte daher immer bedacht werden. |
|
Entitäten müssen also Attribute haben. In diesem Text werden lediglich aus didaktischen Gründen zu Beginn Entitätstypen ohne Attribute angeführt. Die Minimalausstattung ist ein identifizierendes (Schlüssel) und ein deskriptives Attribut. |
|
Beziehungen bestehen hier zwischen Entitätstypen dergestalt, dass für sie Entitäten der beteiligten Entitätstypen (zwei oder mehr) in eine inhaltliche (letztendlich attributbasierte) Verbindung gebracht werden. Die Konkretisierung der Beziehungen durch Attribute und Attributverknüpfungen (wie in der relationalen Modellierung; vgl. Kapitel 5 in [Staud 2021]) ist hier – in der semantischen Modellierung – nicht nötig. Sie wird es aber spätestens dann, wenn das ER-Modell in ein relationales oder objektorientiertes überführt wird. |
Beziehungsfindung |
2.2 Entitäten und Beziehungen |
|
Die Unterscheidung von Objekten und Beziehungen geschieht hier im Gegensatz zum relationalen Modell, wo beide – Entitäts- und Beziehungstypen – durch Relationen (also ein einziges Modellelement) dargestellt werden. Das Ziel dieser Trennung war und ist es, leichter die Abhängigkeiten zwischen den Daten zu erkennen [Chen 1976, S. 12f]. |
|
Wie in den meisten Modellierungstheorien für Datenbanken gibt es hier also die Unterscheidung der einzelnen Elemente (hier Entität genannt) und der zusammengehörenden gleichartigen Elemente, die hier Entitätstyp genannt werden. „Gleichartig“ bedeutet hier, dass die Entitäten dieselben Attribute aufweisen. Denselben Schlüssel und dieselben sonstigen Attribute. Ganz gleich für Beziehungen. Es gibt die einzelnen Beziehungen und die Beziehungstypen. Beispiele folgen gleich unten. |
Entität und Entitätstyp |
In der grafischen Notation werden Entitätstypen durch Rechtecke dargestellt. Hier z.B. die Entitätstypen Datenbanksysteme und Händler: |
|

|
Entitätstypen grafisch |

|
|
Abbildung 2.2-1: Entitätstypen – grafische Darstellung |
|
Sie stellen – datenbanktechnisch – die attributtechnisch gleich aufgebauten Entitäten „Datenbanksysteme“ bzw. „Händler von Datenbanksystemen“ dar, die jeweils zu Typen zusammengefasst wurden. |
|
Das zweite Grundelement dieses Ansatzes sind Beziehungen: Ein ER-Modell beschreibt einen Weltausschnitt als eine Menge von Entitäten/Entitätstypen, die durch Beziehungen/Beziehungstypen verknüpft sind. Für die Beziehungen gilt zu klären, welche Entitäten von welchen Entitätstypen in einer für den Anwendungsbereich bedeutsamen Beziehung stehen. Dies klingt einfacher als es ist, denn als Beziehung ist ja einiges denkbar. Die Aufgabe wird einfacher, wenn man die Attribute mit hinzunimmt, denn letztendlich sind auch hier (wie später in den relationalen Datenmodellen) die Beziehungen attributbasiert. Allerdings werden in den ER-Modellen diese (Beziehungs-)Attribute nicht ausgewiesen. |
Beziehungen |
Beispiele für Beziehungen, die in einem ER-Modell zur Rechnungsstellung auftauchen können, sind: |
|
- Rechnungsköpfe – Rechnungspositionen: Ein Rechnungskopf ist i.d.R. mit mehreren Rechnungspositionen semantisch verknüpft, eine Rechnungsposition mit einem Rechnungskopf.
- Kunden – Rechnungen (über Rechnungsköpfe): ein Kunde taucht auf mindestens einer Rechnung auf, eine Rechnung bezieht sich typischerweise auf einen Kunden.
- Rechnungspositionen – Artikel: Zu einer Rechnungsposition gehört ein Artikel, ein bestimmter Artikel kann sich auf vielen Rechnungspositionen wiederfinden.
|
|
Vgl. hierzu das Modellierungsbeispiel in Abschnitt 11.1 und die übrigen Beispiele in den Kapiteln 11 und 12. |
|
Ähnlich wie bei den Entitätstypen führt der Weg zu den Beziehungstypen über die Betrachtung der einzelnen Beziehungen: Gleich strukturierte Beziehungen werden zu Beziehungstypen zwischen Entitätstypen. Diese werden dann im ER-Modell ausgewiesen und grafisch mit den Entitätstypen verknüpft. |
Beziehungstypen |
Wie oben schon aussgeführt, sind Beziehungen in Entity Relationship - Modellen letztendlich auch attributbasiert, allerdings werden die (Beziehungs-)Attribute nicht ausgewiesen. Dies geschieht später, z.B. bei der Abbildung des ER-Modells in ein relationales. |
|
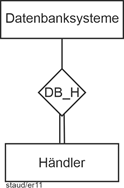
Die Beziehungstypen werden durch Rauten dargestellt. In unserem Beispiel könnte der Beziehungstyp DB_H (nach den Anfangsbuchstaben der Entitätstypen) erfasst werden, mit der festgehalten wird, welcher Händler welches Datenbanksystem zu verkaufen bereit ist: |
|

|
Beziehungstypen grafisch |
Abbildung 2.2-2: Beziehungstypen – grafische Darstellung |
|
DB_H: Datenbanken – Händler. Angebotsbeziehung. |
|
Die Beziehungen sind die zwischen einzelnen Datenbanksystemen und einzelnen Händlern, z.B. Händler X bietet ORACLE an. Alle solchen Beziehungen zusammen bilden den Beziehungstyp. In unserem Beispiel könnte damit das erste kleine Datenmodell angelegt werden: |
|

|
|
Abbildung 2.2-3: Ein erstes kleines Datenmodell Datenbanksysteme – Händler |
|
Es erfasst, wie gesagt, welcher Händler welches Datenbanksystem auf dem Markt anbietet. Halten wir fest, dass bisher nur die Entitäten und Entitätstypen als solche, ohne jegliche Identifikation und Beschreibung, erfasst worden sind. Dazu gleich mehr. |
|
Einzelne Entitäten und Beziehungen werden in ER-Modellen in der Regel nicht ausgewiesen. Nur die jeweiligen Entitäts- bzw. Beziehungstypen. |
|
2.3 Beziehungen präzisieren |
|
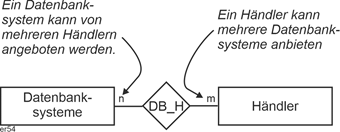
Wie in den meisten anderen Ansätzen zur Datenmodellierung werden auch hier die Beziehungen genauer festgelegt. Im ersten Schritt sollen hier 1:1-, 1:n- und n:m - Beziehungen unterschieden werden. Diese werden einfach bei den beiden beteiligten Entitätstypen vermerkt. Da es sich beim obigen Beispiel um eine n:m - Beziehung handelt, könnte diese so angegeben werden: |
|
|
|
Abbildung 2.3-1: n:m - Beziehung |
|
Die Bedeutung ist dieselbe wie in der relationalen Theorie: Ein Datenbanksystem kann, muss aber nicht, von mehreren Händlern angeboten werden, ein Händler kann, muss aber nicht, mehrere Datenbanksysteme anbieten. |
|
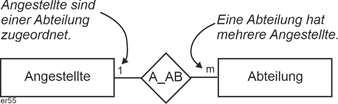
Ein Beispiel für eine 1:n - Beziehung ist Angestellte/Abteilung. Ein Angestellter ist einer Abteilung zugeordnet, eine Abteilung hat in der Regel mehrere Angestellte: |
|
|
|
Abbildung 2.3-2: 1:n - Beziehung |
|
Beispiele für 1:1 - Beziehungen folgen unten. |
|
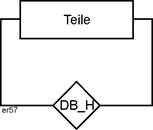
Der ER-Ansatz sieht auch Beziehungen eines Entitätstyps mit sich selber vor. Zwei Beispiele mögen dies verdeutlichen. Erstens das einer Stückliste, die z.B. wie folgt modelliert werden kann: |
Rekursive Beziehungen |
|
|
Abbildung 2.3-3: Rekusive Beziehung Stücklisten |
|
Der Entitätstyp Teile könnte z.B. alle Teile eines Fahrradtyps erfassen, der Beziehungstyp DB_H, welches Teil in einem andern enthalten ist (Enthaltensein). |
|
Ein weiteres Beispiel für eine rekursive Beziehung ist ein Vorgesetztenverhältnis. Z.B. in einem Unternehmen mit dem Entitätstyps Angestellte und dem Beziehungstyp ist_V („ist vorgesetzt“). |
|

|
|
Abbildung 2.3-4: Rekursive Beziehung Angestellte /Vorgesetzte |
|
Die Art der grafischen Anordnung der Raute (nach unten oder seitlich) hat dabei keine Bedeutung. |
|
Die Aussagekraft dieser Modellfragmente ist noch sehr beschränkt. Sie erhöht sich erst, wenn im folgenden Abschnitt Attribute eingeführt werden. |
|
2.4 Singuläre Entitätstypen |
|
Es gibt eine Gruppe von Entitäten, deren Existenz im jeweiligen Datenmodell davon abhängt, dass in einem anderen Entitätstyp eine bestimmte Entität vorliegt. Das in der Literatur meistgenannte Beispiel ist ein Entitätstyp Kinder in einem Datenmodell zu den Beschäftigten eines Unternehmens, zu dem auch ein Entitätstyp der Angestellten gehört. Hier gibt es in Kinder nur dann einen Eintrag, wenn Vater oder Mutter im Betrieb beschäftigt sind. Jeder Eintrag in Kinder ist also existentiell abhängig von den Einträgen in Angestellte. Verlassen die Eltern das Unternehmen, wird der Eintrag in Kinder gelöscht. |
Existenzabhängigkeit |
Ein zweites sehr typisches Beispiel sind die Auftragspositionen in einem Datenmodell Aufträge (vgl. die folgende Abbildung). Die Auftragspositionen hängen existentiell vom Auftragskopf ab. Wird ein bestimmter Auftragskopf gelöscht, müssen auch seine Auftragspositionen gelöscht werden. |
|
Dies ist nicht die normale Situation, bei der in einer Beziehung die Entitäten der beiden Entitätstypen unabhängig voneinander existieren. |
|
Solche „abhängigen“ Entitätstypen werden singuläre Entitätstypen und die zugehörigen Beziehungen singuläre Beziehungstypen genannt. In der grafischen Notation werden sie zusammen mit dem Beziehungstyp mit einer Doppellinie versehen: |
|

|
|
Abbildung 2.4-1: Existenzabhängigkeit – erfasst durch singuläre Entitätstypen. |
|
Vgl. Abbildung 11.1-1 für die Einbettung dieses Modellfragments in ein größeres ER-Modell. |
|
Existenzabhängigkeiten dieser Art sind wichtig, insbesondere wenn das Datenmodell zur Datenbank geworden ist und seine Alltagstauglichkeit beweisen muss. Deshalb spielen sie in einem anderen Modellierungsansatz eine prominente Rolle, der SERM (vgl. Kapitel 12). |
|
2.5 Attribute |
|
Wie auch in der relationalen Theorie (vgl. [Staud 2021, Kapitel 2] für eine umfassende Einführung) werden die Entitäten und Beziehungen in ER-Modellen durch Attribute beschrieben. Dabei werden hier aber verschiedene Arten von Attributen mit unterschiedlicher grafischer Notation unterschieden: |
|
- „Normale“ deskriptive Attribute, qualitativ oder quantitativ
- Schlüsselattribute
- Mehrwertige Attribute
- Abgeleitete Attribute
- Zusammengesetzte Attribute
|
|
In der grafischen Notation werden Attribute werden Attribute durch beschriftete Ellipsen dargestellt, die mittels einer Linie mit dem zugehörigen Entitäts- bzw. Beziehungstyp verbunden sind. |
|
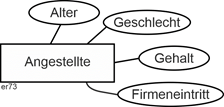
|
|
Abbildung 2.5-1: Deskriptive Attribute |
|
Deskriptive Attributedienen „nur“ der Beschreibung der Entitäten bzw. Beziehungen. Quantitative deskriptive Attribute haben die zusätzliche Eigenschaft, dass mit ihren Ausprägungen gerechnet werden kann. Im Beispiel der Abbildung sind Alter und Gehalt quantitativ, Geschlecht ist qualitativ, Firmeneintritt ist eine Datumsangabe. |
Deskriptive Attribute |
Auf die Unterscheidung von rangskalierten Attributen wie bei Merkmalen in der Statistischen Messtheorie) wird in der Datenbanktheorie verzichtet. |
|
In der folgenden Abbildung soll das Attribut Bez die Bezeichnung des Datenbanksystems, Nr eine identifizierende Nummer erfassen. Beide sollen eindeutig sein, nur dann sind sie als Schlüssel geeignet. Schlüsselattribute werden durch Unterstreichung gekennzeichnet. |
Schlüssel |
Für alle Kenner der relationalen Theorie: Nicht irritiert sein. In der relationalen Theorie werden Fremdschlüssel, die es hier gar nicht gibt, durch Unterstreichung gekennzeichnet. In ER-Modellen sind es die Schlüssel, die durch Unterstreichung kenntlich gemacht werden. |
|
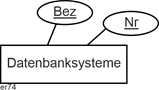
|
|
Abbildung 2.5-2: Konkurrierende Schlüssel |
|
Meist liegt nur ein einziges Schlüsselattribut vor. Sind es zwei oder mehr, wie im obigen Beispiel, kann auch von konkurrierenden Schlüsseln gesprochen werden. Bei konkurrierenden Schlüsseln identifiziert jeder Schlüssel alle Entitäten oder Beziehungen des Typs. |
Konkurrenz unter Schlüsseln |
Im Gegensatz dazu sprechen wir von einem zusammengesetzten Schlüssel, wenn mehrere Attribute zusammen den Schlüssel bilden. In der folgenden Abbildung genügt u.U. nicht die Angabe der Bezeichnung einer Vorlesung (z.B. Datenbanksysteme), sondern es muss auch noch das Semester angegeben werden (Datenbanksysteme / SS20), z.B. wenn es darum geht festzuhalten, wer in welchem Semester welche Vorlesung gehalten hat. |
Zusammengesetzter Schlüssel |
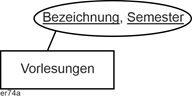
|
|
Abbildung 2.5-3: Zusammengesetzter Schlüssel |
|
Oftmals gibt es bei einem Attribut mehrere Ausprägungen in Bezug auf eine Entität. In der folgenden Abbildung z.B. mehrere (beherrschte) Programmiersprachen (ProgSpr) für einen Angestellten oder mehrere Projekte (identifiziert durch eine Projektnummer, ProjNr), in denen er oder sie mitarbeitet. |
|
Ein solches Attribut wird mehrwertig genannt und durch eine Doppellinie gekennzeichnet. |
|
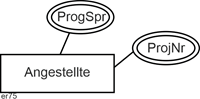
|
Mehrwertige Attribute |
Abbildung 2.5-4: Mehrwertige Attribute |
|
Mehrwertige Attribute können Probleme bereiten, beim Entwerfen und beim Betreiben der später entstehenden Datenbank. Sie sollten nur eingesetzt werden, wenn das durch das Attribut identifizierte Realweltphänomen (hier: Programmiersprachen und Projekte) nicht noch weiter beschrieben werden. Z.B. die Programmiersprachen durch die Bezeichnung des verwendeten Compilers („C++“ mit Visual Studio …) oder das Projekt durch den Projektleiter. Tritt solche eine Situation auf, muss zu anderen Modellstrukturen gegriffen werden. Vgl. dazu das nächste Kapitel. |
|
Abgeleitete Attribute sind solche, die nicht direkt erfasst, sondern aus anderen Attributen bestimmt werden. Z.B. könnte in einem Entitätstyp zu den Angestellten eines Unternehmens das Alter aus dem abgespeicherten Geburtsdatum (GebDat) und dem vom System gelieferten Tagesdatum bestimmt werden. Sie werden durch eine gestrichelte Linie kenntlich gemacht, wie unten beim Attribut Alter. |
Abgeleitete Attribute |
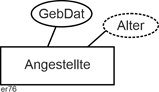
|
|
Abbildung 2.5-5: Abgeleitete Attribute |
|
Bei zusammengesetzten Attributen handelt es sich um solche, die zum Zweck der Erfassung in andere Attribute zerlegt werden können. Nehmen wir als Beispiel eine Namensangabe. Das Attribut Name kann zerlegt werden in die Attribute Vorname und Nachname. |
Zusammengesetzte Attribute |
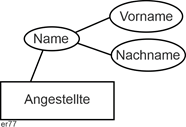
|
|
Abbildung 2.5-6: Zusammengesetzte Attribute |
|
Dies ist beliebig ausbaubar (akademische Grade, usw.). Eine solche „Verschachtelung“ kann auch mehrstufig sein, wie das Beispiel einer Adressangabe zeigt. |
|
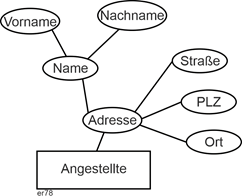
|
|
Abbildung 2.5-7: Zusammengesetzte Attribute – verschachtelt |
|
Zu beachten ist, dass bei zusammengesetzten Attributen nur die unterste Ebene tatsächlich aus Attributen besteht. Die übergeordneten (hier „Name“ und „Adresse“) sind lediglich Benennungen für inhaltlich zusammengehörige Gruppen von Attributen. |
|
2.6 Das erste ER-Modell |
|
Natürlich werden Attribute nicht isoliert, sondern mit ihrem zugehörigen Entitäts- bzw. Beziehungstyp erfasst, wie in den obigen Abbildungen ja schon angedeutet. |
|
Für ein Datenmodell entsteht dann eine Grafik wie in der folgenden Abbildung gezeigt. Dort werden die Datenbanksysteme durch ihre Bezeichnung (Bez) identifiziert, sowie durch die Angabe ihres Typs (Typ), der Liste ihrer Datentypen, der Liste ihrer Komponenten und ihren Listenpreis beschrieben. Die Händler werden durch den Firmennamen identifiziert (Firmenname) und durch ihre Adressangaben sowie durch ihre Verbindungsdaten beschrieben. |
Markt für Datenbanksysteme |
Der Beziehung wurde ebenfalls ein Attribut (Konditionen) zugewiesen. In ihm soll festgehalten werden, welche prozentualen Nachlässe der Händler bei den einzelnen Datenbanksystemen zu geben bereit ist. Da die Prozentsätze je nach Datenbanksystem verschieden sein können, kann dieses Attribut nicht beim Händler, sondern nur bei der Beziehung (Kombination Datenbanksystem/Händler) platziert werden. |
Attribut auf Beziehung |
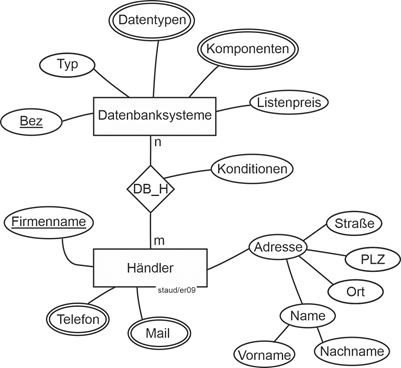
|
|
Abbildung 2.6-1: ER-Modell Markt für Datenbanksysteme |
|
Hinweise zum ER-Modell |
|
- Bez: Bezeichnung des Datenbanksystems
|
- Typ: Datenbanksystemtyp, also relational, objektorientiert, NoSQL-System, usw.
|
- Konditionen: Verkaufskonditionen. Hängen ab vom Datenbanksystem und vom Händler. D.h., ein Datenbanksystem hat bei verschiedenen Händlern unterschiedliche Konditionen und ein Händler hat für verschiedenen Datenbanksysteme auch unterschiedliche Konditionen. Diese sind also abhängig von der Kombination Händler/Datenbanksystem und müssen deshalb beim Beziehungstyp erfasst werden.
|
- Die Attribute Datentypen, Komponenten, Telefon, Mail sind mehrwertig. D.h., es gibt je Entität mehrere Attributsausprägungen.
|
Im Vorgriff auf Abschnitt 4.1 seien hier die sog. Kardinalitäten schon mal angesprochen. N und m bedeuten: Ein Händler bietet mehrere Datenbanksysteme an, ein Datenbanksystem wird von mehreren Händlern angeboten. Näheres dazu in Abschnitt 4.1. |
|
|
|
|
|
3 Entstehung von Entitätstypen – Zuordnung der Attribute |
|
|
|
3.1 Finden und Zuordnen |
|
Im Rahmen der semantischen Modellierung muss ständig die Frage beantwortet werden, welches Realweltphänomen ein Entitätstyp ist und welche Attribute diesem zugeordnet werden. Die Antwort gibt folgende Findungsregel für Entitätstypen: |
Findungsregel für Entitätstypen |
Alle Realweltphänomene, die durch ein Attribut (oder auch mehrere) identifiziert (Schlüssel!) und durch mindestens ein weiteres beschrieben werden, können als Entitätstypen angelegt werden. |
|
Beziehungstypen werden dagegen aus der Semantik des Anwendungsbereichs abgeleitet. |
|
In allen attributbasierten Modellierungsansätzen, dies sind insbesondere die Entity Relationship - Modellierung, die relationale Modellierung und die objektorientierte Datenmodellierung, gibt es das Problem der Zuordnung der zu modellierenden Attribute zu den Grundeinheiten (Entitäts-/Beziehungstypen, Relationen, Klassen). Dafür gibt es, in der Sprache der ER-Modellierung, folgende Regel: |
Zuordnungsregel |
Attribute werden dem Entitäts- oder Beziehungstyp zugeordnet, dessen Entitäten oder Beziehungen sie beschreiben. |
|
Und zwar umfassend: |
|
- Jedes Attribut muss für alle einzelnen Entitäten des Entitätstyps Gültigkeit haben. Entsprechend für Beziehungstypen. D.h., jedes Attribut muss auf alle Entitäten bzw. Beziehungen anwendbar sein.
|
|
Wie oben schon angemerkt gilt: Unter den Attributen eines Entitätstyps muss mindestens eines identifizierend sein. Der Schlüssel kann aber auch aus mehreren Attributen bestehen. Genügt also ein einziges Attribut nicht, um die Identifizierbarkeit zu realiseren, werden mehrere genommen. |
Schlüssel: ein Attribut oder mehrere |
Für die Beziehungstypen der ER-Modellierung sind Schlüssel nicht vorgesehen. Diese werden bei der Übernahme in ein logisches Datenmodell (z.B. ein relationales) aus den Attributen der beteiligten Entitätstypen abgeleitet. |
|
Nun noch eine Situation, die nicht zu Beginn eines Modellierungsprojektes, aber in dessen Verlauf sehr oft vorkommt: Stellen wir uns folgendes vor: Im Rahmen eines Modellierungsvorgangs ergibt sich ein Attribut A1, das beim ersten Hinsehen als beschreibendes Attribut eines Entitätstyps ET1 erscheint. Dann merkt man, dass es in Wirklichkeit ein eigenes Realweltphänomen identifiziert, das durch weitere Attribute beschrieben wird. In einem solchen Fall muss ein eigener Entitätstyp ET2 mit dem identifizierenden Attribut A1 oder einem konstruierten Schlüssel angelegt werden. Die dann in der Regel bestehende semantische Verbindung mit ET1 wird dann ebenfalls modelliert. |
Attribut oder Entitätstyp? |
Betrachten wir das Beispiel Sportverein in Abschnitt 11.5. Das Attribut Begegnung könnte ein Attribut bei Mannschaften sein. Hier liegen aber Attribute vor, die Begegnungen beschreiben (Ergebnis, Tagesdatum, Gegner, …), weshalb ein Entitätstyp Begegnungen angelegt werden muss. Als Schlüssel wurde hier ein zusammengesetzter gewählt: Tag/Beginn/Gegner. Das hinzugenommene Attribut Beginn erlaubt, mehrere Spiele einer Mannschaft an einem Tag zu erfassen. |
|
Hier – bei der Findung und Zuordnung – gemachte Fehler haben tiefe Wirkungen bis in die Ebene der Speicherung. Sie tragen zur sog. Stammdatenkrise bei. Diese Fragen werden deshalb im Folgenden, insbesondere auch bei den Modellierungsbeispielen, immer wieder thematisiert. |
|
3.2 Vom Attribut zum Entitätstyp |
|
Im Regelfall ist die Zuordnung der Attribute zu Entitäts- und Beziehungstypen problemlos. So wird das obige Attribut Konditionen dem Beziehungstyp DB_H („bietet an“) zugeordnet, weil es das Angebot spezifiziert und weil es nach Datenbanksystemen verschieden sein kann (nach Händlern sowieso). |
|
Was tun wir nun aber, wenn wir die Datentypen der Datenbanksysteme näher beschreiben wollen, z.B. durch Erfassung der konkreten Ausprägung: Dass bei einem bestimmten Datenbanksystem FLOAT4 den Wertebereich von xxx bis yyy hat, dass TEXT die Erfassung von Texten bis 90MByte erlaubt, dass MONEY auf einem Datentyp REAL mit zwei Stellen rechts vom Komma und vorgestelltem Währungszeichen beruht, usw. Nennen wir dieses Attribut DTSpez für „Spezifikation des Datentyps“. Wo gehört es hin in obigem kleinen Datenmodell? |
|
Hätte jedes Datenbanksystem nur einen Datentyp, wäre dies problemlos. DTSpez wäre einfach ein weiteres Attribut, das den Entitätstyp Datenbanksysteme beschreibt. Datentypen ist nun aber ein mehrwertiges Attribut, das eine Menge von Datentypen angibt, die vom jeweiligen Datenbanksystem zur Verfügung gestellt werden. Datentypen selbst hat zudem Schlüsselcharakter in Bezug auf die Datentypen (natürlich nicht für Datenbanksysteme). Damit ist nun genau die Situation gegeben, bei der das neue Attribut DTSpez dazu führt, dass ein neuer Entitätstyp Datentypen eingeführt werden muss. Diesem wird dann a) das alte identifizierende Attribut zugeordnet, b) das neue und c) eventuelle weitere, mit denen die Datentypen weiter beschrieben werden, z.B. Gruppe, wenn jeder Datentyp einer der Gruppen „numerische“, „alphanumerische“, „textliche“, „multimediale Datentypen“ zugeordnet werden soll. Damit könnte sich das folgende Modellfragment ergeben: |
Neuer Entitätstyp |
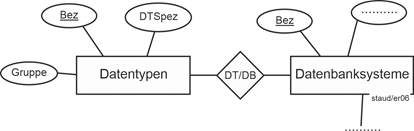
|
|
Abbildung 3.2-1: Zuordnung Attribute – Entitätstypen |
|
Datentypen: Entitätstyp für die erfassten Datentypen |
|
Datenbanksysteme: Entitätstyp für die erfassten Datenbanksysteme |
|
DT/DB: Beziehungstyp. Er erfasst, welche Datentypen in welchen Datenbanksystemen vorkommen. |
|
Die Punkte deuten jeweils die Ergänzungen des Datenmodells an. Grundsätzlich ist die oben angeführte Zuordnungsregel wichtig. Im obigen Beispiel war es so, dass DTSpez (die Spezifikation des Datentyps) nicht die Datenbanksysteme beschreibt, sondern die Datentypen. Genauso Gruppe (der Datentypen). |
|
Es muss also sehr genau darauf geachtet werden, dass jedes Attribut genau die Entitäten des jeweiligen Entitätstyps beschreibt. Hat man in der konzeptionellen Modellierung sauber gearbeitet („es werden die Entitäten/Beziehungen zusammengefasst, die durch dieselben Attribute beschrieben werden“), taucht das Problem an dieser Stelle nicht auf. |
|
Passiert es im Rahmen eines Modellierungsprozesses, dass diese Regel nicht mehr zutrifft (z.B. weil neue Entitäten zum Entitätstyp hinzugenommen wurden, die diese Regel verletzen), muss der Entitäts- oder Beziehungstyp aufgeteilt werden. |
|
3.3 Aufspaltung durch neue Attribute |
|
Ein Beispiel möge dies erläutern. In der folgenden Abbildung ist ein Entitätstyp Angestellte angegeben. Seine Entitäten werden durch das Attribut PersNr (Personalnummer) identifiziert und durch Name, Vorname und viele weitere (dies sollen die Punkte in der Attributsellipse andeuten) beschrieben. Die Linie an dem Entitätstyp soll andeuten, dass ein solcher Entitätstyp natürlich Teil eines größeren Datenmodells sein kann. |
|
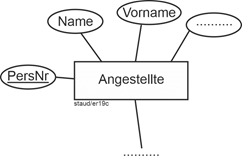
|
|
Abbildung 3.3-1: Entitätstyp Angestellte |
|
Diese Modellierung ist korrekt, solange keine Angestellten dazukommen, die spezifische Attribute benötigen. Geschieht dies, hier wurden zwei Attribute aufgenommen, die nur für die Programmierer unter den Angestellten Bedeutung haben (Programmiersprachenkompetenz (PSn) und Programmiererfahrung (ProgErf)), ergibt sich die in der folgenden Abbildung skizzierte Situation. Jetzt sind zwei Attribute vorhanden, die nur auf einen Teil der Entitäten anwendbar sind (die nur für einen Teil der Entitäten Gültigkeit haben). |
|
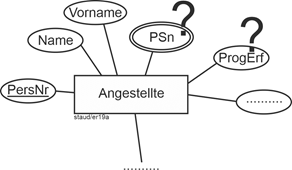
|
|
Abbildung 3.3-2: Entitätstyp Angestellte mit falscher Attributzuordnung |
|
Genau eine solche Situation soll die oben angeführte Regel verhindern. Der Grund ist einfach. Eine solche Attributanordnung führt schlussendlich zu Datenbeständen die – in der üblichen Grundform der sequentiellen Datei – lückenhaft sind. Lückenhaft nicht durch "noch" fehlende Daten, sondern durch falsche Attribut-/Entitätszuordnung [Anmerkung] . |
|
Korrigiert wird dies mittels einer Aufteilung des Entitätstypen in zwei verschiedene, die der Zuordnungsregel entsprechen. Hier somit (vgl. die folgende Abbildung) in die zwei Entitätstypen Programmierer und Sonstige Angestellte. |
|
Wer bei diesem Beispiel an die Generalisierung / Spezialisierung denkt, liegt genau richtig. Vgl. hierzu den nächsten Abschnitt. |
|
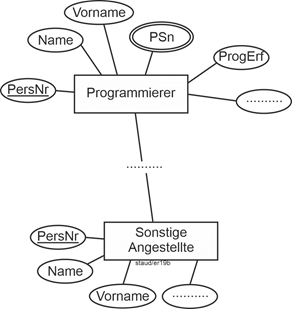
|
|
Abbildung 3.3-3: ER-Modell Angestellte – korrigiert |
|
3.4 Ein weiteres Beispiel |
|
Auch das folgende Modellfragment ist falsch. Hier wird Training als Entitätstyp beschrieben und durch Angabe des Tages sowie der Anfangs- und Endzeit erfasst. So weit so gut. Die Beschreibung durch die Adresse ist aber falsch, da die Adresse zum Trainingsort gehört und nicht zum Training als solches. |
|
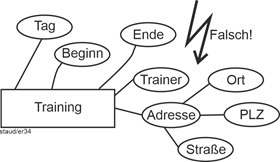
|
|
Abbildung 3.4-1: Fehlerhafte Attributzuordnung |
|
Richtig wäre also eine Aufteilung, wie in der folgenden Abbildung. Dadurch werden Training und Trainingsort getrennt. |
|
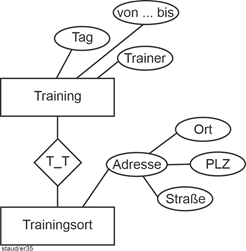
|
|
Abbildung 3.4-2: Training und Trainingsort getrennt |
|
Die Zuordnung der Attribute macht zu Beginn der Modellierung oft auch im Zusammenhang mit zusammengesetzten Attributen Schwierigkeiten (vgl. Abbildung 2.5-6 und 2.5-7). Diese werden dann mit einer unzulässigen Attributskombination verwechselt, nämlich damit, dass an ein Attribut weitere Attribute zur Fortsetzung der Beschreibung „gehängt“ werden. Dies ist unzulässig und bei zusammengesetzten Attributen auch nicht vorliegend. |
Fehlerquelle |
|
|
4 Beteiligungen – Kardinalitäten und Min-/ Max-Angaben |
|
Alle Modellierungsansätze, die Entitäten (Objekte) und Entitätstypen (Klassen) sowie Beziehungen und Beziehungstypen unterscheiden, müssen sich auch der Frage widmen, wie viele Entitäten (Objekte) jeweils an einer Beziehung teilhaben, denn dies wirkt bis in die Speichertechniken. Die hierzu in der ER-Modellierung vorgeschlagenen Modellelemente werden im Folgenden vorgestellt. |
|
|
|
4.1 Kardinalität einer Beziehung |
|
Mit der Kardinalität einer Beziehung ist gemeint, wie viele Entitäten des einen und des anderen Entitätstyps maximal in die entsprechende Beziehung einbezogen sind. Dabei wird zwischen 1 und mehrere (2 …) unterschieden, „mehrere“ wird in der Abbildung durch n oder m ausgedrückt. Die Kardinalitäten werden an der Verbindungslinie bei den Entitätstypen angefügt. Jeder Entitätstyp erhält die Kardinalität, mit der seine Entitäten an der Beziehung teilhaben. Insgesamt sind Beziehungen der Typen n:m, 1:n (oder m) und 1:1 möglich. |
n:m,
1:n (oder m)
und 1:1 |
- In obiger Abbildung 2.6-1 wurden die Kardinalitäten in die Abbildung eingefügt. N und m bedeuten da: Ein Händler bietet mehrere Datenbanksysteme an (m), ein Datenbanksystem wird von mehreren Händlern angeboten (n). Näheres dazu in Abschnitt 4.1. Dies wird n:m-Beziehung genannt.
- In obiger Abbildung 3.1-1 liegen ebenfalls die Kardinalitäten 1 und m (oder n) vor: Jeder ganz konkrete Datentyp gehört zu genau einem Datenbanksystem, jedes Datenbanksystem hat mehrere Datentypen. Würde man die Datentypen allgemein beschreiben, z.B. „Float“ und nicht die genaue Bezeichnung und Spezifikation des Herstellers wählen, z.B. „FLOAT(p) [UNSIGNED] [ZEROFILL]“ in MySQL, wäre diese eine n:m-Beziehung.
- In obiger Abbildung 3.3-2 (Training und Trainingsort): Ein Training findet an einem Trainingsort statt, an einem Trainingsort wird oft trainiert. Es würde also an der Verbindungslinie beim Trainingsort n (oder m) festgehalten, bei Training eine 1.
|
|
Im Beispiel der folgenden Abbildung wurde z.B. die technische Beschreibung der Datenbanksysteme (Datenbanksysteme / technische Information) getrennt von den Preisangaben (Datenbanksysteme / Preisinformation), z.B. weil die technische Information grundsätzlich für jedes erfasste Datenbanksystem erhoben wird, die preisliche aber nur für einige, die diesbezüglich besonders interessieren. Außerdem wurden die Produzenten der Systeme und die Datentypen aufgenommen. Es wird angenommen, dass jedes Datenbanksystem von genau einem Produzenten stammt. Dann gelten die in der Abbildung angegebenen Kardinalitäten. |
1:m-Beziehung |
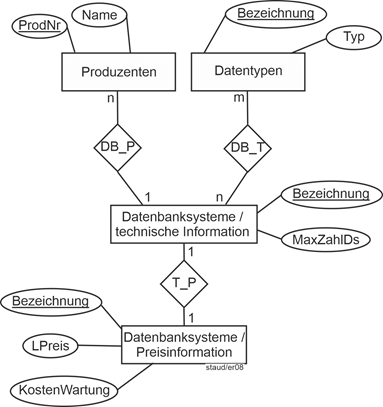
|
|
Abbildung 4.1-1: Kardinalitäten in Entity Relationship - Modellen, am Beispiel des Weltausschnitts Datenbanksysteme |
|
Entitätstyp DBS_P: Datenbanksysteme / Preisinformation |
|
Entitätstyp DBS_T: Datenbanksysteme / Technische Information |
|
LPreis: Listenpreis |
|
MaxZahlDs: Maximale Anzahl der Datensätze, die das Datenbanksystem verwalten kann |
|
Typ: Typ des Datentyps: numerisch, alphanumerisch, … |
|
Die Bedeutung dieser Kardinalitäten im einzelnen: |
|
- 1:1 zwischen Datenbanksysteme/technische Information und Datenbanksysteme / Preisinformation, weil es für eine technische eine preisliche und für eine preisliche eine technische Beschreibung geben kann.
|
|
Dieses Beispiel zeigt allerdings auch die Schwäche der Kardinalitäten. Die Tatsache, dass es zwar für jede preisliche Information eine technische gibt, aber nicht umgekehrt, wird durch die Kardinalitäten nicht erfasst. Dies leisten dann aber die Min-/Max-Angaben (vgl. unten). |
|
- n:1 zwischen Produzenten und Datenbanksysteme/technische Information, weil ein Datenbanksystem von einem Produzent stammt, dieser aber mehrere Systeme auf dem Markt anbieten kann.
- n:m zwischen Datentypen und Datenbanksysteme/technische Information, weil ein Datenbanksystem in der Regel mehrere Datentypen hat und ein Datentyp meist in verschiedenen Datenbanksystemen anzufinden ist (falls die Bezeichnung nicht herstellerspezifisch gewählt wird; vgl oben).
Die Kardinalitäten sind eine nicht sehr präzise Angabe. So ist zum einen nicht ersichtlich, ob eine Entität eines Entitätstyps überhaupt an der Beziehung teilhaben muss (vgl. auch die Anmerkung oben), zum anderen wird damit auch nicht angegeben, mit wieviel anderen Entitäten die Beziehung maximal erfolgt. |
|
|
4.2 Min-/Max-Angaben |
|
Dieses Defizit lösen die sog. Min-/Max-Angaben (Minimum/Maximum - Angaben). Mit ihnen wird festgehalten, wie viele Entitäten mindestens und wie viele höchstens an einer Beziehung teilhaben. |
|
Eine Min-/Max-Angabe besteht immer aus zwei durch ein Komma (bei einigen Autoren auch durch Punkte) getrennten Zahlen. Jede Beziehung hat zwei solche Angaben, die bei jeweils einem der beteiligten Entitätstypen stehen. Die zwei Werte halten dann fest, mit wie vielen Entitäten minimal (erster Wert) und maximal (zweiter Wert) die Entitätstypen an der Beziehung teilnehmen. |
Min, max |
Liegt bei Min-/Max-Angaben eine feste Unter- oder Obergrenze vor, werden diese angegeben, also z.B. 11,14 (vgl. unten). Liegt keine feste Obergrenze vor, wird n oder m genommen, als ganzzahlige positive Werte größer 1. |
|
In der folgenden Grafik, bei der Beziehung DT_DB, bedeutet z.B. 0,m beim Entitätstyp Datentypen, dass Datentypen auch erfasst werden, wenn noch kein Datenbanksystem bekannt ist, das einen solchen hat (z.B. für neue Datentypen). Der Wert m dagegen bedeutet, dass ein Datentyp in zahlreichen Datenbanksystemen vorhanden sein kann. Die Min-/Max-Angabe 1,m auf der anderen Seite der Beziehung bedeutet, dass gilt: Ein Datenbanksystem hat mindestens einen Datentyp, kann aber auch mehrere haben (was normalerweise der Fall ist). |
|
Zu beachten ist, dass der jeweils erste Wert einer Min-/Max-Angabe auch festlegt, ob eine Entität an einer Beziehung teilhaben muss oder nicht. Die oben eingeführte totale Beteiligung wird also, zumindest was die Beziehungen angeht, bei der Verwendung von Min-/Max-Angaben überflüssig. |
|
Die Festlegung des ersten Werts der Min-/Max-Angaben ist nicht so sehr Ausdruck der realen Semantik, sondern Ausdruck des Wollens der Modellierer. Der Wert 0 in der 0,m-Angabe der folgenden Abbildung sagt, dass in diese Datenbank eben auch Datentypen eingetragen werden dürfen, für die noch kein Datenbanksystem bekannt ist. Genauso gut könnte man mit 1,m festlegen, dass nur Datentypen in die Datenbank kommen, zu denen in der Datenbank auch ein Datenbanksystem erfasst ist. |
|
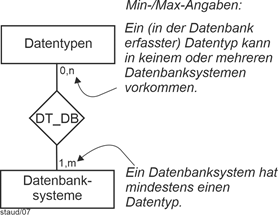
|
|
Abbildung 4.2-1: Min-/Max-Angaben |
|
Die folgenden weiteren Beispiele zu Min-/Max-Angaben beziehen sich auf die (vereinfachte) Situation in einem Sportverein. Unterhalb des Beziehungstyps sind jeweils die Kardinalitäten angegeben. |
|
Bei der Beziehung 1 zwischen Mannschaften und Mitgliedern wird hier durch das Datenmodell festgelegt, dass eine Mannschaft aus mindestens 11 und maximal 14 Spielern besteht (evtl. mit Ersatzspielern) und dass ein Mitglied in mindestens einer und maximal zwei Mannschaften spielt. |
|

|
|
Abbildung 4.2-2: Min-/Max-Angaben 1: Pflichtbeteiligung / mehrwertig |
|
Benennung von Beziehungstypen: Hier wurden Verben gewählt. Diese sind zwar anschaulich, aber nur in eine Richtung wirklich treffend. Wählt man Substantive (oben: Mannschaften – Mitglieder, bzw. Abkürzungen, z.B. Ma – Mi) hat man das „Richtungsproblem“ nicht, verliert aber evtl. an Aussagekraft. |
|
Die Beziehung 2 zwischen Mannschaften und Abteilungen ist hier so angenommen, dass eine Mannschaft genau einer Abteilung zugeordnet sein muss („mindestens in einer, höchstens in einer“). Die Zahlen bei Abteilungen bedeuten, dass eine Abteilung mindestens eine Mannschaft hat (eine Abteilung existiert also in der Datenbank (modelltechnisch) erst, wenn auch die erste Mannschaft eingerichtet wurde), dass sie aber auch mehrere haben kann. |
|

|
|
Abbildung 4.2-3: Min-/Max-Angaben 2: Pflichtbeteiligung / einer oder mehr |
|
Natürlich gibt es auch Beziehungen, die auf jeder Seite den maximalen Wert 1 haben. Nehmen wir für dieses Beispiel an, es gäbe einen eigenen Entitätstyp Trainer und es wäre weiterhin so, dass zu einem Zeitpunkt eine Mannschaft von einem Trainer trainiert wird und dass jeder Trainer auch nur eine Mannschaft betreut. Dann ergibt sich die Situation von Beispiel 3. Der Nullwert auf der linken Seite kann bedeuten, dass eine Mannschaft auch mal ohne Trainer sein kann, der Nullwert auf der rechten Seite, dass ein Trainer auch Trainer sein kann, ohne dass ihm eine Mannschaft zugewiesen ist. |
|

|
|
Abbildung 4.2-4: Min-/Max-Angaben 3: Optionale Beteiligungen / maximal 1 |
|
Somit gehen die Min-/Max-Angaben immer von dem Entitätstyp aus, bei dem sie stehen und geben an, mit wieviel Entitäten des anderen Entitätstyps eine Entität in Beziehung steht. |
|
Aus den Min-/Max-Angaben können die Kardinalitäten direkt abgelesen werden. Es sind jeweils die Angaben zu den maximalen Werten. |
|
Min-/Max-Angaben bei mehrstelligen Beziehungen |
|
Es gibt in ER-Modellen nicht nur zweistellige Beziehungen. Grundsätzlich sind beliebigstellige möglich. Allerdings ist dann die Bestimmung der Min-/Max-Angaben nicht mehr so einfach wie im zweistelligen Fall. Die Min-/Max-Angaben eines Entitätstyps können nun nicht mehr mit einem konkreten anderen, sondern nur mit dem Beziehungstyp in Verbindung gesetzt werden: Für jeden Entitätstyp wird ausgedrückt, mit wieviel Entitäten er minimal und maximal am Beziehungstyp teilnimmt. Die folgende Abbildung zeigt ein Beispiel. |
|
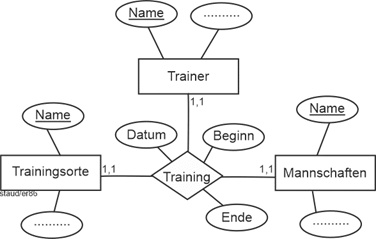
|
|
Abbildung 4.2-5: Dreistelliger Beziehungstyp – Variante 1 |
|
Hier bedeuten die Min-/Max-Angaben: |
|
- Am Training nimmt genau eine Mannschaft teil
- Das Training findet an einem Ort statt
- Es wird durch einen Trainer durchgeführt
|
|
Die folgende Abbildung zeigt eine Variante. |
|
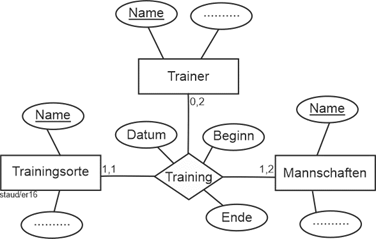
|
|
Abbildung 4.2-6: Dreistelliger Beziehungstyp – Variante 2 |
|
Jetzt ist die Bedeutung der Min-/Max-Angaben wie folgt: |
|
- Am Training nimmt mindestens eine, maximal zwei Mannschaft/en teil
- Das Training findet an genau einem Ort statt
- Es wird nicht immer von einem Trainer durchgeführt. Falls doch, sind höchstens zwei beteiligt.
|
|
Diese Beispiele müssten genügen um klarzumachen, dass mit der Festlegung der Min-/Max-Angaben ein weiteres wichtiges Stück Semantik im Datenmodell festgehalten wird
 . Gleichzeitig helfen diese Angaben, sich über die Beziehung klar zu werden.
. Gleichzeitig helfen diese Angaben, sich über die Beziehung klar zu werden. |
|
4.3 Totale Beteiligung |
|
Die Situation, dass alle Entitäten eines Entitätstyps an einer Beziehung teilhaben müssen, kann in ER-Modellen auch grafisch ausgedrückt werden, durch eine Doppellinie auf der Seite des betreffenden Entitätstyps. Dies wird „totale Beteiligung von ... an …“ genannt und bezieht sich immer auf einen Entitäts- und einen mit ihm verbundenen Beziehungstyp. |
|
Nehmen wir das Datenmodell der folgenden Abbildung. Hier könnte verlangt werden, dass nur Händler erfasst werden, die tatsächlich (in unserer Datenbank) zumindest ein Datenbanksystem anbieten. Mit anderen Worten wird damit verlangt, dass jede Entität von Händler in die Beziehung DB/H verwickelt ist. Die grafische Notation ist eine Doppellinie, wie der folgende Auszug aus dem Datenmodell zeigt. |
|
|
|
Abbildung 4.3-1: Totale Beteiligung von Entitäten an Beziehungen |
|
Dies kann auch durch Min-/Max-Angaben ausgedrückt werden. Es entspricht da einem minimalen Wert von 1. Die Beziehung ist dann also eine Pflichtbeziehung. |
|
Für die Datenbanksysteme wird dies in obigem Datenmodell nicht verlangt. Dadurch ist es dann möglich, Datenbanksysteme zu erfassen, von denen noch kein Händler bekannt ist. |
|
|
|
|
|
5 Muster in ER-Modellen |
|
|
|
5.1 Ähnlichkeit durch Generalisierung / Spezialisierung |
|
In Abschnitt 3.3 ist ein Beispiel, das – etwas erweitert – den hier vorzustellenden Sachverhalt anschaulich beschreibt. Die Angestellten eines Unternehmens wurden u.a. durch die Attribute PersNr, Name, Vorname, IT-Komp (IT-Kompetenz). PSn (Programmiersprachenkompetenz) und ProgErf (Programmiererfahrung) beschrieben. Spätestens bei der ersten Erfassung von Daten hätte man bemerkt, dass es Angestellte gibt, die keine Programmierer sind, auf die also PSn und ProgErf nicht anwendbar sind. Und dass die Anwendung des Attributs IT-Komp auf die Programmierer keinen Sinn macht, weil hier immer IT-Kompetenz vorliegt. Deshalb wurde dort der eine Entitätstyp Angestellte in zwei Entitätstypen zerlegt (vgl. Abbildung 3.2-3). Das erzeugt aber sicherlich bei der aufmerksamen Leserin oder dem aufmerksamen Leser ein Unbehagen: Ist es wirklich modelltechnisch sinnvoll, die Attribute PersNr, Name und Vorname (in Wirklichkeit wären es noch deutlich mehr) doppelt zu erfassen, in zwei Entitätstypen? Wie sollte da die Konsistenz in den Attributen gewahrt werden? |
Programmierer und andere Angestellte |
Ein Instrument zur Bewältigung dieser Situation und zur Erhöhung der Aussagekraft in Semantischen Datenmodellen ist die sog. Generalisierung / Spezialisierung (GenSpez). Mit ihr kann die Tatsache im ER-Modell ausgedrückt werden, dass Entitätstypen zwar nicht gleich sind (d.h., dieselben Attribute haben), aber eine große Ähnlichkeit aufweisen. D.h., sie haben viele Attribute gemeinsam und einige nicht. |
|
Die Lösung besteht darin, die gemeinsamen Attribute in einen eigenen Entitätstyp zu nehmen (die wird dann Generalisierung genannt) und die spezifischen in jeweils eigene (die Spezialisierungen). |
|
Die grafische Notation ist so, dass oben der „Generalisierungs-Entitätstyp“ eingefügt wird. Darunter die „Spezialisierungs-Entitätstypen“. Diese werden untereinander und mit der Generalisierung durch Linien verbunden. Im Schnittpunkt der Verbindungslinien wird ein Kreiselement mit dem Buchstaben d (für „disjunkt“) oder ü (für „überlappend“) eingefügt. Wie bei Entitätstypen üblich werden Attribute zugeordnet. Die Generalsisierung erhält die Attribute, die für alle Entitätstypen Gültigkeit haben, die Generalisierungen nur die für sie spezifischen. Generalisierungen müssen einen Schlüssel aufweisen (hier PersNr). Generalisierungen/Spezialisierungen können mehrstufig sein, d.h., eine Spezialisierung kann für andere eine Generalisierung darstellen (vgl. das Beispiel in Abb. 5.1-2). |
|
Wer die objektorientierte Theorie kennt, weiß, dass dieses Konzept dorthin übernommen wurde und eine wichtige Rolle spielt. Es bezieht sich dort auf Attribute UND Methoden und ermöglicht das Konzept der Vererbung, das danach für objektorientierte Datenbanken genutzt wurde und dass auch in vielen Programmiersprachen auftauchte. |
|
Für eine umfassende Einführung in die objektorientierte Theorie vgl. [Staud 2019] |
|
Im obigen Beispiel Angestellte/Programmierer ergibt sich dann die Lösung der folgenden Abbildung. |
|
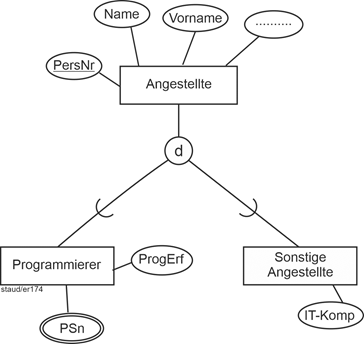
|
|
Abbildung 5.1-1: Generalisierung / Spezialisierung am Beispiel Angestellte |
|
Bedeutung gewinnt dieses Konzept Generalisierung / Spezialisierung, weil dadurch Ähnlichkeit zwischen Entitäten bzw. Entitätstypen erfasst werden kann. Es gibt Attribute, die sich auf alle Entitäten beziehen. Diese werden in einen Entitätstyp gepackt zur sog. Generalisierung. Es gibt Entitäten mit spezifischen Attributen. Diese bilden jeweils einen eigenen Entitätstyp, die sog. Spezialisierungen. Während also die Generalisierung die Übereinstimmung erfasst, drücken die Spezialisierungen die Unterschiede aus. |
Ähnlichkeit zwischen Entitäten |
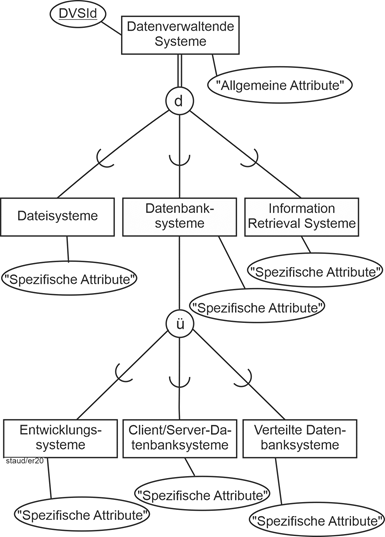
Betrachten wir als weiteres Beispiel den Anwendungsbereich "datenverwaltende Systeme" (DVS). Damit sollen alle die Softwareprodukte gemeint sein, deren Hauptaufgabe darin besteht, Daten zu verwalten. Beispiele sind Dateisysteme, Datenbanksysteme, Information Retrieval Systeme, NoSQL-Systeme, usw. Außerdem soll erfasst werden, dass Datenbanksysteme wiederum unterteilt werden können in Entwicklungssysteme, Client/Server-Datenbanksysteme und Verteilte Systeme. |
Beispiel datenverwaltende Systeme |
Anmerkung: |
|
- Information Retrieval Systeme: Dies sind Programme zur professionellen Verwaltung von (auch und vor allem langen) Texten.
|
- Entwicklungssysteme: Datenbanksysteme mit einer Entwicklungsumgebung zur Realisierung komplexer Anwendungen.
|
- Client/Server-Datenbanksysteme: Datenbanksysteme, die Client/Server-Architekturen unterstützen.
|
- Verteilte Systeme: Datenbanksysteme, die ihre Daten „verteilt“ auf unterschiedlichen geographischen Standorten halten und trotzdem integriert anbieten können.
|
Es gibt natürlich noch sehr viel mehr solcher datenverwaltenden Systeme. Zu jeder Informationsart (Netzwerke, chemische Strukturformeln, physikalische Daten, …), die man digitalisieren konnte, was schon ab den 1950-er Jahren geschah, wurden auch datenverwaltende Systeme entwickelt. Vgl. hierzu nicht nur die aktuelle Entwicklung rund um die sog. NoSQL-Datenbanken, sondern auch die um Fachinformationsdatenbanken. |
|
Will man solche Systeme in einer Datenbank verwalten, sie also durch Attribute beschreiben, wird man feststellen, dass sie viele Attribute gemeinsam haben, jeder Typ aber auch spezifische nur für ihn gültige Attribute aufweist. In der folgenden Abbildung ist hierzu ein Beispiel und die grafische Notation angegeben. |
|
Die Spezialisierungen treten in zwei Varianten auf, die beide im folgenden Beispiel und der Abbildung integriert sind. Die erste Spezialisierung von Datenverwaltende Systeme in Dateisysteme, Datenbanksysteme, usw. hat ausschließenden Charakter: ein System ist Dateisystem ODER Datenbanksystem ODER Information Retrieval System im Sinne des ausschließenden ODER. Deshalb wird hier in der grafischen Notation ein „d“ (für disjunkt) angegeben. |
Oder |
Dagegen hat die Einteilung von Datenbanksystemen in Entwicklungssysteme, Client/Server-Datenbanksysteme und Verteilte Datenbanksysteme keineswegs ausschließenden Charakter. So sind heute – zumindest auf der Ebene der Mittleren Datentechnik – so gut wie alle Datenbankentwicklungssysteme auch Systeme, die Client/Server-Architekturen unterstützen. Deshalb wird hier in der grafischen Notation ein „ü“ für „überlappend" angegeben (in der englischsprachigen Literatur „o“ für „overlapping“). Beide Generalisierungs-/Spezialisierungs-Varianten kommen häufig vor und bedürfen entsprechender datenbanktechnischer Berücksichtigung. |
ü bzw. o |
|
|
Abbildung 5.1-2: Generalisierung / Spezialisierung |
|
Hinweise: |
|
- DVSId: Schlüssel für die Datenverwaltenden Systeme.
|
- Kreis mit d: Spezialisierungen sind disjunkt.
|
- Mengenzeichen: Spezialisierung ist Teilmenge der Generalisierung.
|
- Kreis mit ü: Spezialisierungen sind überlappend.
|
„Spezifische Attribute“ sind Platzhalter für Attribute, die den jeweiligen Spezialisierungen zugeordnet sind. |
|
Die Doppellinie bedeutet, wie oben angeführt, totale Beteiligung. Im obigen Beispiel ist es also so, dass alle erfassten datenverwaltenden Systeme in eine der Spezialisierungen fallen müssen. Somit werden nur Systeme erfasst, die in einer der Spezialisierungen vorkommen. |
|
5.2 Enthaltensein |
|
Ein weiterer Aspekt der semantischen Modellierung betrifft die Tatsache, dass sich oftmals Entitäten aus anderen zusammensetzen. Dies wird mit der Teil_von - Beziehung (auch part_of - Beziehung) erfasst. Sie wird im Rahmen der Modellierungstechniken als Aggregation bezeichnet. |
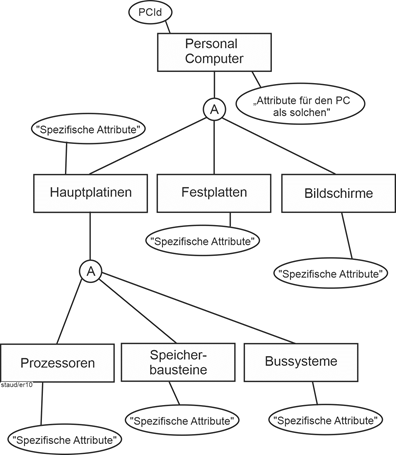
Aggregation |
Die grafische Notation ist so, dass oben der „Aggregations-Entitätstyp“ eingefügt wird. Darunter die „Komponenten-Entitätstypen“. Diese werden untereinander und mit der Aggregation durch Linien verbunden. Im Schnittpunkt der Verbindungslinien wird ein Kreiselement mit dem Buchstaben A (für Aggregation) eingefügt. Wie bei Entitätstypen üblich werden Attribute zugeordnet. Jeder Entitätstyp hat eigene. Diese sind v.a. beschreibend, können aber auch identifizierend sein. Aggregationen müssen einen Schlüssel aufweisen. Sie können mehrstufig sein, d.h., ein „Komponenten-Entitätstyp“ kann für andere „Aggregations-Entitätstyp“ sein. |
Vgl. die folgende Abbildung |
Ein einfaches Beispiel zeigt die nachfolgende Abbildung. Dabei soll es um PC gehen, die aus Hauptplatinen, Festplatten und Bildschirmen zusammengesetzt sind. Für Hauptplatinen wiederum sind als Komponenten Prozessoren, Speicherbausteine und Bussysteme denkbar. Diese Zusammensetzung soll – z.B. im Rahmen einer Massenproduktion – festgehalten werden. Das Attribut PCId ist der Schlüssel für die PC, HPId für die Hauptplatinen (Motherboards). |
|
|
|
Abbildung 5.2-1: Teil_von - Beziehung |
|
Hier wird also nicht Ähnlichkeit erfasst, wie oben bei der Generalisierung / Spezialisierung, sondern Zusammengehörigkeit. |
|
Oft wird die Frage gestellt, ob dieses Konzept wirklich nötig ist oder ob es nicht genügen würde, einfach alle Attribute einem Entitätstyp zuzuordnen. Dann entstünde im obigen Beispiel ein Entitätstyp Personal Computer mit den Attributen aller in der Abbildung angegebenen Komponenten. Nachteil einer solchen Lösung ist, dass bei vielen Attributen kein Attributseintrag möglich ist (weil das Attribut nicht „passt“) und dass die Eigenschaft von Komponenten oder Teilen, in anderen enthalten zu sein, nicht erfasst würde. |
Warum? |
Die Teil_von - Beziehungen werden vor allem bei Datenbanken benötigt, die technische Sachverhalte verwalten. Stellen wir uns eine Datenbank vor, in der die technischen Komponenten eines Großflugzeuges verwaltet werden. Hier zerfällt das gesamte Flugzeug in Komponenten, diese wieder, usw., bis man bei den kleinsten Teilen ankommt, die für das Flugzeug verwendet werden. Dieses „Enthaltensein“ von Komponenten und Teilen ineinander kann nur durch die Teil_von - Beziehung erfasst werden. |
|
Beide Techniken (Generalisierung / Spezialisierung und Aggregation) sind zwar elementar, was die menschliche Wahrnehmung angeht, werden aber doch vom relationalen Datenmodell und den älteren Datenmodellen nicht direkt unterstützt. |
|
5.3 Muster Einzel/Typ |
|
Die Unterscheidung einer einzelnen Entität und ihres Typs ist wichtiger Bestandteil unserer Welt, genauer: unserer Wahrnehmung dieser Welt. Sie beruht auf dem, was auch Kategorisierung genannt wird. Wir treffen sie nicht nur in „technischen Weltausschnitten“ an (das einzelne Fahrzeug, der Fahrzeugtyp) und in der Biologie (einzelne Pflanze, Pflanzengattung), sondern überall dort, wo wir wahrnehmen und kategorisieren. |
Vgl. auch das Beispiel in Abschnitt 11.4 (Schützenverein) |
Attribute für die Einzelobjekte und die Klasse |
|
In Kapitel 2 wurde gezeigt, wie einzelne Entitäten zu Entitätstypen zusammengefasst werden. In einem Entitätstyp sind dann Entitäten, die genau dieselben Attribute besitzen. Jedes Attribut beschreibt somit alle einzelnen Entitäten des Entitätstyps, jeder Entität kann eine Attributsausprägung zugewiesen werden. Nun gibt es aber Situationen in Anwendungsbereichen, wo dem Typ als Ganzes ebenfalls Attribute und Attributsauswertungen zugewiesen werden müssen. Insgesamt liegen dann also Attribute für die einzelnen Entitäten und den Entitätstyp vor. |
|
Dieses Muster – es wird hier Einzel/Typ-Muster genannt – ist in den Anwendungsbereichen ständig präsent und muss dementsprechend auch in den Datenmodellen der Anwendungsbereiche umgesetzt werden. Leider wird es oft übersehen, was zu Redundanz in den Datenbeständen führt. |
|
Je nach Anwendungsbereich und Entitätsart wird die Gesamtheit aller Entitäten auf abstrakte Weise unterschiedlich benannt: Ganz allgemein und evtl. auch zurückgreifend auf die objektorientierte Theorie mit Klassen. Falls es sich um Tiere handelt Gattungen, bei Geräten Typen (Gerätetypen), bei Menschen Gruppen, usw. |
|
Will man bei solchen Entitäten die Informationen der einzelnen Entitäten mit denen des Typs ergänzen und fügt man diese einfach dem Entitätstyp mit den Einzelinformationen hinzu, ist dies redundant. Einige Beispiele: |
|
- In einem Zoo werden evtl. die einzelnen Tiere (Schimpanse Eddi, Orang Utan Franz, Elefant Paul, ...) durch Attribute erfasst, zum anderen auch die Gattungen (Schimpansen, Orang Utans, Elefanten, ...). Natürlich nur für Großtiere, die als Individuen in Erscheinung treten.
- In der Technik wird in bestimmten Situationen das einzelne Stück erfasst (einzelne Kraftfahrzeuge, Festplatten, Flugzeugersatzteile, ...), zum anderen auch die gleichartigen Gruppen (Kraftfahrzeuge, Festplatten, Flugzeugersatzteile eines Typs, ...).
- Bei Menschen wird oftmals der einzelne Mensch erfasst (mit Personalnummern, Namen, usw.) und auch die Gruppe, zu der er gehört (Mitarbeiter IT, Leiharbeiter, Leitendes Management, ...).
|
|
Liegt eine solche Situation vor, gibt es drei Möglichkeiten: |
|
- Im ER-Modell und später in der Datenbank werden nur Attribute zu den einzelnen Entitäten erfasst. Dann gibt es einen Entitätstyp zu diesen und alles ist in Ordnung. Das entspricht der Standardsituation.
- Es werden nur Attribute zum Typ (bzw. zur Gattung, Gruppe) erfasst. Dann gibt es einen Entitätstyp zu diesen und die Sache ist ebenfalls geklärt.
- Zu beidem, zu den einzelnen Entitäten und zum Entitätstyp sind Attribute zu erfassen. Dann müssen zwei Entitätstypen angelegt werden und die Attribute müssen auf diese aufgeteilt werden. Attribute, die einzelne Entitäten beschreiben, kommen in den Entitätstyp mit den Einzelinformationen. Beschreiben sie den Entitätstyp als Ganzes, kommen sie in einen Entitätstyp mit den Typinformationen. Vgl. dazu die folgenden Beispiele.
|
|
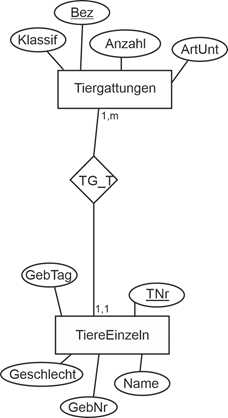
Beispiel: Zootiere – einzeln und als Gattung |
|
Die folgende Abbildung zeigt das Muster in einem Anwendungsbereich, in dem es um Tiere geht, z.B. in einem Zoo. Die Tiergattungen des Zoos könnten aus Schimpansen, Orang Utans, Elefanten usw. bestehen. Für sie wird der Entitätstyp Tiergattungen mit den Attributen Bezeichnung (Bez), Anzahl der Tiere im Zoo (Anzahl), einer Angabe zur Klassifikation (Klassif) und Hinweisen zur Art der Unterbringung (ArtUnt) erfasst. Für die einzelnen Tiere im Entitätstyp TiereEinzeln gibt es eine Tiernummer (TNr), einen Namen (Name), den Geburtstag (GebTag), das Geschlecht und die Nummer des Gebäudes, in dem sie untergebracht sind (GebNr). Die Verbindung der beiden Entitätstypen leistet der Beziehungstyp TG_T. Die Min-/Max-Angaben sind 1,1 bei der „Einzel“-Information und 1,n bei der Typ-Information. |
|
|
|
Abbildung 5.3-1: Muster Einzel/Typzu Zootieren |
|
Weitere Beispiele zum Muster Einzel/Typ finden sich, in relationaler Umsetzung, in [Staud 2021], Abschnitt 14.2. |
|
|
|
|
|
6 Beziehungen – vertieft |
|
|
|
6.1 Beziehungsfindung |
|
Am Anfang der Modellierung steht immer die Festlegung von Entitäten und Beziehungen, die dann im weiteren zu Typen zusammengefasst werden. Entitäten können damit noch relativ leicht erkannt werden. Entweder direkt (weil offensichtlich) oder durch Attribute, deren Erfassung als Ziel der Modellierung vorgegeben wird oder die für die gewünschten Anwendungen nötig sind. Schwieriger ist es mit Beziehungen. Einige Beispiele: |
|
- „Liefert“ in einer Datenbank mit Produkten und Kunden
- „bietet_an“ in einer Datenbank zu Datenbanksystemen oder Online-Datenbanken
- „leitet_Abteilung“ und „arbeitet_in“ in einer Datenbank zu den Mitarbeitern eines Unternehmens
|
|
Die Beispiele machen deutlich: Beziehungen in Datenbanken setzen Entitäten verschiedener Entitätstypen miteinander in Beziehung. Manchmal auch nur die eines Entitätstyps, z.B. in leitet_Abteilung oder die mehrerer, z.B. in dem in der Literatur vielzitierten Beispiel einer Datenbank zu Projekten, Teilen und Lieferanten, wenn festgehalten werden soll, welches Teil von welchem Lieferanten in welches Projekt geliefert wird. Hierbei entsteht eine dreistellige Beziehung zwischen den Entitätstypen. |
Entitäten in Beziehung setzen. |
Dieses „in Beziehung setzen“ kann natürlich auch auf einem realen Vorgang beruhen, wie in dem oben angeführten Beispiel liefert. |
|
Oftmals ist es aber nicht einfach zu entscheiden, was Entität und was Beziehung ist und schon kleine Änderungen der Semantik können das Datenmodell ändern. Dies soll an einem Beispiel veranschaulicht werden. |
|
6.2 Beispiel Transporte |
|
Nehmen wir als Beispiel Transportvorgänge in einem Transportunternehmen. Stehen die Transporte im Vordergrund, könnte es in sehr einfacher Form (vielleicht für einen Fahrradkurier) wie in der folgenden Abbildung (Lösung 1) modelliert werden. Für jeden Transport werden Absender- und Empfängername, Zeitpunkt des Transports und weitere Attribute erhoben, die den Transportvorgang selbst beschreiben. Außerdem werden die Transporte durchnummeriert, was einen problemlosen Schlüssel liefert. |
Variante 1 |
|
|
Abbildung 6.2-1: Lösung 1 – Transport als solcher |
|
Für den nächsten Schritt nehmen wir an, dass Absender und Empfänger detaillierter beschrieben werden sollen und dass sie auch unterschiedliche Attribute haben, z.B. weil die einen hauptsächlich Unternehmen und die anderen Privatleute sind. Dann wäre eine Modellierung wie in der nächsten Abbildung denkbar. |
Variante 2 |
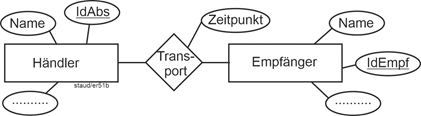
|
|
Abbildung 6.2-2: Lösung 2 – Absender und Empfänger |
|
Es entstehen zwei verschiedene Entitätstypen (mit Schlüsseln, die den Absender oder Empfänger identifizieren: IdAbs und IdEmpf) und der Transportvorgang wird durch einen Beziehungstyp erfasst. |
|
Eine weitere Variante zeigt die folgende Abbildung. Sie ist sinnvoll, wenn Absender und Empfänger durch dieselben Attribute beschrieben werden, d.h., wenn sie (datenbanktechnisch) „gleich“ sind. Dann müssen sie zu einem einzigen Entitätstyp Kunden zusammengefasst werden auf dem sich eine rekursive Beziehung Transporte befindet. |
Variante 3 |
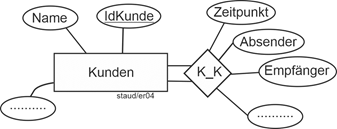
|
|
Abbildung 6.2-3: Lösung 3 – Transporte als Kontakte zwischen Kunden |
|
Zu lösen bleibt hier noch das Problem der Identifizierung einzelner Transporte. Entweder durch Zusammenfassen der Informationen zu Absender, Empfänger und Zeitpunkt oder durch Einführung eines Attributs IdTransport. |
|
Sind sich die Kunden bezüglich ihrer Attribute weitgehend aber nicht vollständig gleich, könnte auch eine Generalisierung / Spezialisierung eingeführt werden. Dies zeigt die folgende Abbildung. Hier wurde angenommen, dass sich die Kunden sinnvoll in private und gewerbliche Kunden unterteilen lassen. In letzteren können dann noch die Großkunden separiert werden. |
Variante 4 |
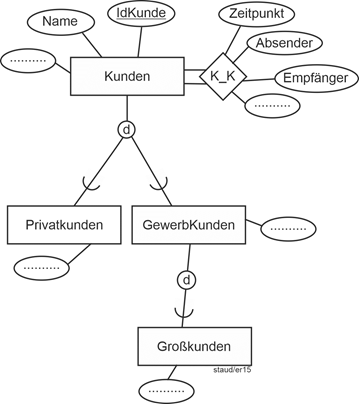
|
|
Abbildung 6.2-4: Lösung 4 – Spezialisierungen |
|
Mit obigen Beispielen sollte deutlich geworden sein, dass gerade bei Beziehungen kleine Änderungen in der Semantik zu großen Änderungen im ER-Modell führen können. |
|
|
|
|
|
7 Die Zeit in ER-Modellen |
|
Es geht hier um die Bewältigung der zeitlichen Dimension in ER-Modellen. Nicht um Sicherungsmethoden, um Archivierung, um zeitlich fixierte Backups und ähnliches. |
|
Dieses Kapitel ist in Bearbeitung. Die endgültige Fassung erscheint Ende des Jahres. |
|
Geht es um Attribute, deren Werte sich im Zeitverlauf ändern, ist die Standardlösung in Unternehmensdatenbanken, insbesondere für die kaufmännischen Anwendungsbereiche die, dass jeweils nur die aktuellen Daten erfasst werden. Bei jedem Eintrag wird also der alte Wert überschrieben. Um dies zu verdeutlichen: Wechselt ein Kunde die Adresse, wird die neue eingetragen, die alte ist überschrieben. Ändert sich der Preis eines in der Produktion benötigten Teils, wird der alte überschrieben. Und so weiter. Dies bedeutet, dass Datenbanken entstehen, die den aktuellen Stand erfassen, nicht mehr. Oftmals wird der jeweilige Zeitpunkt der Einrichtung oder letzten Aktualisierung durch ein zeitliches Attribut festgehalten (z.B. Rechnungsdatum). Dies alles kann in ER-Modellen problemlos ausgedrückt werden. |
Nur der aktuelle Stand |
Oftmals reicht aber die Konzentration auf die jeweils aktuelle Datenlage nicht aus. Es sollen auch Informationen der Vergangenheit weiter bereit gestellt werden. Z.B. die Rechnungen von vor einigen Jahren mit den damaligen Werten (Attributsausprägungen). Soll dies im Rahmen der bestehenden Datenbank geleistet werden, sind entsprechende Weiterungen des ER-Modells nötig. |
Auch historische Daten |
|
|
7.1 Zeitliche Aspekte in ER-Modellen |
|
Das Motiv für dies Erfassung der zeitlichen Dimension lieg auch darin, dass viele Eigenschaften von Anwendungsbereichen bzw. Attribute von Entitätstypen in ER-Modellen zeitlich fixiert sind. Sie haben einen Zeitstempel und dieser muss erhalten bleiben. Dies kann ein einmaliger Zeitstempel sein (Rechnungsdatum von Rechnungen), ein wiederholter (Gewichtsmessung mit Datumsangabe; Kurs der Lieblingsaktie mit Tagesangaben) oder ein Zeitraum (Eintritt und Austritt von Vereinsmitgliedern). |
Motiv |
Folgende Aspekte müssen dabei im Datenbankkontext beachtet werden: |
|
- Der zeitliche Aspekt bezieht sich auf Entitäten bzw. Entitätstypen. Er zeigt sich durch Attribute, mit denen die Zeitaspekte festgehalten werden. Z.B. Eintrittsdatum bei Angestellten, Geburtstagen bei Personen, usw. Der Zeitstempel kann den ganzen Entitätstyp prägen (Rechnungsdatum bei Rechnungsköpfen) oder nur eine Eigenschaft (Lieferdatum bei Rechnungsköpfen).
- Zeit als Eigenschaft/ein Zeitpunkt: Die Attribute fixieren einen Zeitpunkt (Fixierende Zeitpunkte). Die zu erfassende Information hat einen Zeitstempel, der über die Zeit erhalten bleibt. Z.B. ein Rechnungs- oder Vertragsdatum.
- Attribute, die sich über die Zeit verändern: Eigenschaften und ihre Attributsausprägungen im ER-Modell verändern sich. Artikel erhalten eine neue Bezeichnung, einen neuen Preis; Personen wechseln ihren Namen, usw. Unter Umständen ist es aber notwendig, die Entitäten vor den Veränderungen zu reproduzieren (Rechnung von vor 2 Jahren, usw.). In einem solchen Falls muss der Zeitaspekt im Datenmodell hinzugefügt werden.
- Zeit als Eigenschaft/mehrere Zeitpunkte: Die Attribute werden wiederholt erhoben, jeweils mit Zeitstempel. Z.B. (der jeweils aktuelle) Artikelpreis, die jeweils aktuellen Adressangaben, usw.
- Zeit als Eigenschaft/Zeitreihen: Die wiederholt erhobenen Attribute können Zeitreihen sein. Die erfasste Information besteht aus vielen Zeitpunkten, die zeitlich geordnet sind. Z.B. tägliche Gewichtsmessungen, jährlich erhobene Exporte, täglich erhobene Aktienkurse, usw. Da diese nicht in klassischen Datenbanken verwaltet werden, sollen sie hier keine Rolle spielen. Sie beruhen auf statistischen Zeitreihen oder auf Merkmalsräumen, für die jeweils eigene datenverwaltende System entwickelt wurden. Vgl. für einen Einblick [Staud 1991] und die Publikationen zu Statistischen Datenbanken in http://www.staud.info/literatur/li_f_1.htm.
- Zeiträume: Oftmals liegen Zeitabschnitte mit einem Anfangs- und einem Endzeitpunkt vor. Beide sollten, wenn erhoben, nicht mehr verändert werden. Z.B. das Eintritts- und Austrittsdatum bei Vereinsmitgliedern.
|
|
7.2 Fixierende Zeitpunkte |
|
Fixierende Zeitpunkte sind also solche, die einmal erhoben und dann nie wieder verändert werden sollten. In jedem Anwendungsbereich gibt es solche Attribute mit entsprechenden Daten. Zum Beispiel ... |
Einmal erhoben, nie mehr verändert |
- Bei einer Rechnung der Rechnungskopf mit seinem Datum
- Bei einer Gewichtsmessung die Angabe des Messzeitpunktes
- Beim Auftragseingang das Datum
|
|
Solche Einträge in die später entstehende Datenbank behalten diese zeitliche Fixierung bis zum Ende der Datenbank. Sie bedürfen keiner Anpassung des ER-Modells. Wird diese Information vielleicht später wieder benötigt, ist sie da. |
|
In einem ER-Modell zur Rechnungsstellung (vgl das Beispiel in Abschnitt 11.1) sind die Rechnungsköpfe zeitlich fixiert. Entsprechendes gilt für die zugeordneten Attribute. Das folgende Fragment zeigt ein Beispiel. |
ER-Modell |
|
|
Abbildung 7.2-1: Fixierende Zeitpunkte |
|
Für Einbettung und Erläuterungen vgl. Abschnitt 11.1, insbesondere Abb. 11.1-2. |
|
Den Zeitstempel für die Entitäten des Entitätstyps (die Rechnungsköpfe) liefert das Attribut ReDatum (Rechnungsdatum). Dieser ist zeitlich prägend für den gesamten Entitätstyp. Weitere zeitliche Festlegungen erfolgen für die Lieferung DatumLief(erung) und für den Kaufvertrag KVDAT (Kaufvertragsdatum). Alle anderen Attribute sind auf das Rechnungsdatum bezogen. D.h., erfasst wurden der Verkäufer, das Tour-Team, die ZV (Zahlungsvereinbarung) und der MWStB (Mehrwertsteuerbetrag) zu diesem Zeitpunkt. Die Rechnungsnummer kann fortlaufend sein, hat also keine zeitliche Fixierung. Für alle Atttribute diese Entitätstyps gilt also: Sie bleiben über die Zeit unverändert, können auch sehr viel später abgefragt werden. |
|
7.3 Zeitabhängige Ausprägungen |
|
Viele Informationen und ihre Attribute haben aber die oben vorgestellte zeitliche Fixierung nicht, sondern erfassen den aktuellen Informationsstand zum Zeitpunkt der Datenerfassung. Die Attributsausprägungen können überschrieben werden. Dabei gehen dann die früheren Daten verloren. Zum Beispiel bei einem Entitätstyp Artikel in einem WebShop, wie im folgenden Modellfragment. |
|
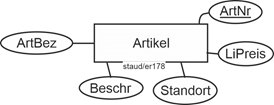
|
|
Abbildung 7.3-1: Zeitabhängige Ausprägungen – Artikel |
|
Auch dieses Modellfragment entstammt dem Beispiel von Abschnitt 11.1. |
|
Ändert sich hier z.B. der Preis eines Artikels, wird der alte überschrieben und steht (in der Datenbank) nicht mehr zur Verfügung. Genauso die Beschreibung. Selbst die Artikelnummer kann zeitabhängig sein, wenn bei Wegfall eines Artikels die ArtNr neu vergeben wird. Es wäre also nicht möglich, die Preise des Vorjahres zu ermitteln, usw. |
Bei Überschreiben Verlust |
Eine Lösung besteht darin, bei jeder Änderung der Daten einen neuen Entitätstyp vorzusehen. Dafür wird ein Attribut benötigt, dass den Änderungszeitpunkt festhält. Es soll hier Erfassungszeitpunkt (ErfassZP) genannt werden. Damit ergibt sich das folgende Modellfragment. |
ErfassZP: Erfassungszeitpunkt |
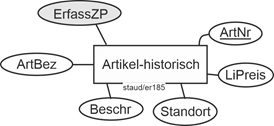
|
|
Abbildung 7.3-2: Zeitabhängige Ausprägungen fixiert – Artikel |
|
Insgesamt gibt es damit eine zeitlich strukturierte Folge von Entitätstypen. Später dann, in der Datenbank, eine Folge von Datensätzen. Dies ähnelt der Vorgehensweise, die ganz aktuell bei NoSQL-Datenbanken im BigData-Bereich gewählt wird. |
|
Abfragetechnisch, später in der Datenbank, muss bei Abfragen auf den Erfassungzeitpunkt geachtet werden. Angenommen, wir wollen eine zwei Jahre alte Rechnung reproduzieren, dann muss bei der Abfrage in allen Dateien (z.B. zu Rechnungsköpfen, Kunden, Artikeln) das richtige Zeitfenster gesucht werden. |
Schwierige Abfragen |
7.4 Zeiträume |
|
Da sie im Folgenden von Bedeutung ist, soll hier nochmals an die Zuordnungsregel (Attribute zu Entitätstypen und Beziehungstypen) erinnert werden. Dabei wird sie um einen Punkt ergänzt: |
|
Attribute werden dem Entitäts- oder Beziehungstyp zugeordnet, dessen Entitäten oder Beziehungen sie beschreiben. Und zwar umfassend: Jedes Attribut muss für alle einzelnen Entitäten des Entitätstyps Gültigkeit haben und dies zu jedem Zeitpunkt. Entsprechend für Beziehungstypen. |
|
Attribute eines Zeitraums (Beginn, Ende) können diese Regel auf demselben Entitäts-/Beziehungstyp nicht erfüllen, da das Attribut für den Eintritt zwar sofort bei Entstehung anwendbar ist, das Attribut für für das Ende des Zeitraums aber erstmal keinen Eintrag erfährt. |
Zeitraum |
Betrachten wir als Beispiel einen Entitätstyp Vereinsmitglieder. Hier könnten auch die erfasst bleiben, die früher Mitglieder waren und die dies durch Austritt, Wegzug oder Tod nicht mehr sind. Realisiert werden könnte dies durch zwei Attribute Eintritt und Austritt. Vgl. das folgende Modellfragment. |
|
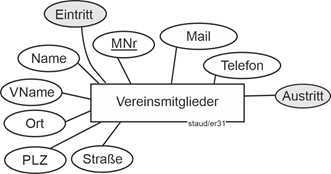
|
|
Abbildung 7.4-1: Zeitliche Aspekte bei Entitätstypen (pragmatische Lösung) – Vereinsmitglieder |
|
Eine solche Erweiterung hat natürlich Konsequenzen: Das ER-Modell ist eigentlich nicht korrekt, denn das Austrittsdatum kann ja erst beschrieben werden, wenn der Austritt erfolgte. Bis dahin ist dies nicht möglich, was einen Verstoß gegen die Zuordnungsregel darstellt. Aus pragmatischen Gründen wird dies aber oftmals genaus so modelliert, und das Austrittsdatum bis zum Eintrag mit einem Nullwert beschrieben. |
Vgl. das Beispiel Schützenverein in Abschnitt 11.4 |
Obiges könnte aber auch modelltechnisch korrekt gelöst werden: mit einem eigenen Entitätstyp für ehemalige Mitglieder. Und, falls bei verstorbenen Mitgliedern das Todesdatum festgehalten werden soll, mit einem eigenen Entitätstyp für verstorbene Mitglieder. Vgl. das folgende Modellfragment. |
|
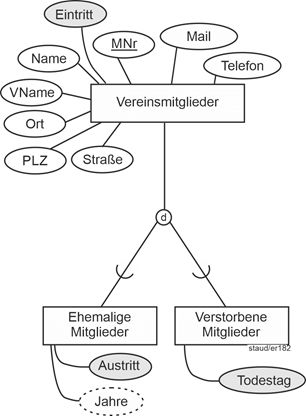
|
|
Abbildung 7.4-2: Zeitliche Aspekte bei Entitätstypen (korrekte Lösung) – Vereinsmitglieder |
|
Vgl. dazu das Beispiel zum Anwendungsbereich Schützenverein in Abschnitt 11.4. Das ER-Modell in Abschnitt 11.4 enthält beide Lösungen („pragmatisch“ und „korrekt“. |
|
Bei dieser Modellierung geht man davon aus, dass ehemalige und verstorbene Mitglieder weiterhin die bei der Generalisierung vorhandenen Attribute zugewiesen haben sollen („letzte Adresse“). |
|
Dieselben Lösungen gibt es für Beziehungen bzw. Beziehungstypen. Im folgenden Fragment ist die pragmatische Lösung angegeben. Festgehalten wird, von wann bis wann ein Trainer eine Mannschaft trainiert, das Attribut „bis“ kann erst beschrieben werden, wenn das Trainerverhältnis endet. |
|
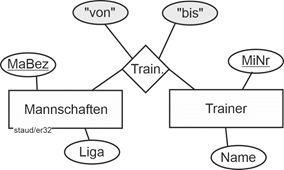
|
|
Abbildung 7.4-3: Historische Aspekte bei Beziehungstypen (pragmatische Lösung) – Training |
|
Will man hier „korrekt“ modellieren, muss das Datenmodell ausgebaut werden. Für den Trainingsanfang und das Trainingsende muss jeweils eine eigene Beziehung mit Beziehungstyp angelegt werden, den einen mit dem Attribut Anfang, den anderen mit Ende. |
|
|
|
Abbildung 7.4-4: Historische Aspekte bei Beziehungstypen (korrekte Lösung) – Training |
|
Relationale Umsetzung: |
|
Mannschaften (#MaBez, Liga) |
|
Trainer (#MiNr, Name) |
|
T-Anf ( #(MaBez, MiNr), Anfang) |
|
T-Ende (#(MaBez, MiNr), Ende) |
|
7.5 ER-Modell Rechnungsstellung |
|
Eine Möglichkeit, die zeitliche Dimension ins ER-Modell zu bringen, ist, jede Entität mit einem Datumsattribut auszustatten, das den Zeitpunkt des Eintrags festhält. |
|
Betrachten wir als Beispiel ein ER-Modell Rechnungsstellung zu Kunden, Rechnungen und Artikeln, wie es die folgende Abbildung zeigt. Es ist angelehnt an das Beispiel aus Abschnitt 11.1, vgl. die Erläuterungen dort sowie Abb 11.1-11. |
|
|
|
Abbildung 7.5-1: ER-Modell Rechnungsstellung |
|
Will man eine Lösung innerhalb des ER-Modells finden, kann man für jeden Entitätstyp, der keine zeitliche Festlegung hat, eine solche anlegen. Ausgangspunkt ist der Zeitpunkt, der für das jeweilige Datenbankobjekt (z.B. Geschäftsobjekt) determinierend ist. In diesem Beispiel also das Rechnungsdatum. |
|
Die Entitätstypen Artikel und Kunden erhalten jeweils ein Attribut ErfassZP (Erfassungszeitpunkt). Dies bildet dann mit dem jeweiligen alten Schlüssel einen zusammengesetzten neuen Schlüssel. Es entstehen also folgende Schlüssel: |
|
KuNr, ErfassZP für Kunden und |
|
ArtNr, ErfassZP für Artikel. |
|
Vgl. die folgende Abbildung. |
|
|
|
Abbildung 7.5-2: ER-Modell Rechnungsstellung – mit Erfassungszeitpunkten |
|
Relationale Umsetzung: |
|
Kunden (#(KuNr, ErfassZP), …) |
|
ReKöpfe (#ReNr, ReDatum, …, KuNr) |
|
RePos (#(ReNr, PosNr), …) |
|
Artikel (#(ArtNr, ErfassZP), …) |
|
Die Änderungen im ER-Modell erscheinen minimal, sind es aber nicht. Die jeweiligen Entitätstypen werden vervielfacht, was ja auch am Schlüssel zu erkennen ist. Es gibt für jeden Erfassungszeitpunkt (Neueintrag, Änderungen) eine eigene Entität. |
|
Dies führt zu Redundanz. Da ja, z.B. wegen einer Änderung, die gesamte Entität dupliziert wird, sind alle nicht geänderten Attribute im Zeitverlauf identisch. |
Redundanz |
Bei Abfragen muss jeweils die Zeitangabe berücksichtigt werden. Wird also ein Rechnungskopf mit seinen Rechnungspositionen ergänzt, muss der SQL-Befehl zusätzlich die zeitliche Übereinstimmung sichern. |
|
Für den Fall, dass eine Min-/Max-Angabe mit dem Wert 1,1 vorliegt, ist eine Lösung denkbar, bei der die „veränderlichen“ Attribute mit ihrem Wert zum Erfassungszeitpunkt Ein Beispiel findet sich in Abschnitt 11.1. |
Sonderfall |
NoSQL-Welt |
|
In der NoSQL und BigData-Welt werden andere Techniken angewandt. Z.B. bei Dokumentendatenbanken. Hier wird nach jeder Änderung eines Feldes das gesamte Dokument als neue Version abgespeichert. Vgl. zu diesem Teil der Datenbankwelt [Staud 2021], Kapitel 24, insbes. Abschnitt 24.10. |
|
|
|
|
|
8 Gleichzeitig Entität und Beziehung |
|
|
|
8.1 Das Problem |
|
Es kommt vor, dass ein Realweltphänomen in einem Datenmodell gleichzeitig als Entitätstyp und als Beziehungstyp benötigt wird. In diesem Fall wird in der grafischen Darstellung ein neues Element genutzt. |
|
Das Beispiel hierzu stammt aus [Stickel 1991, S. 100]. Es wurde hier ein wenig ausgebaut. Der betrachtete Weltausschnitt ist eine Theateragentur, die für beliebige Theater und Stücke Karten an ihre Kunden verkauft. |
|
Grundlage der folgenden Betrachtungen ist, dass alle Realweltphänomene, die wir mit Attributen beschreiben Entitäts- oder Beziehungstyp werden. |
|
Die folgende Abbildung zeigt die Ausgangssituation. Auf der linken Seite wurde modelliert, dass Kunden für bestimmte Vorstellungen Karten kaufen. Dazu wurden die Entitätstypen Kunden und Vorstellungen angelegt, die durch einen Beziehungstyp Karten verknüpft sind. Die Attributausstattung wurde angedeutet. Diese Strukturierung ist durchaus sinnvoll, die Beziehung zwischen Kunden und Vorstellungen wird über den Kartenverkauf hergestellt, der Beziehungstyp Karten erfüllt alle Anforderungen. |
|
Auf der rechten Seite wurden Theater, Stücke und ihre Beziehung modelliert. Dabei muss dann der Entitätstyp Theater mit dem Entitätstyp Stücke verknüpft werden. Aus der Sicht einer Theateragentur (linke Seite) muss dies über die Vorstellungen erfolgen, da diese ja verkauft werden: Ein Stück (z.B. Faust I) wird in einem Theater (z.B. Stadttheater Konstanz) aufgeführt und für diese Vorstellung werden Karten verkauft. |
|
So kann es sich ergeben, dass Vorstellungen gleichzeitig als Entitäts- und Beziehungstyp benötigt werden, wie es die folgende Abbildung zeigt. Dies ist aber eine unbefriedigende Situation. Zuerst grundsätzlich, da ein Realweltphänomen nicht mit zwei unterschiedlichen Theorieelementen im Datenmodell auftauchen darf, dann aber auch datenbanktechnisch, da die Daten einer bestimmten Datenbank miteinander in Beziehung stehen sollten, es also keine isolierten Datenfragmente geben sollte. |
|
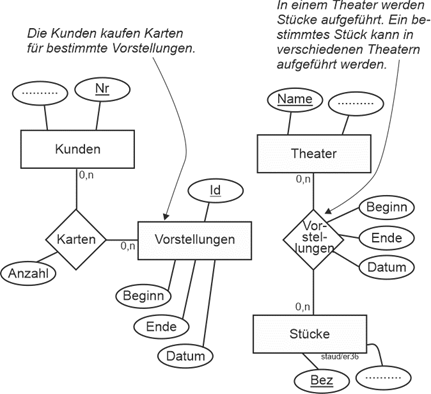
|
|
Abbildung 8.1-1: Entitäts- oder Beziehungstyp?
Quelle: Leicht verändert nach [Stickel 1991, S. 100] |
|
Entitätstyp Kunden mit Schlüssel Kundennummer (Nr) |
|
Entitätstyp Vorstellungen mit Schlüssel Id |
|
Beziehungstyp Karten |
|
Entitätstyp Theater mit Schlüssel Theaterbezeichnung (Bez) |
|
Entitätstyp Stücke mit Schlüssel Bezeichnung des Stücks (Bez) |
|
Beziehungstyp Vorstellungen |
|
8.2 Die Lösung |
|
Ein weiteres theoretisches und grafisches Konstrukt löst dieses Problem. Dieses Theorieelement ist gleichzeitig Entitäts- und Beziehungstyp und kann daher in verschiedenen Bereichen des ER-Modells die jeweiligen Aufgaben erfüllen. Für die grafische Notation werden das Rechteck des Entitätstyps und die Raute des Beziehungstyps übereinander gelegt. |
|
Die folgende Abbildung zeigt ein Beispiel. Da kann dann der Entitäts-/Beziehungstyp Vorstellungen zum einen als Entitätstyp dienen (Kunden – Karten – Vorstellungen), zum anderen als Beziehungstyp (Theater – Vorstellungen – Stücke). |
|
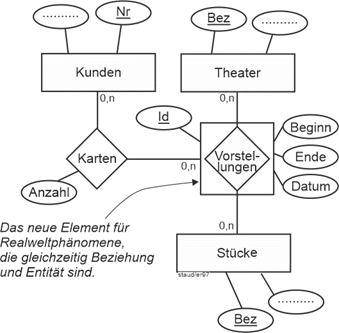
|
|
Abbildung 8.2-1: Entitäts- und Beziehungstyp
Quelle: Leicht verändert nach [Stickel 1991, S. 100] |
|
|
|
|
|
9 „Stolpersteine“ |
|
|
|
9.1 Schlanke Lösung |
|
Im Rahmen einer Entity Relationship - Modellierung gibt es oftmals mehrere Alternativen, die unterschiedlich umfangreich sind, im Grunde aber dasselbe beschreiben. In einem solchen Fall muss immer die einfachste Lösung gewählt werden. |
|
So kann z.B. ein Beziehungstyp oftmals aufgespaltet werden in einen Entitätstyp und zwei weitere Beziehungstypen wie im folgenden Beispiel. |
|
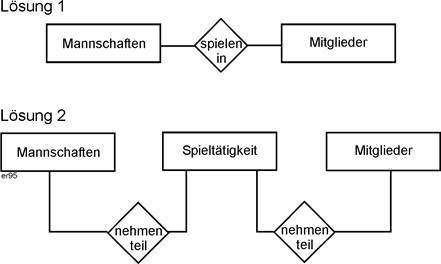
|
|
Abbildung 9.1-1: Richtige („schlanke“) und falsche Lösung |
|
Dies wäre auch eine Lösung für das Problem des vorigen Abschnitts gewesen und hätte die Verwendung des „Kombi-Elements“ überflüssig gemacht. |
|
Im Beispiel der obigen Abbildung ist Lösung 1 die richtige, es sei denn, das Realweltphänomen würde tatsächlich inhaltsmäßig und attributtechnisch ausgebaut, mit Schlüssel und beschreibenden Attributen. Spieltätigkeit müßte dann einen Schlüssel und beschreibende Attribute erhalten. |
|
9.2 Unklare Beziehungen |
|
Vor allem zu Beginn eines Modellierungsprojektes werden oftmals Entitätstypen verknüpft, weil eine vage nebulöse Vorstellung besteht, dass diese zusammenhängen. Mit vagen Vorstellungen lässt sich aber nicht modellieren. Deshalb müssen Beziehungen zwischen Entitätstypen immer daraufhin überprüft werden, ob sie auch semantisch sinnvoll sind, am besten, indem man sie auf ihren Kern, Beziehungen zwischen ganz konkreten Entitäten, zurückführt. |
Beziehungsklärung |
Das folgende Beispiel bezieht sich auf den unten diskutierten Weltausschnitt eines Sportvereins. Da könnte in einer frühen Phase der semantischen Modellierung das folgende Fragment entstanden sein. |
|
|
|
Abbildung 9.2-1: Intuition statt Modellierung |
|
Richtig ist hier allerdings lediglich, dass die Raute natürlich eine Beziehung zwischen den beteiligten Entitätstypen ausdrückt. Bei genauerem Hinsehen erkannt man aber, dass es sich in Wirklichkeit um eine Vielzahl von Beziehungen handelt, die man vielleicht allgemein unter dem Begriff Vereinsgeschehen zusammenfassen könnte. Konkret werden hier so unterschiedliche Beziehungen zusammengefasst wie |
Vereinsgeschehen |
- Mannschaften werden von aktiven Mitgliedern trainiert,
- Mannschaften sind in Abteilungen,
- Mannschaften nehmen an Begegnungen teil.
|
|
Wie kann solch ein Fehler vermieden werden? Ganz einfach, indem man sich über die Natur von Beziehungen in ER-Modellen klar wird. Diese ist ganz einfach (vgl. auch Abschnitt 2.3): |
Beziehungspräzisierung |
Beziehungstypen in ER-Modellen setzen Entitäten des einen Entitätstyps mit Entitäten des anderen Entitätstyps (oder: der anderen Entitätstypen) in Beziehung und sie drücken jeweils NUR EINE Beziehung aus. |
|
Man muss also lediglich auf die Entitäten zurückgehen und mit diesen die Beziehung überprüfen, dann kann eigentlich nichts mehr schief gehen. |
|
9.3 Spezialisierung durch zusammengesetzte Attribute |
|
Oftmals sieht man in ER-Modellen auch „zusammengesetzte Attribute“ (vgl. Abschnitt 2.5), die in Wirklichkeit eine Spezialisierung widerspiegeln. Ein Beispiel zeigt die folgende Abbildung. |
|
Dieser Modellausschnitt ist falsch. Gegen das Attribut aktiv/passiv ist erst mal nichts einzuwenden, auch wenn Vergabe der Attributbezeichnung durch Ausprägungsbezeichnungen nicht sinnvoll ist. Die Attribute Sportart, Leistungsstand und ehrenamtliche Tätigkeit wurden nun aber fälschlicherweise mit dem Attribut aktiv/passiv verknüpft, mit der Absicht, damit die aktiven bzw. die passiven Mitglieder weiter zu beschreiben. |
|
Eine solche Struktur gibt es aber aus guten Gründen in der ER-Modellierung nicht. Attribute dürfen auf solche Weise nur aneinandergehängt werden, wenn es sich tatsächlich um ein zusammengesetztes Attribut im Sinne von Abschnitt 2.5 handelt. |
|
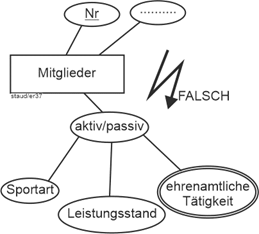
|
|
Abbildung 9.3-1: Falscher "Ausbau" |
|
Die richtige Lösung für diesen fehlerhaften Modellentwurf besteht in der oben beschriebenen Generalisierung / Spezialisierung mit den Entitätstypen Aktive Mitglieder und Passive Mitglieder. Vgl. dazu auch das Sportvereinsbeispiel in Abschnitt 11.5. |
|
9.4 Entitäten versus Attribute |
|
Grundsätzlich kann jedes Attribut dazu dienen, einen Entitätstyp (oder Beziehungstyp) in Teilentitätstypen aufzuspalten, indem man jede Attributsausprägung mit „ihren“ Objekten zu einem eigenen Entitätstyp macht. Nehmen wir aus dem Sportvereinsbeispiel (vgl. Abschnitt 10.2) das Attribut Sportart des Entitätstyps Aktive Mitglieder. Sportart soll zwei Ausprägungen haben, „Handball“ und „Fußball“, wobei es aktive Mitglieder geben soll, die in beiden Sportarten mitwirken. Denkbar wäre dann eine Gen/Spez-Aufspaltung wie in der folgenden Abbildung. |
|
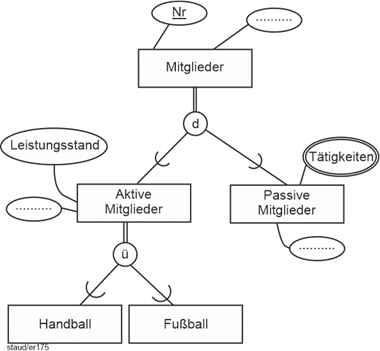
|
|
Abbildung 9.4-1: Attribute vs. Entitätstypen |
|
Mitglieder / Nr: Schlüssel |
|
Aktive Mitglieder / Leistungsstand: Den ein Mitglied erreicht hat |
|
Passive Mitglieder / Tätigkeiten: Die ein Mitglied wahrnehmen kann (mehrere) |
|
Gepunktete Ellipsen: weitere beschreibende Attribute. |
|
Diese Lösung wäre aber falsch, da es keine Entitätstypen ohne Attribute geben kann. Richtig wäre diese Lösung, wenn für die neu eingerichteten Spezialisierungen Handball und Fußball Attribute vorliegen würden. So wie in der nachfolgenden Abbildung. Wie immer deuten die Punkte weitere Attribute an. |
|
Ist dies nicht der Fall, besitzen die Spezialisierungen also keine Attribute, stellt das Spezialisierungskriterium in Wirklichkeit ein Attribut dar. |
|
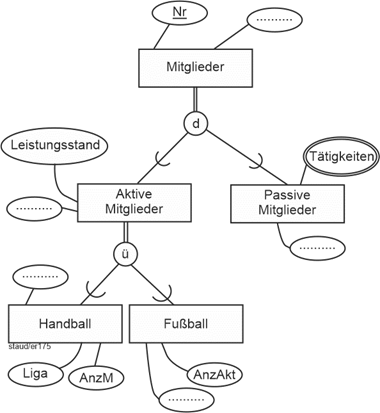
|
|
Abbildung 9.4-2: Spezialisierungen mit Attributen |
|
Handball / Liga: Liga, in der die erste Mannschaft spielt |
|
Handball / AnzM: Anzahl der Mannschaften |
|
Fußball / AnzAkt: Anzahl der aktiven Spieler |
|
Gepunktete Ellipsen: weitere beschreibende Attribute. |
|
Hier ist also oft eine Entscheidung darüber zu treffen, ob eine Information zu einem Attribut oder einem Entitätstyp führt. Konkret bedeutet dies, dass die Eigenschaft entweder in ein Attribut oder – sozusagen in der übergeordneten Ebene – in die Spezialisierung gelegt wird. Die Regel ist hier: keine Spezialisierung, wenn die entstehenden Subklassen keine Attribute mehr haben. |
Regel |
9.5 Verknüpfung von Entitätstypen |
|
Oftmals sieht man in ER-Modellen fehlerhafte Verknüpfungen von Entitätstypen. Deshalb diese Anmerkungen. Verschiedene Entitätstypen können ausschließlich durch folgende Techniken in Beziehung gesetzt werden: |
|
- durch einen Beziehungstyp
- im Rahmen einer Generalisierung / Spezialisierung
- im Rahmen einer Teil_von - Beziehung
|
|
Es ist insbesondere nicht möglich, Entitätstypen direkt zu verknüpfen. Auf die Situation, in der Entitäten gleichzeitig Beziehungen sind, wurde oben eingegangen. |
|
9.6 Konkrete Schritte |
|
Die konkreten Schritte bei der Erstellung von ER-Modellenkönnen wie folgt zusammengefasst werden: |
Schritte bei der ER-Modellierung |
- Sammeln: Entitäten, Beziehungen und Attribute erkennen.
- Strukturieren I: Beziehungen, Entitäten, Generalisierungen / Spezialisierungen und andere Muster abklären.
- Strukturieren II: Attribute zuordnen, Typen bilden. Von großer Bedeutung ist hier die Beachtung des Zusammenhangs zwischen Attributen und Entitäten bzw. Beziehungen (Zuordnungsregel).
- Modellieren: Weitere Präzisierung von Entitäts- und Beziehungstypen – im Kontext. Hier geht es u.a. darum, "vergessene" Beziehungstypen zu entdecken.
|
|
Die hier vorgestellte grafische Notation orientiert sich am Original und am „Mainstream“. Es soll aber nicht verschwiegen werden, dass es, vor allem in den nicht-elementaren Teilen, zahlreiche Variationen gibt. |
Hinweis |
|
|
|
|
10 Überführung eines ER-Modells in ein relationales Datenmodell |
|
Die Übertragung von ER-Modellen in Relationale Modelle dürfte in der Praxis sehr oft vorkommen. Der Grund ist einfach. Am Anfang der Datenmodellierung, nach der konzeptionellen Phase, wird meist ein Semantisches Datenmodell erstellt und dies ist heute in der Regel ein ER-Modell. Da das zur Verfügung stehende Datenbanksystem heute fast immer ein relationales ist, wird das ER-Modell vor der Einrichtung der Datenbank in ein relationales Datenmodell übertragen. |
|
Das ist der Grund, weshalb hier einige Hinweise auf diesen (nicht schwierigen) Transformationsprozess gegeben werden. Dabei werden v.a. die Attribute, insbesondere die der Beziehungen, präzisiert. Aus semantischen Verbindungen zwischen Entitäten werden attributbasierte relationale Verknüpfungen mit Schlüsseln und Fremdschlüsseln. Darüber hinaus gibt es aber noch mehr zu tun, um die semantischen Konstrukte der ER-Modellierung in die „logischen“ der relationalen Theorie abzubilden. |
Von „semantisch“ zu „relational“ |
Vgl. für eine umfassende Einführung in die relationale Theorie [Staud 2021]. |
|
|
|
10.1 Entitätstypen |
|
Entitätstypen ohne mehrwertige Attribute werden in eine einzelne eigene Relation überführt. Im folgenden Modellfragment wird angenommen, dass das Attribut Name auch Schlüsselcharakter hat. |
Ohne mehrwertige Attribute |
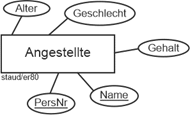
|
|
Abbildung 10.1-1: Entitätstyp mit Attributen |
|
Das Beispiel der Abbildung wird damit zu genau einer Relation: |
|
Angestellte (#PersNr, #Name, Alter, Geschlecht, Gehalt) |
|
Die folgende Abbildung zeigt die Sonderfälle zusammengesetzte Attribute, abgeleitete Attribute und mehrwertige Attribute. |
Attributsonderfälle |
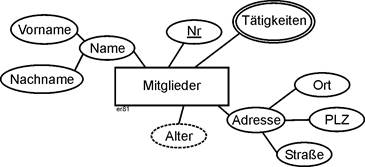
|
|
Abbildung 10.1-2: Attributsonderfälle |
|
Diese Attributsonderfälle werden wie folgt in relationale Datenmodelle abgebildet: |
|
- Bei zusammengesetzten Attributen werden nur die "äußersten" Attribute übernommen. Die Information, dass die Attribute etwas zusammen modellieren, dass sie „zusammengehören“, geht verloren. Hier bleiben also Ort, PLZ und Straße sowie Nachname und Vorname übrig.
- Abgeleitete Attribute können nicht direkt modelliert werden. Bei vielen Datenbanksystemen ist es allerdings möglich, im Rahmen der Einrichtung der Datenbank, ein solches "berechnetes" Attribut anzulegen.
- Jedes mehrwertige Attribut wird zu einer eigenen Relation, entsprechend der Behandlung mehrwertiger Attribute im relationalen Ansatz.
|
|
Aus dem obigen ER-Modell werden damit die folgenden zwei Relationen: |
|
Mitglieder (#Nr, Nachname, Vorname, PLZ, Ort, Straße) |
|
Mitgliedertätigkeiten (#(Nr, Tätigkeit)) |
|
10.2 Beziehungstypen |
|
Beziehungstypen werden unterschiedlich modelliert, je nach der Kardinalität und dem Min-/Max-Wert der Beziehung. Betrachten wir dazu nochmals das ER-Modell aus dem Weltausschnitt Datenbanksysteme (vgl. Abbildung 4.1-1). Hier wird zwischen einer technischen Beschreibung der Datenbanksysteme und einer preislichen unterschieden. Der Grund soll hier sein, dass die technischen Informationen immer erhoben werden, die kaufmännischen aber nur für einen Teil der Datenbanksysteme. Diese Situation könnte, so wie hier in der folgenden Abbildung, zur Bildung zweier Entitätstypen geführt haben, die durch eine 1:1 - Beziehung T_P verknüpft sind. |
Situation und Beispiel |
Außerdem wird zwischen Produzenten und DBS_T eine 1:n- und zwischen Datentypen und DBS_T eine n:m - Beziehung angenommen. |
|

|
|
Abbildung 10.2-1: Drei Kardinalitäten in einem Modellfragment |
|
Entitätstyp DBS_P: Datenbanksysteme / Preisinformation |
|
Entitätstyp DBS_T: Datenbanksysteme / Technische Information |
|
LPreis: Listenpreis |
|
MaxZahlDs: Maximale Anzahl der Datensätze, die das Datenbanksystem verwalten kann |
|
Typ: Typ des Datentyps: numerisch, alphanumerisch, … |
|
Für die Übertragung in ein relationales Modell wird zuerst für jeden Entitätstyp eine Relation angelegt: |
|
Produzenten (#ProdNr, Name) |
|
Datentypen (#Bezeichnung, Typ) |
|
DBS_T (#Bezeichnung, MaxZahlDs) |
|
DBS_P (#Bezeichnung, LPreis, KostenWartung) |
|
Für jede n:m - Beziehung muss (unabhängig von den Kardinalitäten) bei der Übertragung eine eigene Relation angelegt werden, so also auch hier für den Beziehungstyp DBS_T: |
Lösung für
n zu m |
DBS_T_Typ (#(BezeichnungDB, BezeichnungDatentyp)) |
|
Die semantische Beziehung ist damit mit Hilfe der Attribute geklärt. |
|
Alle 1:n - Beziehungen werden in eine Schlüssel/Fremdschlüssel - Beziehung übertragen. Hier muss also die Relation DBS_T ergänzt werden um den Schlüssel von Produzenten: |
Lösung für
1 zu n |
DBS_T (#Bezeichnung, MaxZahlDs, ProdNr) |
|
Bei 1:1 - Beziehungen ist die Regellösung die, dass einer der beiden Schlüssel als Fremdschlüssel in die andere Relation genommen wird. Mit obigem Beispiel T_P und der Annahme, dass es sich um eine Pflichtbeziehung handelt (beide Min-/MAX-Angaben also 1,1 sind), ergeben sich folgende möglichen Lösungen: |
Lösung für
1 zu 1 |
DBS_T (#Bez_T, MaxZahlDs, Bez_P) |
|
Oder |
|
DBS_P (#Bez_P, LPreis, KostenWartung, Bez_Teichnung (von DBS_T)) |
|
DBS_T und DBS_P sind hier bei jeder Beziehung identisch. Die unterschiedlichen Bezeichnungen wurden nur aus didaktischen Gründen gewählt. |
|
Insgesamt ergibt sich dann das folgende relationale Datenmodell: |
|
Produzenten (#ProdNr, Name) |
|
Datentypen (#Bezeichnung, Typ) |
|
DBS_T (#Bezeichnung, MaxZahlDs, ProdNr, Bez_P) |
|
DBS_P (#Bezeichnung, LPreis, KostenWartung) |
|
DBS_T_Typ (#(BezeichnungDB, BezeichnungDatentyp)) |
|
Es gibt allerdings Sonderfälle entlang der verschiedenen Varianten der 1 zu 1 - Bedingung, die unterschiedlich gelöst werden müssen. Die folgende Abbildung zeigt die Varianten: |
Sonderfälle |
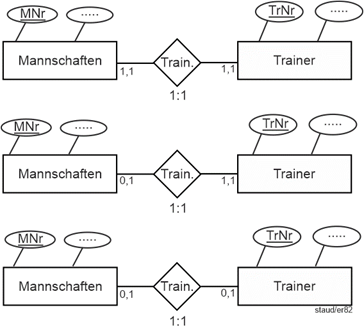
|
|
Abbildung 10.2-2: Min-/Max-Angaben |
|
Die vierte mögliche wurde weggelassen, weil sie strukturell mit der zweiten identisch ist. |
|
Im ersten Beispiel wird auf beiden Seiten von einer Min-/Max-Angabe des Typs "1,1" ausgegangen. Dies bedeutet, dass es für jede Mannschaft einen Trainer gibt und für jeden Trainer eine Mannschaft. Das ist die Regelsituation, wie oben schon beschrieben. Sie wird einfach so modelliert, dass in einer der beiden Relationen der Schlüssel der anderen als Fremdschlüssel eingefügt wird, also z.B. so: |
|
Mannschaften (#MNR, TrNr, ...) |
|
Trainer (#TrNr, ...) |
|
Im zweiten Beispiel liegt auf einer Seite die Min-/Max-Angabe "0,1" vor. Dies bedeutet: Eine Mannschaft kann, muss aber nicht einen Trainer haben. Umgekehrt blieb es bei der Angabe "1,1". Hier ist also den Trainern immer eine Mannschaft zugeordnet, nicht aber den Mannschaften ein Trainer. In einer solchen Situation muss der Relation mit der Min-/Max-Angabe "1,1" der Schlüssel der anderen als Fremdschlüssel hinzugefügt werden. Hier also: |
|
Mannschaften (#MNR, ...) |
|
Trainer (#TrNr, MNr, ...) |
|
Im untersten Fall liegt auf beiden Seiten die Min-/Max-Angabe "0,1" vor. Dies bedeutet bei einer Fremdschlüssellösung, dass auf jeden Fall semantisch bedingte Leereinträgeentstehen. D.h., nicht Leereinträge, die durch fehlende Angaben entstehen, sondern solche, die dadurch entstehen, weil es die entsprechende Information einfach nicht gibt. In einem solchen Fall ist die Anlage einer eigenen Relation sinnvoll, in der die Schlüssel der beiden Relationen jeweils auch Schlüssel sind: |
|
Mannschaften (#MNR, ...) |
|
Trainer (#TrNr, ...) |
|
Mannschaften_Trainer (#MNr, #TrNr)) |
|
Weil dieser Tatbestand beim Lernen erfahrungsgemäß Probleme bereitet, hier die tabellarische Darstellung. Es gibt vier Mannschaften und drei Trainer. Zwei der Trainer sind für zwei Mannschaften eingesetzt. Die übrigen Trainer und Mannschaften sind nicht in einem Trainingsverhältnis. Die Relation Mannschaften_Trainer zeigt, dass in einer solchen Situation tatsächlich beide Attribute Schlüsselcharakter haben. |
|
Mannschaften |
|
| #MNr |
..... |
| M123 |
..... |
| M234 |
..... |
| M345 |
..... |
| M456 |
..... |
| |
|
|
Trainer |
|
| #TrNr |
..... |
| T010 |
..... |
| T009 |
..... |
| T007 |
..... |
| |
|
|
Mannschaften_Trainer |
|
| #TrNr |
#MNr |
| T010 |
M123 |
| T007 |
M345 |
| |
Diese Lösung erinnert an die Verbindungsrelation bei n:m - Beziehungen, hat aber eine andere Ursache. Da in der neuen Relation jeder Mannschaftsname und auch jede Trainernummer nur einmal vorkommen kann, können beide als Schlüssel dienen. Durch ihre verbindende Funktion mit Mannschaften bzw. Trainer sind sie gleichzeitig auch Fremdschlüssel.
|
|
10.3 Singuläre Entitätstypen |
|
Situation und Beispiel |
|
Singuläre Entitätstypen spiegeln so etwas wie Existenzabhängigkeit eines Entitätstyps von einem anderen wider. Damit beruhen sie auf einer Beziehung, die auf einer Seite eine Min-/Max-Angabe mit einem unteren Wert von "1" haben muss, da auf dieser Seite jede Entität an der Beziehung teilnimmt. Die folgende Abbildung zeigt ein Beispiel. |
Vgl. Abschnitt 2.4 |
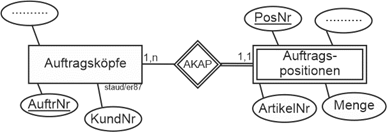
|
|
Abbildung 10.3-1: Singulärer Entitätstyp Auftragspositionen |
|
Lösung |
|
Die Umsetzung erfolgt so, dass für die beiden Entitätstypen Relationen angelegt werden, wobei – und das ist typisch für singuläre Entitätstypen mit ihren Existenzabhängigkeiten – der Schlüssel der Relation, die aus dem singulärem Entitätstyp hervorging, um den Schlüssel der anderen ergänzt wird [Anmerkung] . Hier also: |
|
Auftragsköpfe (#AuftrNr, KundNr, ...) |
|
Auftragspositionen (#(AuftrNr, PosNr), ArtikelNr, Menge, ...) |
|
Damit ergibt sich – wiederum typischerweise – in der „singulären“ Relation ein zusammengesetzter Schlüssel mit einem Fremdschlüssel, der dem Schlüssel der anderen entspricht. |
|
Weitere Beispiele |
|
Das folgende Beispiel macht dies nochmals deutlich. Es stammt aus dem in Abschnitt 11.5 diskutierten Sportvereinsbeispiel. |
|
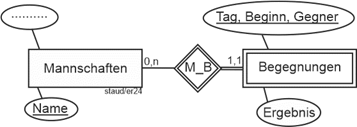
|
|
Abbildung 10.3-2: Singulärer Entitätstyp Begegnungen |
|
Der singuläre Entitätstyp hat den Schlüssel „Tag, Beginn, Gegner“, weil die Mannschaften des Vereins an einem bestimmten Tag zu einer bestimmten Uhrzeit gegen einen bestimmten Gegner spielen. Ohne den Namen der Mannschaft unseres Vereins wäre der Schlüssel aber unvollständig. Somit ergibt sich: |
|
Mannschaften (#Name, ...) |
|
Begegnungen (#(NameMannschaft, Tag, Beginn, Gegner), Ergebnis) |
|
Oftmals werden aber in ER-Modellen bereits eigenständige Schlüssel für den singulären Entitätstyp eingeführt. Dies entspricht nicht der Philosophie des ER-Ansatzes, weil damit modelltechnisch die Existenzabhängigkeit beseitigt wird, obwohl sie semantisch natürlich weiterhin vorhanden ist. Die folgende Abbildung zeigt ein Beispiel. |
|
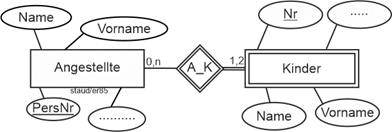
|
|
Abbildung 10.3-3: Singulärer Entitätstyp Kinder |
|
An der Umsetzung ändert dies nichts, der Schlüssel des singulären Entitätstyps muss in der entstehenden Relation um den Schlüssel des anderen Entitätstyps ergänzt werden. |
|
Hier wurde also für jedes Kind ein unabhängiger Schlüssel eingeführt. Außerdem erfordert hier die Semantik, da mindestens ein Elternteil und maximal zwei im Unternehmen sein können, eine Min-/Max-Angabe von „1,2“ bei dem singulären Entitätstyp Kinder. In einem solchen Fall wird die Übertragung in das relationale Modell einfach so wie oben für Beziehungen allgemein vorgenommen. |
|
Es entsteht je eine Relation für Angestellte und Kinder. Der Beziehungstyp wird gemäß den oben eingeführten Regeln für Beziehungstypen umgesetzt. Liegt bei der singulären Objektklasse eine 1,1-Angabe vor, wird in "ihre" Relation der Schlüssel der anderen Relation als Fremdschlüssel eingefügt. Liegt, so wie hier oben, "1,2" vor und auf der "anderen Seite" ein unterer Wert von 0, wird eine eigene Relation für die Verknüpfung eingerichtet. Hier somit: |
|
Angestellte (#PersNr, ...) |
|
Kinder (#Nr, Name, VName, ...) |
|
A_K (#(PersNr, KinderNr)) |
|
Für alle obigen Fälle gilt im Übrigen, dass die Eigenschaft der Singularität im relationalen Datenmodell nicht mehr direkt erkannt werden kann. |
|
10.4 Mehrstellige Beziehungen |
|
Mehrstellige Beziehungen wie sie die folgende Abbildung zeigt, werden so aufgelöst, dass für jeden Entitätstyp und für den Beziehungstyp je eine eigene Relation entsteht. In die so entstehende Verbindungsrelation werden die Schlüssel der beteiligten anderen Relationen als Fremdschlüssel aufgenommen. |
|
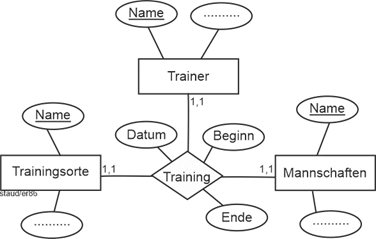
|
|
Abbildung 10.4-1: Dreistellige Beziehungen |
|
Vgl. auch Abschnitt 4.2 |
|
Hier entsteht somit: |
|
Trainer (#Name, ...) |
|
Trainingsort (#Name, ...) |
|
Mannschaften (#Name, ...) |
|
Training (#(TrainerName, TrOrtName, MannschName), Datum, Beginn, Ende) |
|
Sind die Min-/Max-Angaben nicht 1,1 wird bei der Schlüsselbildung entsprechend dem relationalen Regelwerk verfahren. |
|
10.5 Generalisierung / Spezialisierung |
|
Situation, Beispiel und erste Lösung |
|
Eine Generalisierung / Spezialisierung kann auf verschiedene Weise übertragen werden. Die Variante, die der relationalen Philosophie am nähesten kommt, ist die folgende: Aus dem generalisierten Entitätstyp und aus allen Spezialisierungen wird jeweils eine Relation. Das folgende Beispiel möge dies verdeutlichen. |
|
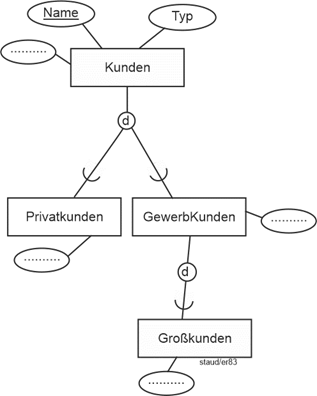
|
|
Abbildung 10.5-1: Generalisierung / Spezialisierung bzgl. Kunden |
|
Der Entitätstyp Kunden ist hier spezialisiert in Privatkunden und GewerbKunden (gewerbliche Kunden), letztere dann noch in Großkunden. Damit entstehen folgende Relationen: |
|
Kunden (#Name, Typ, ...) |
|
Privatkunden (#Name, ...) |
|
GewerbKunden (#Name, ...) |
|
Grosskunden (#Name, ...) |
|
Die Punkte stehen für weitere Attribute. Im Fall der Relation Kunden für solche, die alle Kunden gemeinsam haben, bei den anderen für die jeweils spezifischen Attribute. Die Schlüssel der Relationen, die Spezialisierungen darstellen, sind gleichzeitig auch Fremdschlüssel. Dies entspricht nicht der üblichen relationalen Verknüpfung, ist aber unvermeidbar. Hier gilt nicht, dass es für jede Ausprägung des Schlüssels eine oder mehrere Ausprägungen des Fremdschlüssels gibt, sondern dass die Menge der Ausprägungen des Schlüssels in der „Generalisierungsrelation“ die Ausprägungen der anderen enthält und dass es für jede Schlüsselausprägung in der „Generalisierungsrelation“ genau eine Ausprägung in einer der Spezialisierungen gibt. |
Fremdschlüssel besonderer Art |
Das relationale Modell enthält damit nicht mehr die Information, dass es sich um eine Generalisierung / Spezialisierung handelt. Diese Information muss über die Anwendung in das System gebracht werden. |
|
Die zweite Lösung für die Übertragung einer Generalisierung / Spezialisierung besteht darin, für jede Spezialisierung eine Relation anzulegen, die zusätzlich zu den spezifischen Attributen auch die allgemeinen enthält. Für die Generalisierung wird keine Relation angelegt. Im obigen Beispiel entstünden damit folgende Relationen: |
Zweite Lösung |
Privatkunden (#Name, "allgemeine Attribute", "spezifische Attribute") |
|
GewerbKunden (#Name, "allgemeine Attribute", "spezifische Attribute") |
|
Grosskunden (#Name, "allgemeine Attribute", "Attribute von GewerbKunden", "spezifische Attribute") |
|
Hier wurde eine totale Beteiligung angenommen, d.h., die Spezialisierungen decken alle Entitäten der Generalisierung ab. Liegt keine totale Beteiligung vor, ist diese Lösung nicht geeignet. |
|
Die dritte Lösung besteht darin, eine einzige Relation zu erstellen, die alle Attribute enthält. Im Beispiel: |
Dritte Lösung |
Kunden (#Name, Typ, "allgemeine Attribute Kunden", "spezifische Attribute Privatkunden", "spezifische Attribute GewerbKunden", "spezifische Attribute Großkunden") |
|
Eine solche Relation ist allerdings nicht für effizientes Arbeiten geeignet, denn die Attribute beziehen sich ja, bis auf die allgemeinen, nur jeweils auf eine Auswahl der Tupel. |
|
|
|
11 Beispiele für ER-Modellierung |
|
Mit den folgenden Beispielen sollen ER-Modelle vorgestellt werden. Bei einigen Beispielen auch, indem der Entstehungsprozess gezeigt wird – seine Entwicklung „Schritt um Schritt“. In vollem Umfang, mit allen Einzelschritten und an einem realen Beispiel ist dies aus Platzgründen nicht möglich. Trotzdem sollten die Beispiele einen Eindruck davon geben, wie der "semantische Abschnitt" des Datenbankdesigns aussieht. |
|
In der ER-Modellierung ist es in dieser Phase sehr wichtig, den Zusammenhang zwischen Objekten/Beziehungen (hier: Entitäten) und Attributen ganz genau zu erfassen: |
|
- Regel 1: Nur die Attribute werden einer Entität zugewiesen, die genau diese Entität beschreiben (im Kontext der jeweiligen Aufgabe). Genauso für Beziehungen.
- Regel 2: Nur die Entitäten, die genau durch dieselben Attribute beschrieben werden, kommen zusammen in einen Entitätstyp. Dann beschreiben alle Attribute eines Entitätstyps auch alle Entitäten des Typs. Genauso für Beziehungen.
|
|
Kommt es doch zu Verletzungen dieser Regel, muss entsprechend gehandelt werden, z.B. durch eine Zerlegung im Rahmen einer Generalisierung / Spezialisierung. |
|
Übrigens: Obige Regeln sichern die effiziente Modellstruktur, die der relationalen Theorie durch die Normalformen herbeigeführt wird. |
|
|
|
11.1 Rechnungsstellung |
|
Zu diesem Beispiel gibt es: Aufgabenstellung + Lösungsweg |
|
Diese Aufgabenstellung wird auch in [Staud 2021, Abschnitt 16.1] bearbeitet. Das dort entstandene relationale Datenmodell ist inhaltlich weitgehend mit dem hier vorliegenden ER-Modell identisch. |
|
Mit diesem Beispiel wird die Erstellung eines ER-Modells für den Zweck der Rechnungsstellung gezeigt. Ausgangspunkt ist dabei die in der folgenden Abbildung angegebene Rechnung
, also ein Geschäftsobjekt (business object), was in der Datenmodellierung durchaus oft der Fall ist. Es gelten – neben der üblichen kaufmännischen Semantik von Rechnungen – die folgenden Bedingungen und semantischen Festlegungen: |
Rechnungen |
- Die Kunden werden mit Namen (Name), Vornamen (VName) und Anrede erfasst. Außerdem wird ein identifizierendes Attribut (KuNr) angelegt.
- Ein Kunde wird zuerst mit nur einer Adresse erfasst. Später dann mit beliebig vielen.
- Ein Kunde kann mehrere Telefonanschlüsse haben.
- In der Datenbank wird auch festgehalten, wer die Kundschaft bedient hat (Verkäufer). Dies wird auf der Rechnung ausgegeben.
- TOUR bezeichnet das Auslieferungsteam (Tour).
- KVDAT gibt den Tag an, an dem die Kundschaft im Möbelhaus war und die Ware bestellt hat (Kvdat).
- Eine Rechnung bezieht sich auf genau einen Auftrag
- Die angegebene Telefonnummer ist die der Rechnungsanschrift
|
|
Die Abkürzungen bei Position 1 bedeuten: |
|
|
889999: Artikelnummer (ArtNr)
|
|
|
B/00/EG: Standort der Ware im Lager (Standort)
|
|
|
COUCHTISCH 1906 EICHE NATUR - MIT LIFT 125x71 cm: Artikelbezeichnung (ArtBez)
|
|

|
|
Abbildung 11.1-1: Geschäftsobjekt Rechnung (Typ Möbelhaus) |
|
Diese Aufgabe wird mit unterschiedlichen Komplexitätsgraden in drei Stufen gelöst: |
|
- Aufgabe Stufe 1 – Grundstruktur: Für jeden Kunden wird nur eine Anschrift, die Rechnungsanschrift, erfasst. Es wird keine zeitliche Dimension berücksichtigt, d.h. alte Rechnungen müssen nicht aus der Datenbank heraus reproduzierbar sein.
- Aufgabe Stufe 2 – Beliebige Rechnungs- und Lieferadressen: Für jeden Kunden werden beliebig viele Adressen erfasst. Bei jedem Kauf kann ein Kunde eine beliebige seiner Adressen als Lieferadresse bzw. als Rechnungsadresse angeben.
- Aufgabe Stufe 3 – Zeitachse: Einfügen einer zeitlichen Dimension. Die Rechnungen sollen über die Zeit gerettet werden, d.h. es soll möglich sein, beliebige Rechnungen der Vergangenheit aus der Datenbank heraus zu reproduzieren. Also z.B. eine Rechnung vom 20. November 2012 mit den damaligen Preisen, der damaligen Mehrwertsteuer, usw.
|
|
11.1.1 Stufe 1 |
|
Für die Stufe 1 sammeln wir zuerst die Attribute ein und bestimmen dann die Entitätstypen. Wie immer gilt: |
|
Zu einem Entitätstyp gehören die Attribute, die ihn identifizieren und beschreiben und die für alle Entitäten des Typs gültig sind. |
Zuordnungsregel |
Nun die Attribute: |
|
- Name: des Kunden
- VName
- PLZ: der Rechnungsanschrift
- Ort
- Straße
- Tel: Telefonnummer. Ein Kunde kann mehrere haben.
- KuNr: Kundennummer. Diese ergänzen wir gleich, da die Erfassung der Kunden ohne eine Kundennummer nicht sinnvoll ist.
- ReNr: Rechnungsnummer. Diese identifiziert Rechnungen.
- ReDatum: Rechnungsdatum
- Verkäufer: die Angabe des Verkäufers erfolgt auf der Rechnung
- KVDAT: Hierbei handelt es sich um das Kaufvertragsdatum.
- Tour: Bezeichnung des Teams, das mit seinem Fahrzeug die Möbel ausliefert. Eine tiefere Semantik liegt nicht vor.
- PosNr: Rechnungspositionsnummer
- ArtNr: Artikelnummer. Eindeutig für die Artikel. Wurde ergänzt als Schlüssel für die Artikel.
- Anzahl der Artikel pro Position
- Standort: Standort der Ware im Lager.
- ArtBez: Artikelbezeichnung
- ZV: Zahlungsvereinbarung
- LiPreis: Listenpreis. Der Preis für die gesamte Position wird berechnet aus Anzahl und Preis.
|
|
Für die meisten Artikel liegt noch eine Beschreibung vor (Beschr), die aber nicht auf der Rechnung ausgegeben wird. Der Mehrwertsteuersatz wird im Programm hinterlegt, der Mehrwertsteuerbetrag (MWStB) wird dann daraus und aus der Rechnungssumme berechnet. |
|
Was kann man nun, auch unter Berücksichtigung der ja immer vorliegenden Objekt-/Beziehungsstruktur, von den Attributen ableiten? Problemlos zu erkennen sind die Kunden: als Entitäten und als Entitätstypen. Identifiziert werden sie durch die KuNr. Folgende weitere Attribute beschreiben alle Kunden: |
Entitäten und Entitätstypen finden |
- Name
- VName
- Anrede
- PLZ
- Ort
- Straße
- Tel (mehrwertig)
|
|
Für die Adressangaben gilt dies nur, weil wir uns in Stufe 1 mit einer einzigen Rechnungsanschrift begnügen. Die Erfahrung hat gezeigt, dass jeder Kunde mehrere Telefonanschlüsse haben kann. Deshalb werden die Telefonnummern als mehrwertiges Attribut erfasst. |
|
Damit ergibt sich der erste Entitätstyp Kunden (vgl. auch die folgende Abbildung). |
|
|
|
Abbildung 11.1-2: Rechnungsstellung, Fragment Entitätstyp Kunden |
|
Tel: mehrwertiges Attribut |
|
Rechnungskopf vs. Rechnungspositionen |
|
Ähnlich einfach ist das Erkennen der Rechnung als Modellelement. Bei genauerem Hinsehen erkennt man aber, dass es eine Unterscheidung geben muss zwischen dem Rechnungskopf (identifiziert durch die Rechnungsnummer (ReNr)) und den Rechnungspositionen. Denn es gibt pro Rechnung mehrere Positionen, so dass sich einige Attribute auf die Rechnung als Ganzes, andere auf die Positionen der Rechnung beziehen. Folgende Attribute liegen zur Rechnung vor: |
|
- ReDatum: Es gibt genau ein Rechnungsdatum pro Rechnung und jede Rechnung hat ein Rechnungsdatum.
- Verkäufer: Durch Nachfragen wurde ermittelt, dass immer nur einer für einen Kaufvertrag zuständig ist und nur einer auf der Rechnung erscheint.
- Tour: Es gibt ein Auslieferungsteam je Rechnung.
- KVDAT: Kaufvertragsdatum, genau eines je Rechnung.
- ZV: Zahlungsvereinbarung, die je Rechnung eindeutig ist. Trotz Nachfragen konnte auch keine weitere Semantik (z.B. Abhängigkeit vom gekauften Produkt) festgestellt werden.
|
|
Ergänzt man noch das Rechnungsdatum (ReDatum), das Datum der Lieferung (DatumLief) und den Mehrwertsteuerbetrag (MWStB) ergibt sich der Entitätstyp ReKöpfe für die Rechnungsköpfe. |
|
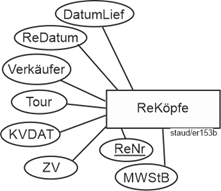
|
|
Abbildung 11.1-3: Rechnungsstellung, Fragment Entitätstyp Rechnungsköpfe |
|
Für die Rechnungspositionen wird ein Entitätstyp RePos eingerichtet. Zu ihm gehören die Attribute PosNr und Anzahl, evtl. auch die Artikelnummer. Da wir aber erkennen, dass die Artikel als eigener Entitätstyp eingerichtet werden müssen
(vgl. unten), denken wir schon voraus und lassen die ArtNr hier weg. RePos ist ein singulärer Entitätstyp, da die Existenz jeder Rechnungsposition von der Existenz des zugehörigen Rechnungskopfes abhängt. Dazu unten mehr bei der Betrachtung der Beziehungstypen. Datenbanktechnisch bedeutet das im übrigen, dass bei Löschung eines Rechnungskopfes automatisch alle zugehörigen Rechnungspositionen gelöscht werden sollten, damit die Datenbank integer bleibt. |
Rechnungspositionen |

|
|
Abbildung 11.1-4: Rechnungsstellung, Fragment singulärer Entitätstyp Rechnungspositionen |
|
Doppellinie: Kennzeichnung singulärer Entitätstypen |
|
Der letzte leicht erkennbare Entitätstyp sind die Artikel. Auch sie werden identifiziert (ArtNr), haben eine Bezeichnung (ArtBez) und werden beschrieben. Allerdings liegt nicht zu jedem Artikel eine Beschreibung vor. Gemäß der Zuordnungsregel („jedes Attribut muss auf alle Entitätstypen anwendbar sein“), müssen wir damit die Artikel mit Beschreibungen in einen eigenen Entitätstyp tun (ArtBeschr). Damit ergeben sich die folgenden Fragmente. |
Artikel und Beschreibung |
|
|
Abbildung 11.1-5: Rechnungsstellung, Fragment Entitätstyp Artikel |
|
|
|
Abbildung 11.1-6: Rechnungsstellung, Fragment Entitätstyp Artikelbeschreibung |
|
Für die Artikel mit Beschreibung wird also ein eigener Entitätstyp angelegt, da es sich um eine Teilmenge aller Artikel handelt, um die mit einem zusätzlichen Attribut. Dieses Fragment ist didaktisch motiviert. Näheres vgl. unten bei der Betrachtung des Beziehungstyps zwischen den beiden Entitätstypen. |
Alternativer Weg. |
Oftmals wird der Zusammenhang von Rechnung und Artikel auf andere Weise erfasst. Da es typischerweise pro Rechnung mehrere Artikel gibt und die Artikel auch auf mehreren Rechnungen auftauchen (ein bestimmtes Sofa, das hundert mal verkauft wurde) wird dabei dann zuerst ein Beziehungstyp zwischen Rechnungsköpfen und Artikeln eingerichtet und diesem die PosNr als beschreibendes Attribut zugeordnet. |
|
Obiges macht nochmals deutlich: Die Findung der Entitätstypen erfolgt über die Attribute. Wenn man hier die Zuordnungsregel sehr genau beachtet, erhält man Modellfragmente, die absolut redundanzfrei sind und die im relationalen Fall der 5NF entsprechen. |
Finden der Entitätstypen |
Die Beziehungstypen |
|
Rechnungsköpfe und Rechnungspositionen stehen in einer Beziehung. Sie ist, von den Rechnungspositionen aus gesehen, sogar existenziell. Wie oben schon ausgeführt, ist RePos ein singulärer Entitätstyps bzgl. ReKöpfe. Deshalb werden die beiden Entitätstypen durch einen Beziehungstyp (R/R) verbunden, die Doppellinie drückt die Abhängigkeit aus. Die Min-/Max-Angaben ergeben sich mit 1,n bei den Rechnungsköpfen (jede Rechnung hat mindestens eine Rechnungsposition) und 1,1 bei den Rechnungspositionen (jede Rechnungsposition gehört zu genau einer Rechnung). |
Rechnung |
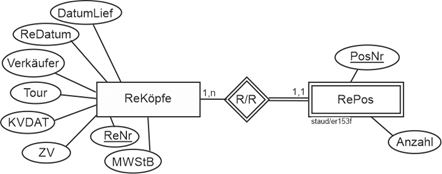
|
|
Abbildung 11.1-7: Rechnungsstellung, Fragment Rechnungsköpfe – Rechnungspositionen |
|
Zwischen Kunden und ReKöpfe liegt ebenfalls eine Beziehung vor. Für diese gilt: Ein Kunde hat u.U. viele Rechnungen mit dem Unternehmen, aber eine Rechnung bezieht sich immer nur auf einen Kunden. Diese 1:n - Beziehung führt zu einem Beziehungstyp K_RK. Die Min-/Max-Angaben sind wie folgt: |
Kunden und Rechnungsköpfe |
- 1,n bei den Kunden, weil wir nur Kunden erfassen, die mindestens eine Rechnung bei uns erzeugt haben. Diese könnte auch anders sein, wenn z.B. für Marketingaktionen potentielle Kunden aufgenommen würden, Dann wäre die Min-/Max-Angabe 0,n.
- 1,1 bei ReKöpfe, denn jeder Rechnungskopf bezieht sich auf genau einen Kunden.
|
|
Damit ergibt sich folgender Beziehungstyp: |
|
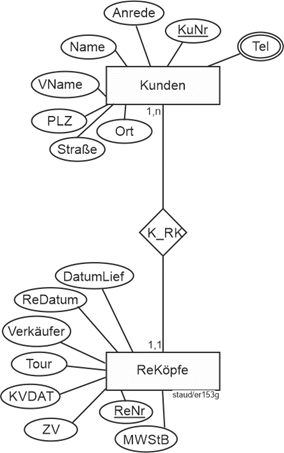
|
|
Abbildung 11.1-8: Rechnungsstellung, Fragment Kunden – Rechnungsköpfe |
|
Zwischen Kunden und Artikel gibt es semantisch natürlich eine Beziehung und – wie oben ausgeführt – wäre auch eine Modellierung mit einem Beziehungstyp Kunden-Artikel möglich. Es käme das gleiche Ergebnis raus. Hier greift aber die „kaufmännische Tiefensemantik“ („eine Rechnung hat Positionen“) ein und empfiehlt die Modellierung über einen Entitätstyp RePos. Insgesamt also von ReKöpfe zu RePos und dann zu Artikel. |
Kunden
und Artikel |
Damit ergibt sich hier ein Beziehungstyp zwischen Rechnungspositionen und Artikel (A_RP) mit einer 1:n - Beziehung. Ein Artikel kommt hoffentlich auf vielen Rechnungspositionen vor und eine Rechnungsposition erfasst genau einen Artikel. Die Min-/Max-Angabe von 1,1 auf der Seite der Rechnungspositionen ist hier besonders sinnvoll, denn es hat keinen Sinn, Rechnungspositionen ohne Artikel zu erfassen. Bei den Artikeln ist 0,1 sinnvoll, denn es gibt sicherlich Artikel, die auf vielen Positionen auftauchen, andererseits gibt es auch welche, die noch nicht verkauft wurden. |
Rechnungspositionen und Artikel |
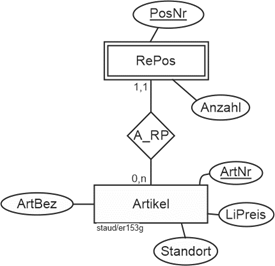
|
|
Abbildung 11.1-9: Rechnungsstellung, Fragment Rechnungspositionen – Artikel |
|
Bleibt noch der Beziehungstyp für „Artikel – Artikel mit Beschreibung“. Hier geht es darum, dass das Attribut Beschr (Beschreibung des Artikels) nicht für alle Artikel vorhanden ist. Würden wir Beschr daher bei Artikel hinzufügen, gäbe es Entitäten, für die dieses Attribut keine Ausprägung hätte. Dies widerspricht der Zuordnungsregel, weshalb ein eigener Entitätstyp für die Artikel mit Beschreibung eingerichtet wurde. Wie sieht die Beziehung aus? Diese kann als ganz normaler Beziehungstyp angelegt werden, so wie hier mit A_AB, denkbar wäre auch eine Generalisierung / Spezialisierung. Die Min-/Max-Angaben sind 0,1 bei Artikel und 1,1 bei ArtBeschr, denn jeder Artikel ist mit maximal einem Beziehungstyp dabei und jede Artikelbeschreibung gehört zu genau einem Artikel. |
Artikel, ohne und mit Beschreibung |
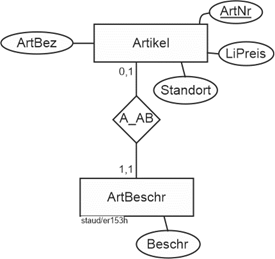
|
|
Abbildung 11.1-10: Rechnungsstellung, Fragment Artikel – Artikelbeschreibung |
|
Fügen wir obige Fragmente zusammen, ergibt sich das folgende Gesamtmodell. |
|
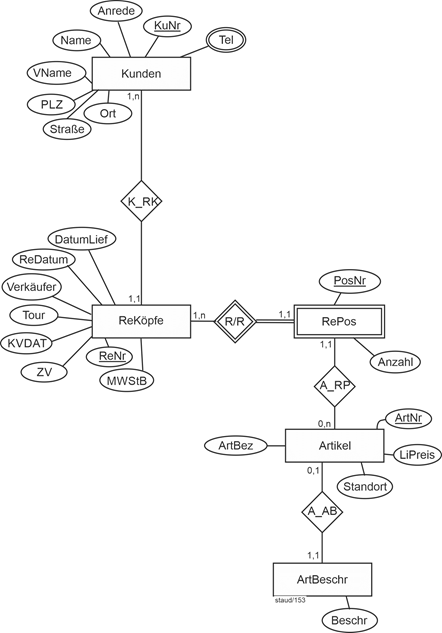
|
|
Abbildung 11.1-11: ER-Modell Rechnungsstellung Stufe 1 – Gesamtmodell |
|
Hinweise: |
|
KVDAT: Kaufvertragsdatum |
|
ZV: Zahlungsvereinbarung |
|
Tel: mehrwertiges Attribut |
|
11.1.2 Stufe 2 |
|
In Stufe 2 wird zwischen Liefer- und Rechnungsadresse unterschieden und es soll gelten: Ein Kunde kann beliebig viele Adressen haben, jede kann bei einer Rechnung Liefer- oder Rechnungsadresse sein. |
|
Eine Folge dieser Festlegung ist, dass der alte Entitätstyp Kunden verkürzt wird, da die Adressattribute in den Entitätstyp Adressen gehen. Übrig bleiben KuNr, Name, VName, Anrede, Tel. |
|
Beim Entitätstyp Adressen wird ein Schlüssel ergänzt (Adressnummer, AdrNr). Für den Beziehungstyp zwischen Kunden und Adressen (Ku/Adr) gelten die Min-/Max-Angaben 1,n bei Kunden (ein Kunde hat mindestens eine Adresse) und 1,n bei Adressen (zu jeder Adresse gehört mindestens ein Kunde („große Wohneinheit, Mehrfamilienhaus, usw.“). Damit ergibt sich folgendes Fragment: |
|
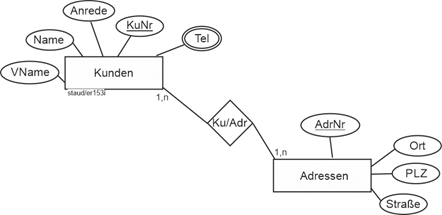
|
|
Abbildung 11.1-12: ER-Modell Rechnungsstellung Stufe 2 – Kunden und Adressen |
|
Bleibt noch zu klären, wie festgehalten wird, welche Adresse bei einer bestimmten Lieferung die Liefer- und welche die Rechnungsadresse ist. Diese Information muss sich auf das Tripel Kunden/Adressen/Rechnungsköpfe beziehen und sie muss auch erlauben, dass es auch mal nur eine einzige Adressangabe gibt. |
Liefer- und Rechnungsadresse |
Eine sinnvolle Lösung dafür ist, für jede Lieferung die drei Entitätstypen Kunden, Adressen und ReKöpfe mittels eines Beziehungstyps Ku/Adr/Re („Lieferungen“) zu verknüpfen und bei jeder Verknüpfung festzuhalten, ob es neben der Rechnungsadresse auch eine abweichende Lieferadresse gibt (hier mit dem Attribut Typ). Die Wertigkeiten beim Beziehungstyp Ku/Adr/Re ergeben sich wie folgt: |
Dreistellige Beziehung |
- Bei Kunden: Jeder Kunde ist an mindestens einer Lieferung beteiligt, hat also mindestens einmal eine Adressangabe in einem Rechnungskopf getätigt. Typischerweise mit der Rechnungsanschrift. Er kann aber auch schon mehrere Lieferungen erhalten haben.
- Bei Adressen: Bei jeder Lieferung werden mindestens eine, maximal zwei Adressen angegeben.
- Bei den Rechnungsköpfen: Jeder Rechnungskopf nimmt genau einmal an einer Beziehung teil.
|
|
Vgl. für die grafische Umsetzung das Entity Relationship - Modell unten. |
|
Das Attribut Typ hat die Ausprägungen L(ieferadresse) und R(echnungsadresse). R gibt es immer, L nur, falls es eine extra Lieferanschrift gibt. Ansonsten ist die Rechnungsanschrift gleich der Lieferanschrift. Die folgende Tabelle zeigt zur Verdeutlichung einige Beispielsdaten: |
|
|
|
| Typ |
ReNr |
KuNr |
AdrNr |
| L |
1001 |
007 |
2 |
| R |
1001 |
007 |
5 |
| R |
2002 |
007 |
1 |
| R |
2020 |
010 |
1 |
| ... |
... |
... |
... |
| |
Zur Veranschaulichung wurde in den Daten auch der Fall eingefügt, dass unter einer Adresse mehrere Kunden wohnen (Rechnungsnummer 2002 und 2020).
|
|
Der Beziehungstyp Ku/Adr wird jetzt eigentlich nicht mehr benötigt. Da es aber oftmals sinnvoll ist, die Adressen von Kunden auch ohne die Rechnungen ansprechen zu können, z.B. bei Marketingmaßnahmen oder ganz allgemein im Customer Relationship Management (CRM), soll er drin bleiben. So kann die Pragmatik zum ER-Modell beitragen. |
Pragmatik |
Hier das Gesamtmodell nach Stufe 2: |
|
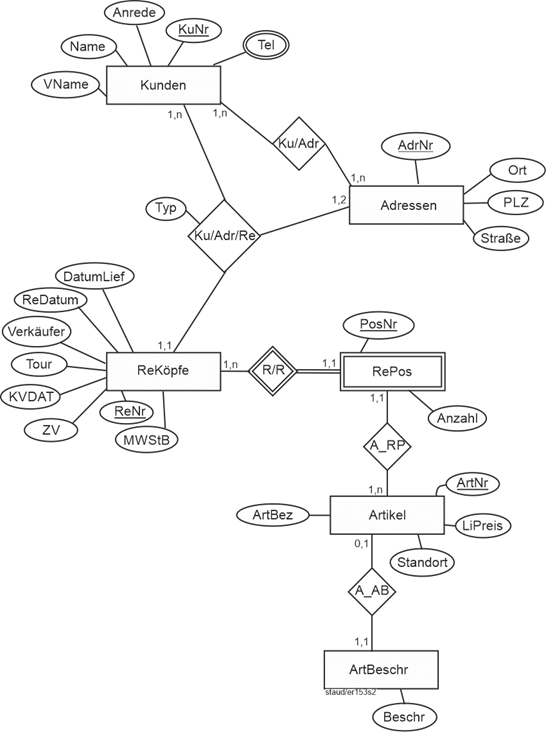
|
|
Abbildung 11.1-13: Rechnungsstellung Stufe 2 – Gesamtmodell |
|
11.1.3 Stufe 3 |
|
In der folgenden dritten Stufe soll nun die zeitliche Dimension hinzugefügt werden und zwar mit dem Ziel, die Rechnungen der vergangenen Jahre aus der Datenbank heraus reproduzierbar zu halten, auch wenn sich die Stammdaten verändern. Bei einer Rechnungsstellung entstehen ja Daten zum kaufmännischen Vorgang, die auch nicht mehr verändert werden. Z.B. Rechnungsnummer, Rechnungsdatum, Artikelbeschreibung, Positionssummen, Gesamtsumme. Andere Daten werden mit Hilfe der durch das Datenmodell vorgegebenen Struktur im Moment der Rechnungsstellung aus den Datenbeständen geholt: zum Kunden, zu den Artikeln. Genau diese Daten können sich aber nach dem Zeitpunkt der Rechnungsstellung sehr schnell ändern: |
Zu „rettende“ Kundendaten |
- Der Kunde zieht um, seine Telefonnummer ändert sich, er ändert seinen Namen.
- Die Artikelpreise ändern sich, Artikel verschwinden aus dem Sortiment, ihre Bezeichnung oder auch Beschreibung ändert sich.
|
|
Und so weiter. Um sich dagegen abzusichern können die "vergänglichen" Attribute bzw. deren Ausprägungen zum Zeitpunkt der Rechnungsstellung (RZP; Rechnungsstellungszeitpunkt) festgehalten werden. Dazu werden diese Attribute an geeigneter Stelle im Datenmodell angelegt und dann in der Datenbank gespeichert. |
Rechnungs-stellungs-zeitpunkt RZP |
Folgende Attribute müssen bezüglich der Kunden "gerettet" werden: Name, Vorname, PLZ, Ort, Straße. Dies geschieht, indem sie mit dem Zusatz "RZP" zusätzlich aufgenommen werden. Doch in welchem Entitätstyp soll man sie unterbringen? Hier gibt es mehrere Möglichkeiten, z.B. eine zeitlich fixierte Anlage im Entitätstyp Kunden bzw. Adressen. Dann gäbe es mit der Zeit eine Historie von Namen bzw. Adressen und bei Abfragen oder Auswertungen müsste auf zeitliche Übereinstimmung geachtet werden. |
Historische Kundendaten |
Eleganter ist die Lösung diese Daten vom Rechnungsstellungszeitpunkt bei den Entitäten zu platzieren, die ebenfalls durch diesen Zeitpunkt fixiert sind. Dies ist hier der Entitätstyp ReKöpfe. Deshalb fügen wir hier folgende Attribute an: |
|
- Name-RZP (Name zum Zeitpunkt der Rechnungsstellung)
- VName-RZP (Zeitgeist: Thomas -> Tom)
- Ort-RZP (wegen eventuellem Umzug)
- Straße-RZP
- Tel-RZP
|
|
Da sich der Mehrwertsteuersatz ja auch regelmäßig ändert und auf der Rechnung ausgewiesen ist, muss auch er "konserviert" werden. Deshalb ergänzen wir noch MWStB-RZP. |
|
Folgende "vergänglichen" Attribute bezüglich der Artikel sollten, da sie auf der Rechnung erscheinen, verdoppelt werden: ArtNr (Artikelnummer), ArtBez (Artikelbezeichnung), LiPreis (Listenpreis). Wieder hängen wir das Kürzel RZP an. Der Platz für diese Attributdoppelung ist, auch hier hilft wieder die Überlegung zur zeitlichen Fixierung, der Entitätstyp RePos. Damit erhält RePos folgende zusätzlichen Attribute: |
Zu "rettende" Artikeldaten |
- ArtNr-RZP
- ArtBez-RZP
- LiPreis-RZP
|
|
Fassen wir das Vorgehen zusammen. Folgende Schritte sind zu leisten: |
|
- Klären, welche Attribute wegen der notwendigen Reproduzierbarkeit dupliziert werden müssen.
- Feststellen, wo diese Attribute platziert werden können.
|
|
Hier nun das gesamte Entity Relationship - Modell der Stufe 3. |
|
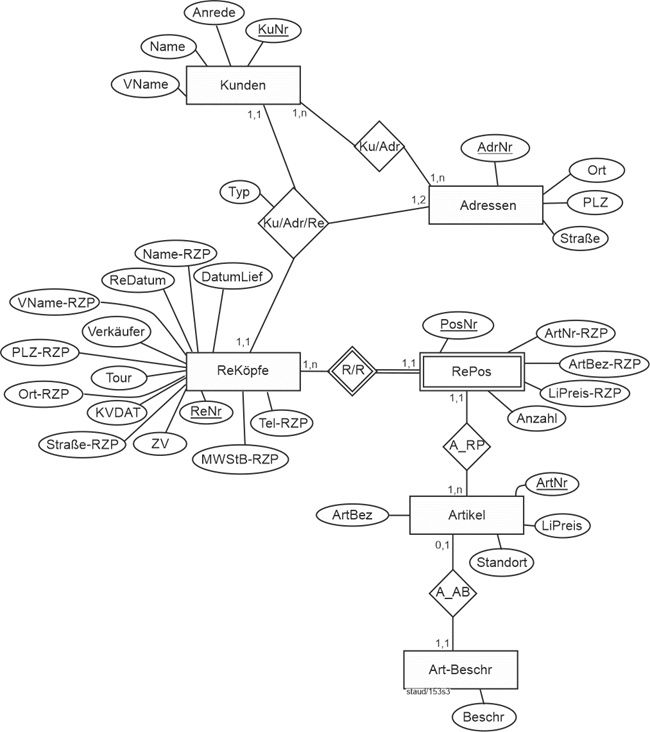
|
|
Abbildung 11.1-14: Rechnungsstellung Stufe 3 – Gesamtmodell |
|
Obige Lösung gelingt nur, weil zu einem Rechnungskopf genau ein Kunde gehört und zu jeder Rechnungsposition genau ein Artikel. Bei anderen Min-/Max-Angaben muss man andere Lösungen finden. Vgl. Kapitel 7. |
|
|
|

|
|
11.2 Angestellte |
|
Zu diesem Beispiel gibt es: Aufgabenstellung + Lösung + Umsetzung in ein relationales Datenmodell |
|
Aufgabe und Lösung |
|
Es geht um die Angestellten eines Unternehmens. Festgehalten wird ihre Tätigkeit, die evtl. Projektmitarbeit, die Abteilungszugehörigkeit und die PC-Nutzung. Dies alles gegenüber der Realität stark vereinfacht. |
|
Folgendes soll im ER-Modell festgehalten werden: |
|
- Für die Angestellten Personalnummer (PersNr), Name (Name), Vorname (VName) und Geburtstag (GebTag). Außerdem werden die Adressen erfasst mit Strasse, PLZ und Ort. Es kommt vor, dass Angestellte mehrere Adressen haben (Erst- und Zweitwohnsitz, usw.)
|
|
Dies führt zum Entitätstyp Angestellte. Für die Adressen wird ein eigener Entitätstyp angelgt. Der Beziehungstyp Ang-Adr stellt die Beziehung her. |
|
- Das Vorgesetztenverhältnis. Wer ist wem unter- bzw. überstellt?
|
|
Dafür muss ein rekursiver Beziehungstyp (siehe Abschnitt 2.3) angelegt werden. Er wird An-An genannt. Ein Vorgesetzter hat zahlreiche Unterstellte, ein Angestellter ohne Leitungsfunktion hat genau einen Vorgesetzten (wir sehen hier mal von „Doppelspitzen“ ab). |
|
- Für die Projekte die Bezeichnung (Bez), der Einrichtungstag (TagEinr), die Dauer (Dauer) und das Budget (Budget). Ein Projekt kann auf mehrere Standorte verteilt sein.
|
|
Dies führt zum Entitätstyp Projekte. Die Standorte könnten ein beschreibendes Attribut von Projekte sein, da sie aber im nächsen Punkt näher beschrieben werden, wird auch daraus ein eigener Entitätstyp. |
|
- Die Standorte werden mit einer identifizierenden Information (OrtId), ihrer Bezeichnung (Bez) und ihrer Adresse erfasst. Außerdem wird erfasst, wieviele Mitarbeiter am Standort sind (AnzMitarb). An einem Standort muss kein Projekt sein, es können aber auch mehrere Projekte dort angesiedelt sein.
|
|
Hier wird zum einen die Beschreibung der Standorte geklärt, zum anderen auch die Beziehung zwischen Projekten und Standorten (Pr-Ort). Die Min-/Max-Angabe 0,n bei Standorte soll signalisieren, dass an einem Standort, z.B. bei der Einrichtung, auch mal kein Projekt angesiedelt sein kann. |
|
- Ein Angestellter kann in keinem, einen oder mehreren Projekten mitarbeiten und ein Projekt hat mindestens einen (Projektleitung), typischerweise aber mehrere Mitarbeiter.
|
|
Damit wird die Beziehung zwischen Angestellten und Projekten geklärt. 1,n bei Projekte, 0,n bei Angestellte. |
|
- Für die Abteilungen wird die Abteilungsbezeichnung (AbtBez), der Abteilungsleiter (AbtLeiter) und der Standort festgehalten. Eine Abteilung ist immer genau an einem Standort, an einem Standort können mehrere Abteilungen sein.
|
|
Dies bringt erstens Abteilungen zu einer eigenen Existenz („Identifikation + Beschreibung“), führt zweitens zur Beziehung Abteilungen / Standorte (Ab-St) und klärt drittens deren Min-/Max-Angaben. Wiederum signalisiert die Minimumsangabe 0 bei den Standorten, dass Standorte datenbanktechnisch schon erfasst werden können, bevor dort eine Abteilung eingerichtet wird. |
|
- In einer Abteilung sind mehrere Angestellte, ein Angestellter gehört aber zu einem Zeitpunkt genau einer Abteilung. Im Zeitverlauf können Angestellte auch die Abteilung wechseln.
|
|
Dieser Absatz klärt die Beziehung Ang-Abt zwischen Angestellten und Abteilungen. Wichtig ist der Hinweis auf die zeitliche Dimension. Diese erfordert die Attribute Beginn und Ende auf dem Beziehungstyp. |
|
- Festgehalten wird auch, welche Funktion ein Angestellter in einer Abteilung hat. Dies geschieht mit Hilfe der Funktionsbezeichnung (BezFu), dem Beginn (Beginn) und Ende (Ende) der Funktionsübernahme. Es ist durchaus möglich, dass ein Angestellter im Zeitablauf auch unterschiedliche Funktionen in einer Abteilung übernimmt. Zu einem Zeitpunkt aber immer nur eine.
|
|
Damit werden abteilungsbezogene Funktionen eingeführt. Diese werden am besten durch einen Beziehungstyp zwischen Angestellte und Abteilungen modelliert. Er wird Funktion genannt und erhält die oben angeführten Attribute. Auch hier ist die Erfassung der zeitlichen Dimension nötig. |
Beispiel Beziehungsattribute |
- Für die von den Angestellten benutzten PCs wird die Inventarnummer, (InvNr), die Bezeichnung (Bez) und der Typ (Typ) erfasst. Ein PC kann mehreren Angestellten zugeordnet sein, ein Angestellter nutzt zu einem Zeitpunkt maximal einen PC. Die Übernahme eines PC durch einen Angestellten wird mit der Art der Übernahme (Art; „Entwickler, Office-Nutzer, Superuser“), dem Beginn (Beginn) und dem Ende (Ende) festgehalten. Natürlich nutzt ein Angestellter im Zeitverlauf mehrere PC.
|
|
Damit werden die PC als Modellobjekte eingeführt und zwar als Einzelentitäten (PC-Einzeln) und als Typen (PC-Typen). Vgl. dazu das Muster Einzel/Typ. Außerdem wird die Beziehung zwischen Angestellten und PC geklärt. Der Beziehungstyp An-PC erhält die angeführten Attribute. |
Muster Einzel/Typ |
- Für die Programmiersprachen, die von den Angestellten beherrscht werden, wird die Bezeichnung der Sprache (BezPS), die Bezeichnung des Compilers (BezComp) und der Preis (PreisLiz) für eine Lizenz festgehalten. Es gibt auch Angestellte, die nicht programmieren und keine Programmiersprache beherrschen. Wegen der Bedeutung der Programmiererfahrung wird außerdem festgehalten, wieviel Jahre Programmierpraxis (ErfPS) jeder Angestellte in seinen Programmiersprachen hat. Dieser Wert wird immer zum Jahresende aktualisiert.
|
|
Die Programmiersprachen könnten, in einer einfacheren Modellierung, Attribut von Angestellte sein. Da sie aber näher beschrieben werden, wird ein Entitätstyp daraus. Die Programmiererfahrung wird am Beziehungstyp An-PS angelegt, die jährliche Aktualisierung ist nicht Gegenstand des Datenmodells. |
|
- Für die Entwickler unter den Angestellten wird die von ihnen genutzte Entwicklungsumgebung (EntwU) und ihre hauptsächlich genutzte Programmiersprache festgehalten (HauptPS). Für die Mitarbeiter des Gebäudeservices die Funktion (Funktion) und die Schicht (Schicht), in der sie arbeiten. Für das Top-Management der Bereich in dem sie tätig sind (Bereich) und das Entgeltmodell, nach dem sie ihr Gehalt bekommen (Entgelt).
|
|
Dies führt zu einer Unterteilung der Angestellten in die drei Gruppen. Da sie alle gemeinsame und spezifische Attribute haben, entsteht im ER-Modell eine Generalisierung / Spezialisierung. |
|
Das ER-Modell |
|
|
|
Abbildung 11.2-1: ER-Modell Angestellte / Abteilungen / PCs / Projekte |
|
11.2.1 Das relationale Datenmodell |
|
Es ist für das Verständnis attributbasierter Modellierung sinnvoll, die Umsetzung von ER-Modellen in relationale (oder objektierte) zu betrachten. Deshalb dazu hier das entsprechende relationale Datenmodell Angestellte in textlicher Notation. |
|
Abteilungen (#AbtBez, AbtLeiter, OrtId) |
|
Adressen (#AdrId, PLZ, Ort, Straße) |
|
An-An (#(PersNrV, PersNrU)) //Vorgesetzte |
|
Ang-Abt (#(PersNr, AbtBez), Beginn, Ende)) |
|
Ang-Adr (PersNr, #AdrId) |
|
Angestellte (#PersNr, Name, VName, DatumEinst, GebTag) |
|
Ang-PC (PersNr, #InvNrPC, Art, Beginn, Ende)) |
|
Ang-Pr (#(PersNr, BezProj)) |
|
Ang-PS (#(PersNr, BezPS), ErfPS) |
|
Entwickler (#PersNr, EntwU, HauptPS) |
|
Funktionen (#(PersNr, AbtBez), BezFu, BegF, EndeF)) |
|
Gebäudeservice (#PersNr, Funktion, Schicht) |
|
PC-Einzeln (#InvNr, BezPC) |
|
PC-Typ (#Bez, Typ) |
|
Projekte (#Bez, TagEinr, Dauer, Budget) |
|
Pr-Ort (#(BezProj, OrtId)) |
|
PS (#BezPS, BezComp, PreisLiz) |
|
Standorte (#(OrtId, Bez, AnzMitarb, AdrId) |
|
TopMan (#PersNr, Bereich, Entgelt) |
|
|
|

|
|
|
|
11.3 Zoo |
|
Zu diesem Beispiel gibt es: Aufgabenstellung + Lösung |
|
Anwendungsbereich / Aufgabenstellung |
|
Für einen Zoo soll eine Datenbank rund um die vorhandenen Tiere erstellt werden. Dabei erfolgt eine Konzentration auf größere Tiere (Säugetiere, Reptilien, …). Allen diesen Tieren wird eine identifizierende Tiernummer (TNr), ihr Name (Name; vom Pflegepersonal vergeben), ihr Geburtstag (GebTag) und das Geschlecht zugewiesen. Außerdem wird das Gebäude erfasst, in dem Sie gehalten werden und die Gattung, zu der sie gehören
. Für jede Gattung wird auch festgehalten, wie viele Tiere dieser Gattung der Zoo hat (z.B. 5 Afrikanische Elefanten oder 20 Schimpansen) (Anzahl). Wegen der Bedeutung der Information für die Gebäude und das Außengelände wird bei Elefanten noch zusätzlich das Gewicht und bei Giraffen die Größe erfasst, jeweils mit dem Datum, zu dem der Wert erhoben wurde. |
|
Auch die Rahmenbedingungen der Fütterung der Tiere wird festgehalten: Welches Futter (FutterBez) ein Tier bekommt (durchaus mehrere Futterarten, z.B. Heu und Frischkost), eine Beschreibung des Futters (Beschr) und welche Menge davon täglich (MengeJeTag) gegeben wird. |
|
Für die einzelnen Gebäude des Zoos wird eine Gebäudenummer (GebNr), die Größe, der Typ (für Säugetiere, für Reptilien, usw.) und die Anzahl der Plätze (AnzPlätze) erfasst. |
|
Das ER-Modell |
|
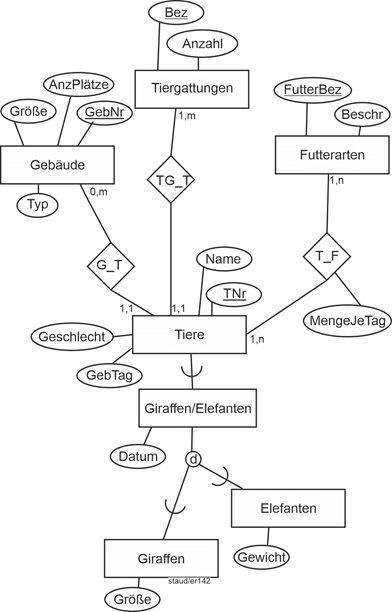
|
|
Abbildung 11.3-1: ER-Modell Zoo |
|
Das Attribut Datum ist nicht bei der Generalisierung, weil nur Giraffen und Elefanten mit Tagesdatum gewogen werden. Fügt man es bei Giraffen und Elefanten dazu, ergibt sich ein Verstoß gegen das Gen/Spez-Konzept. Der richtige Platz für dieses Attribut ist daher eine eigene Spezialisierung Giraffen/Elefanten. |
|
|
|

|
|
|
|
11.4 Schützenverein |
|
Zu diesem Beispiel gibt es: Aufgabenstellung + Lösung |
|
Theorieaspekte: |
|
|
|
- Generalisierung / Spezialisierung
|
Außerdem wird bei einem Entitätstyp die zeitliche Dimension erfasst. |
|
Anwendungsbereich |
|
Für einen Schützenverein soll ein ER-Modell erstellt werden. Folgende Informationen werden erfasst: |
|
- Für die Vereinsmitglieder die Mitgliedsnummer (MNr), der Name, der Vorname (VName), die (Haupt)Telefonnummer (Telefon), die Mailadresse (Mail) sowie der Hauptwohnsitz. Für diesen wird der Ort, die Postleitzahl (PLZ) und die Straße mit Hausnummer erfasst. Es wird nur eine Adresse erfasst. Außerdem soll für jedes Mitglied der Tag des Eintritts in den Verein festgehalten werden (Eintritt).
- Für die vom Verein verwalteten Waffen die Nummern der Waffen (eindeutig, vom Verein vergeben, eingraviert) (WaffNr), den Typ der Waffe (Gewehr, Revolver, Pistole, usw.) (WaffTyp), den Preis der Waffe bei der Anschaffung (Preis) und den Tag der Anschaffung der Waffe (Anschaffung). Für jeden Waffentyp wird außerdem festgehalten, wie viele Waffen man davon hat (Anzahl) und wie hoch deren Gesamtsumme bei der Anschaffung war (SumAnsch).
- Jede Nutzung einer Vereinswaffe durch ein Vereinsmitglied (auf den Schießständen des Vereins) mit dem Datum und dem Anfangs- und Endzeitpunkt der Nutzung (Datum, AnfZeit, EndZeit).
- Die Funktionen, die im Verein zu übernehmen sind (BezFkt), z.B. Aufsicht führen, Kassierer, Waffenwart, usw. Bei jeder Funktion wird festgehalten, welche Voraussetzungen nötig sind, um sie zu übernehmen (Vorauss).
- Welches Vereinsmitglied welche Funktion übernommen hat, also die Funktionsträger. Hierbei wird festgehalten, ab welchem Tag die Pflicht übernommen und wann sie (gegebenenfalls) wieder abgegeben wurde (Beginn, Ende)
- Für aktive Mitglieder (die also dem Sport wirklich nachgehen), mit welchem Waffentyp sie in den Wettkämpfen schießen. Es gibt Mitglieder, die mit mehreren unterschiedlichen Waffen aktiv sind.
- Für ehemalige Mitglieder, wann sie ausgetreten sind (Austritt) und wie viele Jahre sie Mitglied waren (Jahre).
|
|
Das ER-Modell |
|
|
|
Abbildung 11.4-1: ER-Modell Schützenverein |
|
Hier liegt auch ein Muster Einzel/Typ vor: zwischen den Entitätstypen Waffen-Einzeln und Waffen-Typen. Durch die Berücksichtigung dieses Musters können die Informationen redundanzfrei gespeichert werden. Die Min-/Max-Angaben sind entsprechend: Jede einzelne Waffe gehört zu einem Waffentyp, zu einem Waffentyp gehören u.U. viele Einzelwaffen. |
Muster Einzel/Typ |
Die zeitliche Dimension bei den Mitgliedern (Eintritt, Austritt) wurde hier so umgesetzt, dass für Ehemalige Mitglieder ein eigener Entitätstyp angelegt wurde. Bei der Funktionsübernahme und bei der Nutzung der Waffen wurde dagegen pragmatisch modelliert, d.h. das jeweilige Ende bleibt unbeschrieben, bis es erreicht ist. |
Zeitliche Dimension |
|
|

|
|
|
|
11.5 Sportverein |
|
Zu diesem Beispiel gibt es: Aufgabenstellung + Lösungsweg |
|
Anwendungsbereich |
|
Ein Sportverein beschließt, seine Aktivitäten (Mitgliederverwaltung, Sportveranstaltungen, usw.) in Zukunft computergestützt abzuwickeln. Dazu soll im ersten Schritt eine einfache Datenbank aufgebaut werden, für die folgende Spezifikationen festgehalten werden: |
Beispiel Sportverein |
- Der Sportverein ist in Abteilungen gegliedert. Eine für Handball, eine für Fußball. Weitere können in der Zukunft dazukommen.
- Jede Abteilung hat einen Leiter.
- Jede Abteilung hat mehrere Mannschaften.
- Von jeder Mannschaft werden die Spieler, der Kapitän und die Liga festgehalten, in der sie spielt (Bundesliga, usw.)
- Jede Mannschaft hat einen Trainer.
- Die Begegnungen von Mannschaften des Vereins mit Datum, gegnerischer Mannschaft und Ergebnis sollen festgehalten werden.
|
|
Die Mitglieder des Vereins werden durch Name, Vorname, PLZ, Ort, Straße, Telefon, Geburtstag, Alter und eine Mitgliedsnummer (Nr) festgehalten. |
|
Außerdem wird für die Mitglieder erfasst, ob es sich um ein passives oder ein aktives Mitglied handelt. Für jedes aktive Mitglied wird dann noch festgehalten, welche Sportart es in welcher Leistungsstufe betreibt; für die passiven Mitglieder wird erfasst, für welche ehrenamtliche Tätigkeit sie zur Verfügung stehen. |
Aktiv / passiv |
Wie sehen nun die konkreten Modellierungsschritte aus? Sinnvoll ist es, zuerst die Entitätstypen zu suchen. Dies ist dann allerdings keine endgültige Festlegung, sondern eine, die im Verlauf der Modellierung auch wieder korrigiert werden kann. |
Erste Schritte |
Beginnen wir also mit Entitäten und Entitätstypen. Diese erkennt man im modellierungstechnischen Sinne daran, dass es sich erstens um Objekte im allgemeinen Sinn handelt und dass zweitens diese Objekte durch Attribute beschrieben werden. Zweiteres ist von zentraler Bedeutung, denn sonst kann es sich auch um ein Attribut handeln, wie auch dieses Beispiel gleich zeigen wird. |
Entitäten und Entitätstypen erkennen |
Natürlich etablieren auch andere nicht-konventionelle Attribute einen Entitätstyp. Z.B. Grafiken, Bilder, Videos, usw. Allerdings sind diese nur Ergänzungen der Basisbeschreibung durch Attribute, die auf jeden Fall vorhanden sein muss. |
|
Hier ist ein Entitätstyp sofort erkennbar, die Mitglieder. Die Vereinsmitglieder existieren – auch im allgemeinen Sinn – und sie werden durch Attribute beschrieben. Das Alter wurde als Beispiel eines abgeleiteten Attributs hinzugefügt. |
|
|
|
Abbildung 11.5-1: Modellierung der Mitglieder |
|
Adresse, Name: zusammengesetzte Attribute |
|
Alter: abgeleitetes Attribut |
|
Wichtig bei der Findung von Entitätstypen ist die umfassende Beachtung der Zuordnungsregel, wie sie in Abschnitt 3.1 formuliert wurde. |
|
Offen bleibt bzgl. der Mitglieder noch die Frage, wie die Eigenschaft, aktives oder passives Vereinsmitglied zu sein, erfasst wird. Ginge es nur um diese Eigenschaft, würde einfach ein Attribut aktiv/passiv mit diesen zwei Eigenschaften an den Entitätstyp Mitglieder angefügt. Nun ist es hier aber so, dass für die aktiven und passiven Mitglieder jeweils unterschiedliche Attribute festgehalten werden sollen. Deshalb müssen diese Teilgruppen der Mitglieder getrennt erfasst und – da sie ja als Mitglieder auch gemeinsame Attribute haben – mit der in Abschnitt 5.1 vorgestellten Generalisierung / Spezialisierung angelegt werden: |
Aktiv / passiv |
Hinzugenommen wurde in der Generalisierung (Mitglieder) ein Attribut Status mit den Ausprägungen passiv und aktiv, mit dem es möglich ist, die allgemeinen Attribute (Adressen) der beiden Gruppen gezielt anzusprechen. |
|
Hinweis: Das Attribut mit den Punkten soll oben und im Folgenden die schon vorher eingeführten Attribute andeuten. |
|
Die aktiven Mitglieder erhalten die Attribute Sportart (derzeit nur Handball oder Fußball) und Leistungsstand. Es wird davon ausgegangen, dass ein Spieler nur eine Sportart betreibt. Das Attribut ehrenamtliche Tätigkeiten der passiven Mitglieder erfasst in einer verkodeten Form, für was das Mitglied zur Verfügung steht. Es handelt sich um ein mehrwertiges Attribut. |
|
|
|
Abbildung 11.5-2: Aktive und passive Mitglieder in einer Generalisierung / Spezialisierung |
|
Tätigkeiten: mehrwertiges Attribut |
|
Wie in Abschnitt 4.3 gezeigt, gibt es in ER-Modellen die Möglichkeit, grafisch auszudrücken, dass alle Entitäten des übergeordneten Typs an der Spezialisierung teilnehmen müssen. Diese totale Beteiligung wurde oben durch den Doppelstrich zwischen dem übergeordneten Typ und dem d-Kreis ausgedrückt. Er signalisiert hier, dass alle Mitglieder entweder aktive oder passive Mitglieder sein müssen. |
Totale
Beteiligung |
Bei Beziehungen wird „totale Beteiligung“ durch die Min-/Max-Angaben festgelegt. Steht als Mindestwert ein Wert größer 0 da, müssen alle Entitäten des Entitätstyps an der Verbindung teilhaben. |
|
Betrachten wir nun die Mannschaften. Sie tauchen mit folgenden Beschreibungen auf: |
Mannschaften |
- Jede Abteilung hat mehrere Mannschaften, insofern könnte „Mannschaft“ ein Attribut von Abteilung sein.
- Von jeder Mannschaft werden Spieler, Kapitän, Liga, Trainer und Begegnungen festgehalten.
|
|
Letzteres macht die Mannschaften zu Entitätstypen, da sie durch weitere Attribute beschrieben werden. Die Klärung der Frage, ob sie evtl. ein Beziehungstyp sein können, wird auf eine spätere Phase des Modellierungsvorgangs verschoben. Damit ergibt sich folgender erster Entwurf: |
Findung Entitätstyp – Beispiel |
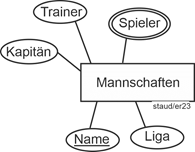
|
|
Abbildung 11.5-3: Entitätstyp Mannschaften |
|
Hinzugefügt wurde ein Attribut Name, mit der Bezeichnung der Mannschaften. Das Attribut Spieler ist mehrwertig, da jede Mannschaft mehrere Spieler hat. |
|
Auf die Aufnahme eines Attributs Begegnung wurde verzichtet, da die Begegnungen durch weitere Attribute zu einer eigenständigen Existenz kommen. Im beschreibenden Text wurde festgelegt, dass alle Begegnungen von Mannschaften des Vereins mit Tagesdatum, Gegner und Ergebnis festgehalten werden sollen. Damit entsteht ein entsprechender Entitätstyp. Gleichzeitig wird hier der erste Beziehungstyp deutlich, der mit M_B bezeichnet werden soll und schlicht die Tatsache beschreibt, dass die Mannschaften des Vereins an den Begegnungen teilnehmen. Da auch nur solche Begegnungen erfasst werden, handelt es sich um einen singulären Entitätstyp, der durch ein Rechteck mit Doppellinie dargestellt wird (vgl. Abschnitt 2.4). Der zugehörige Beziehungstyp erhält ebenfalls eine solche. |
Begegnungen |
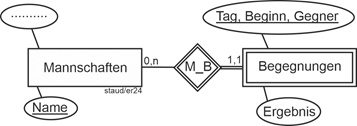
|
|
Abbildung 11.5-4: Singulärer Entitätstyp Begegnungen |
|
Zusammengesetzter Schlüssel: (Tag, Beginn, Gegner). Das Attribut Beginn wurde zusätzlich aufgenommen, um mehrere Begegnungen an einem Tag, z.B. im Rahmen eines Turniers, unterscheiden zu können. Schlüssel für diesen Entitätstyp sind die Attribute Tag, Beginn und Gegner zusammen. |
|
Zu beachten ist, dass es nur um die Spiele des betrachteten Vereins geht, nicht um alle Spiele einer Liga, was die Situation verändern würde. |
|
Als Schlüssel wurde hier ein zusammengesetzter genommen, der bei der Überführung in konkretere Strukturen (Z.B. in Relationen) um den Schlüssel von Mannschaften ergänzt werden müsste. Dies ist typisch für singuläre Entitätstypen. Ihre Existenzabhängigkeit zeigt sich auch darin, dass ihr Schlüssel um den des anderen Entitätstyps ergänzt werden muss. |
|
Jetzt müssen noch die Abteilungen betrachtet werden. Für sie wurde oben festgehalten, dass der Verein in Abteilungen gegliedert ist (Handball und Fußball), dass jede Abteilung eine/n Leiter/in und mehrere Mannschaften hat. |
Abteilungen |
In Konfrontation mit den schon erstellten Modellfragmenten lässt sich damit festhalten, dass Abteilungen ein Entitätstyp mit den Attributen Leiter und Sportart ist. Die Tatsache, welche Mannschaft zu welcher Abteilung gehört, wird nicht durch ein Attribut festgehalten, sondern durch einen Beziehungstyp M_A zwischen Mannschaften und Abteilungen: |
Beziehungstyp M_A |
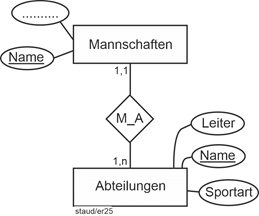
|
|
Abbildung 11.5-5: Beziehung Mannschaften in Abteilungen |
|
Damit sind die wichtigsten Komponenten des zu erstellenden Datenmodells realisiert. In der folgenden Abbildung werden sie zusammengestellt. Die Min-/Max-Angaben haben folgende Bedeutung: |
|
- 1,1 bei Mannschaften -- Abteilungen (M_A): Eine Mannschaft gehört zu genau einer Abteilung.
- 0,n bei Mannschaften -- Begegnungen (M_B): Eine Mannschaft hat an keiner (z.B., wenn sie neu aufgestellt wurde) oder an mehreren Begegnungen teilgenommen.
- 1,1 bei Begegnungen -- Mannschaften (M_B): Eine Begegnung wird nur dann als solche aufgenommen, wenn genau eine Mannschaft „unseres“ Vereins teilgenommen hat. Wir schließen hier also bewusst Begegnungen zwischen zwei Mannschaften des Vereins aus.
- 1,n bei Abteilungen -- Mannschaften (M_A): Eine Abteilung hat mindestens eine Mannschaft.
|
|
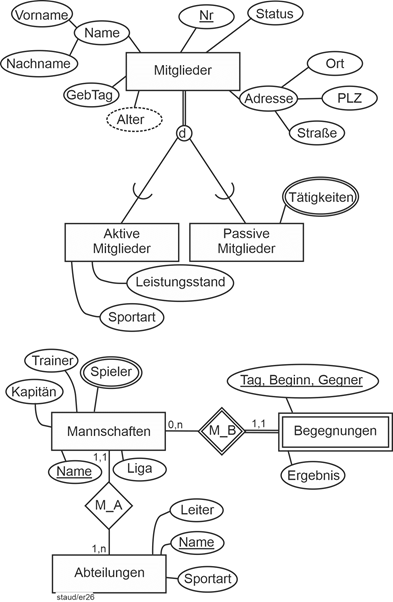
|
|
Abbildung 11.5-6: Gesamtmodell Sportverein – Erster Versuch |
|
Dieses Gesamtmodell ist nun aber in einem wichtigen Punkt fehlerhaft: Eine Trennung eines Datenmodells in zwei unverbundene Teile ist nicht möglich. So etwas gibt es nicht, da ein Datenmodell sich ja gerade dadurch auszeichnet ist, dass zusammengehörige Informationen über einen Weltausschnitt verwaltet werden. Sonst sind es zwei Datenmodelle mit zwei verschiedenen Datenbanken. |
Defizit: Trennung |
Bei genauerer Betrachtung zeigt sich nun aber, dass natürlich die Mitglieder mit den organisatorischen Aspekten des Vereins auf vielfältige Weise verknüpft sind. Insbesondere durch folgende Aspekte: |
Korrektur |
- Aktive Mitglieder spielen in Mannschaften
- Aktive Mitglieder können Kapitän einer Mannschaft sein
- Aktive Mitglieder trainieren die Mannschaften (wir gehen davon aus, dass die Trainer als aktive Mitglieder zum Verein gehören)
- Aktive Mitglieder leiten die Abteilungen
|
|
Alle diese Informationen wurden im obigen ersten Entwurf – herrührend von den Modellkomponenten – als Attribute von Entitätstypen definiert. Dies muss nun geändert werden. |
|
Beginnen wir mit den Spielern der Mannschaften. Diese Information sollte nicht als mehrwertiges Attribut von Mannschaften erfasst werden, sondern als Beziehungstyp zwischen Mannschaften und Aktive Mitglieder: AM_S. Damit ist nicht nur die Information der Mannschaftszugehörigkeit eindeutig erfasst, sondern es stehen auch die Adressen der Mannschaftsmitglieder zur Verfügung und die Namen der Spieler werden nur einmal erfasst, im Mitgliederverzeichnis, wo sie hingehören. |
Spieler der Mannschaften
AM_S |
Ganz ähnlich bei der Erfassung der Trainer. Bisher als Attribut von Mannschaft erfasst, werden sie nun zu einer Beziehung zwischen Trainern und Mannschaften: AM_T. |
AM_T |
Die Kapitäne der Mannschaften werden ebenfalls durch eine Beziehung zwischen Mannschaften und Aktive Mitglieder erfasst, AM_K, denn die Kapitäne sollen in unserem Datenmodell aktive Mitglieder sein. |
|
Die Leiter der Abteilungen werden dementsprechend als Beziehung zwischen Abteilungen und Aktive Mitglieder erfasst: AM_A. |
|
In der folgenden Abbildung nun das Gesamtmodell mit den besprochenen Korrekturen. Weggefallen sind nun die diversen Attribute, mit denen vorher die Beziehungen festgelegt wurden. Die weiteren Min-/Max-Angaben sind ebenfalls angegeben. Sie bedeuten: |
|
- 0,1 bei Aktive Mitglieder -- Mannschaften und Beziehung AM_S: Ein aktives Mitglied spielt in maximal einer Mannschaft. Selbstverständlich wäre an der zweiten Position auch ein höherer Wert möglich, falls die Semantik es erfordert. Ebenso ein Wert größer Null an der ersten Position.
- 0,1 bei Aktive Mitglieder -- Mannschaften und Beziehung AM_T: Ein aktives Mitglied kann in maximal einer Mannschaft Trainer sein (Für diese und die anderen Festlegungen gilt, dass die Semantik natürlich auch anders sein kann).
- 0,1 bei Aktive Mitglieder -- Mannschaften und Beziehung AM_K: Ein aktives Mitglied ist in maximal einer Mannschaft Kapitän.
- 0,1 bei Aktive Mitglieder -- Abteilungen und Beziehung AM_A: Ein aktives Mitglied leitet maximal eine Abteilung.
- 1,1 bei Mannschaften -- Aktive Mitglieder und Beziehung AM_T: Eine Mannschaft wird von genau einem aktiven Mitglied trainiert.
- 11,15 bei Mannschaften -- Aktive Mitglieder und Beziehung AM_S: Eine Mannschaft besteht aus mindestens 11 und maximal 15 Spielern (aktive Mitglieder).
- 0,1 bei Mannschaften -- Aktive Mitglieder und Beziehung AM_K: Eine Mannschaft hat maximal einen Kapitän.
|
|
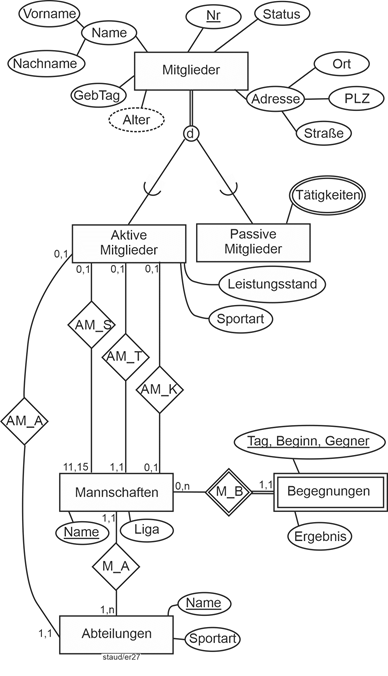
|
|
Abbildung 11.5-7: Entity Relationship - Modell Sportverein – Endfassung |
|
|
|

|
|
|
|
11.6 PC-Beschaffung |
|
Zu diesem Beispiel gibt es: Aufgabenstellung + Lösungsweg |
|
11.6.1 Anwendungsbereich |
|
In einem Unternehmen soll der Vorgang der PC-Beschaffung durch eine Datenbank festgehalten werden. Dafür soll ein ER-Modell erstellt werden. Folgende Festlegungen ergaben sich in den Interviews, die im Vorfeld mit den Betroffenen geführt wurden. Die Attributsnamen wurden, soweit möglich, auch gleich geklärt: |
|
- Jeder PC erhält eine Inventarnummer (InvPC). Neben dieser wird der Prozessortyp (Proz) und die Größe des Arbeitsspeichers (ArbSp) festgehalten.
- Bildschirme erhalten ebenfalls eine Inventarnummer (InvBild). Außerdem wird für sie die Seriennummer (SerNr), der Typ (BSTyp) und der Durchmesser (Zoll) festgehalten. Jedem PC sind maximal zwei Bildschirme zugeordnet.
- Für jeden PC wird folgendes festgehalten: der Prozessortyp (Proz), die Größe des Arbeitsspeichers (ArbSp), ob ein DVD-Laufwerk - Laufwerk vorhanden ist und falls ja, welche Bezeichnung (DVDBez) und welche Geschwindigkeit (Geschw) es hat. Außerdem werden jeweils mit Hilfe einer Kurzbezeichnung (KBezSK) die sonstigen Komponenten (Streamer, SoundBlaster, externe Platten usw.) festgehalten. Jede dieser Komponenten ist genau einem PC zugeordnet. Ein PC hat natürlich typischerweise mehrere.
- Für jede Festplatte wird festgehalten: Name und Größe (PlName, Größe) sowie die Zugriffsgeschwindigkeit (Zugriff), die Seriennummer (SerNr) (diese ist eindeutig, auch über Hersteller hinweg) und der Tag, an dem die Platte in den Rechner eingebaut wurde (TagEinbau).
- Ein PC kann mehrere Festplatten haben, eine Festplatte ist aber nur einem PC zugeordnet.
- Für jeden PC wird weiterhin festgehalten, in welcher Abteilung er steht (Abteilung), wer ihn nutzt (erfasst über die PersNr) und wann er dort eingerichtet wurde (Einrichtung). Es kommt vor, wenn auch nicht oft, dass ein PC von mehreren Mitarbeitern genutzt wird. Allerdings ist er immer einer einzigen Abteilung zugewiesen.
- Die Nutzer werden durch ihre Personalnummer (PersNr), den Namen (Name, Vorname) und ihre Telefonnummer (Tel) erfasst. Außerdem wird festgehalten, ab welchem Datum die Nutzung erfolgte (Beginn). Nach dem Ende der Nutzung, wird auch dies festgehalten (Ende).
|
|
Mit diesem Beispiel wird u.a. folgendes Ziel verfolgt: Es soll auf die Unterscheidung von Einzelobjekt und Gruppe gleichartiger Objekte (hier im Weiteren nicht ganz korrekt „Typ“ genannt) hingewiesen werden. Z.B. auf die Unterscheidung von einzelnen Festplatten (identifiziert durch ihre Seriennummer) und Festplattentyp (alle gleichen). Diese Unterscheidung muss bei der Modellierung beachtet werden. |
Muster Einzel/Typ |
11.6.2 Lösungsweg |
|
Betrachten wir zur Erstellung des Datenmodells nochmals die Spezifikationen, Schritt um Schritt, jeweils mit Spiegelstrichen. |
|
- Jeder PC erhält eine Inventarnummer (InvPC). Neben dieser wird der Prozessortyp (Proz) und die Größe des Arbeitsspeichers (ArbSp) festgehalten.
- Bildschirme erhalten ebenfalls eine Inventarnummer (InvBild). Außerdem wird für sie die Seriennummer (SerNr), der Typ (BSTyp) und der Durchmesser (Zoll) festgehalten. Jedem PC sind maximal zwei Bildschirme zugeordnet.
|
|
Hier werden zwei potentielle Entitätstypen direkt durch identifizierende Attribute angesprochen. Um zu erkennen, ob tatsächlich Entitätstypen entstehen, prüfen wir die übrigen Texte und erkennen, dass schon in der nächsten Spezifikation Attribute von PCs genannt werden. Also entsteht ein Entitätstyp PC (dazu mehr unten). Genauso bei den Bildschirmen. Hier werden auch gleich mehrere beschreibende Attribute genannt. Damit ergibt sich ein Entitätstyps Bildschirme. Ohne diese weiteren Attribute wäre InvBild einfach ein Attribut von PC. Aus pragmatischen Gründen ergänzen wir ein Attribut Bildschirmbezeichnung (BSBez) [Anmerkung] . |
Identifikation + Beschreibung -> Existenz |
|
|
Abbildung 11.6-1: Entitätstyp Bildschirme – erste Fassung |
|
Außerdem ergibt sich damit gleich ein Beziehungstyp, denn PCs und Bildschirme sind ja verknüpft und wir müssen sicherlich festhalten, welcher Bildschirm an welchem PC dient. Dazu unten mehr. |
|
Mit Hilfe des folgenden Ausschnitts aus der Spezifikation ergänzen wir nun die Beschreibung des Entitätstyps PC um die angegebenen Attribute. Unkritisch sind die Attribute Proz und ArbSp. Doch was ist mit den DVD – Laufwerken und mit den „sonstigen Komponenten“? |
|
- Für jeden PC wird folgendes festgehalten: der Prozessortyp (Proz), die Größe des Arbeitsspeichers (ArbSp), ob ein DVD-Laufwerk - Laufwerk vorhanden ist und falls ja, welche Bezeichnung (DVDBez) und welche Geschwindigkeit (Geschw) es hat. Außerdem werden jeweils mit Hilfe einer Kurzbezeichnung (KBezSK) die sonstigen Komponenten (Streamer, SoundBlaster, externe Platten usw.) festgehalten. Jede dieser Komponenten ist genau einem PC zugeordnet. Ein PC hat natürlich typischerweise mehrere.
|
|
Die DVD – Laufwerke kommen modellierungstechnisch zu einer eigenen Existenz, da sie identifiziert und beschrieben werden. Also entsteht ein Entitätstyp DVD-LW. Damit ist auch die Frage beantwortet, wie festgehalten wird, ob ein PC eines hat oder nicht: über die Beziehung zwischen PC und DVD-LW. Dazu unten mehr. |
|
|
|
Abbildung 11.6-2: Entitätstyp CD-Rom – Laufwerke |
|
Für die sonstigen Komponenten ist die Situation einfacher. Da sie nur durch eine Kurzbezeichnung KBezSK identifiziert werden, entsteht hier einfach ein Attribut von PC, allerdings ein mehrwertiges, wie der Text auch ausdrücklich festhält. Insgesamt ergibt sich damit der Entitätstyp PC (erst mal) wie folgt: |
|
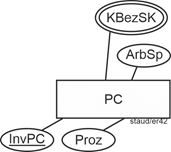
|
|
Abbildung 11.6-3: Entitätstyp PC – Version 1 |
|
Der nächsten Abschnitte der Spezifikation legt fest, wie die Festplatten erfasst werden: |
Festplatten |
- Für jede Festplatte wird festgehalten: Name und Größe (Plbez, Größe) sowie die Zugriffsgeschwindigkeit (Zugriff), die Seriennummer (SerNr) (diese ist eindeutig, auch über Hersteller hinweg) und der Tag, an dem die Platte in den Rechner eingebaut wurde (DatEinb).
- Ein PC kann mehrere Festplatten haben, eine Festplatte ist aber nur einem PC zugeordnet.
|
|
Hier liegt wiederum das Muster Einzel/Typ vor. Zum einen werden die einzelnen Festplatten identifiziert und beschrieben (SerNr, DatEinb), zum anderen die Fetplattentypen mit PlBez, Größe und Zugriff. Deshalb entstehen die beiden Entitätstypen FP-Einzeln und FP-Typ mit dem Beziehungstyp FP-T/E. Die Min-/Max-Angaben sind: |
Identifikation + Beschreibung |
- 1,1 bei FP-Einzeln, denn eine bestimmte Festplatte gehört zu genau einem Typ.
- 1,n bei FP-Typen, denn zu einem Festplattentyp gehören eine oder mehrere konkrete Festplatten.
|
|
Die Beziehung der Festplatten zu den PC wird unten geklärt. |
|
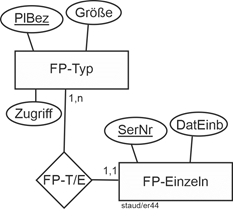
|
|
Abbildung 11.6-4: Entitätstyp Festplatten – erste Fassung |
|
Der folgende Ausschnitt aus der Spezifikation klärt das Umfeld der im Unternehmen eingesetzten PCs. |
|
- Für jeden PC wird weiterhin festgehalten, in welcher Abteilung er steht (Abteilung), wer ihn nutzt (erfasst über die PersNr) und wann er dort eingerichtet wurde (Einrichtung). Es kommt vor, wenn auch nicht oft, dass ein PC von mehreren Mitarbeitern genutzt wird. Allerdings ist er immer einer einzigen Abteilung zugewiesen.
|
|
Betrachten wir zuerst die Angabe der Abteilung, in der er steht. Würden irgendwo die Abteilungen noch weiter beschrieben, müsste ein eigener Entitätstyp für sie eingerichtet werden. Da dies hier nicht der Fall ist, wird Abteilung(sname) zu einem Attribut von PC. |
Umfeld der PC |
Wie erfassen wir den oben ebenfalls angeführten Einrichtungszeitpunkt? Hätten wir einen Entitätstyp Abteilungen, wäre alles einfach. Wir würden dann den Einrichtungszeitpunkt auf den Beziehungstyp zwischen Abteilungen und PC legen, denn da gehört er semantisch hin. Da hier aber die Abteilungen nicht als Entitätstyp gewünscht werden, bleibt nur die Notlösung, Einrichtung zu einem Attribut von PC zu machen. |
Pragmatik |

|
|
Abbildung 11.6-5: Entitätstyp PC – Version 2 |
|
Ähnliche Überlegungen wie bei der Klärung des Standortes (Abteilung) sind bei den Nutzern anzustellen. Sie werden in obigem Text nur über die Personalnummer erfasst. Insoweit wäre PersNr ein Attribut von PC. Da aber im nächsten Abschnitt der Spezifikation die Nutzer weiter modelliert werden, werden sie zu einem eigenen Entitätstyp Nutzer mit den angegebenen Attributen. |
|

|
|
Abbildung 11.6-6: Entitätstyp Nutzer |
|
Damit sind die Fragmente des Datenmodells zusammengestellt. Bleibt noch die Präzisierung durch Klärung eventueller Muster und der Zusammenhang, die Beziehungen zwischen den Entitätstypen. |
|
11.6.3 Präzisierung und Zusammenhänge |
|
Die Beziehung zwischen PC und Bildschirmen ist direkt im Text angegeben, bedarf aber der Klärung, ob Einzelgeräte oder Gerätetypen modelliert werden. Auf Seiten der PCs natürlich Einzelgeräte, dies zeigt auch der vorgeschlagene Schlüssel. |
PC – Bildschirme |
Bei den Bildschirmen deutet der Schlüssel InvBild an, dass unsere „Auftraggeber“ hier Einzelgeräte modelliert haben möchten. Damit hätten wir aber Redundanz, wenn wir die Modellierung so belassen wie oben vorgeschlagen und wenn wir einfach einen Beziehungstyp zwischen PC und Bildschirme platzieren. Wenn wir hundert technisch identische Bildschirme kaufen würden, würde unsere Datenbank hundertmal festhalten, dass diese (z.B.) 24 Zoll groß und vom Typ XYX sind. |
|
Wo liegt der Fehler? Ganz einfach, die vier Attribute von Bildschirme beschreiben unterschiedliche Informationsträger. InvBild und SerNr beschreiben Einzelgeräte, die beiden anderen (Zoll und BSTyp) aber die Gruppe der technisch gleichen Geräte, hier Gerätetypen genannt. BSTyp kann dafür als Schlüssel genommen werden. Also muss dieser Entitätstyp in zwei aufgespaltet werden, BS-Einzeln und BS-Typen, die aber verknüpft sind (Beziehungstyp PC-B; vgl. die folgende Abbildung): Ein bestimmter Bildschirm gehört zu genau einem Gerätetyp, ein Gerätetyp hat mindestens ein zugehöriges Gerät (sonst wäre er in unserer Datenbank nicht erfasst), kann aber beliebig viele haben. Wie meist beim Muster Einzel/Typ sind die Min-/Max-Angaben 1,1 bzw. 1,n. |
Muster Einzel/Typ |
Der Fehler resultierte also aus einem Verstoß gegen eine zentrale Regel der ER-Modellierung, dass nur die Attribute zu einem Entitätstyp genommen werden, die genau dessen Entitäten beschreiben. |
Verstoß gegen Zuordnungsregel |
|
|
Abbildung 11.6-7: Einzelgeräte und Gruppe gleichartiger Entitäten als Entitätstypen |
|
Die Beziehung PC_B zwischen Bildschirme und PC muss nun auf Seiten der Bildschirme 1,1 als Min-/Max-Angabe erhalten, da jetzt eine Entität genau einen Bildschirm beschreibt und ein Bildschirm genau einem PC zugeordnet ist. Auf Seiten der PCs erhält sie ebenfalls 1,1, da ja ein PC genau einen Bildschirm hat (vgl. die Gesamtgrafik am Schluss). |
|
Die Beziehung PC_F zwischen PC und Festplatten wird sinnvollerweise mit FP-Einzeln und nicht mit FP-Typ hergestellt. Dann ist die Zuordnung ganz klar und ma weiß, welche Festplatten in welchem PC integriert sind und wieviele Festplatten ein PC hat. |
Ungenauigkeit |
Die Beziehung DVD-PC zwischen DVD-LW und PC wie folgt: Der Entitätstyp DVD-LW modelliert auf Typebene. Damit ist die Min-/Max-Angabe bei den Laufwerken 1,n (da DVD-Laufwerke des gleichen Typs in mehreren PCs sein können) und bei den PCs 0,1 (da nicht jeder PC ein DVD – Laufwerk hat). |
|
Die Beziehung zwischen PCs und Nutzern ist wiederum im spezifizierenden Text festgelegt: „Es kommt vor, wenn auch nicht oft, dass ein PC von mehreren Mitarbeitern genutzt wird.“ Damit ergibt sich bei PC die Angabe 1,n. Durch Nachfrage haben wir herausbekommen, dass umgekehrt ein Nutzer ebenfalls mehrere PCs nutzen kann. Damit ergibt sich dort ebenfalls die Min-/Max - Angabe 1,n. |
|
Eine weitere Nachfrage ergab, dass man Nutzer und PC datenbanktechnisch auch schon anlegen möchte, wenn noch keine Zuordnung PC/Nutzer erfolgt ist. Deshalb wurde der jeweilige Minimumwert auf 0 geändert. |
0,n statt 1,n |
11.6.4 Das gesamte ER-Modell |
|
Die folgende Abbildung zeigt das Datenmodell im Zusammenhang. |
|
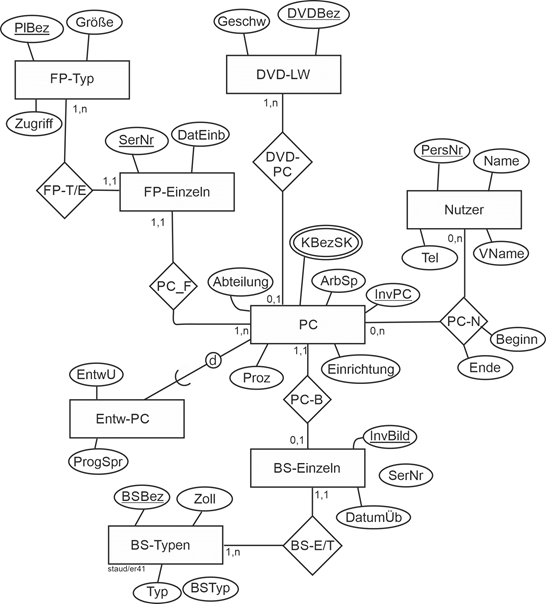
|
|
Abbildung 11.6-8: Anwendungsbereich PC-Nutzung – Gesamtmodell |
|
|
|
11.7 Sprachenverlag |
|
Zu diesem Beispiel gibt es: Aufgabenstellung + Lösungsweg |
|
Besonderes Lernziel dieses Beispiels ist, das Muster Generalisierung / Spezialisierung (GenSpez) ausführlich vorzustellen. |
|
11.7.1 Der Anwendungsbereich |
|
Es geht um die Produkte eines Verlages, der Wörterbücher (z.B. Deutsch / Englisch), digital oder auch gedruckt, herstellt und verkauft und der seit einiger Zeit auch Übersetzungsprogramme anbietet. Seine Produkte sollen in einer Datenbank verwaltet werden. Einige Attribute sind schon angeführt. Zu erfassen ist folgendes: |
|
- Alle Wörterbücher und Volltextübersetzer (vgl. unten) mit den Sprachen, die abgedeckt sind (z.B. Deutsch nach Englisch und Englisch nach Deutsch, Deutsch nach Französisch und Französisch nach Deutsch), …). Es ist grundsätzlich möglich, dass ein Wörterbuch auch nur eine Richtung abdeckt.
- Für jedes gedruckte Wörterbuch wird auch festgehalten, wie viele Einträge es hat (Einträge), für welche Zielgruppe es gedacht ist (Schüler, Studierende, „Anwender“, „Profi-Anwender“, Übersetzer) (Zielgruppe), wann es auf den Markt gebracht wurde (ErschDatum) und wie viele Seiten es hat (AnzSeiten).
- Für jedes digitale Wörterbuch wird auch festgehalten, wann es auf den Markt gebracht wurde (ErschDatum), welche Bezeichnung (SWBez) die aktuelle Software hat (z.B. Professional English 7.0), wie viele Einträge es hat (Einträge) und für welche Zielgruppe es gedacht ist (Schüler, Studierende, „Anwender“, „Profi-Anwender“, Übersetzer) (Zielgruppe).
- Für jeden „Volltextübersetzer“ (Programm zur automatischen Übersetzung) wird auch festgehalten, welche Sprachen abgedeckt sind, wie viele Einträge das Systemlexikon hat (Einträge), für welche Zielgruppe das Produkt gedacht ist und wann es auf den Markt gebracht wurde (ErschDatum). Festgehalten wird ob man den Käufern anbietet, es durch Internetzugriffe regelmäßig aktualisieren zu lassen. Falls ja, wie lange dies möglich ist (AktJahre), z.B. 5 Jahre ab Kauf.
- Die Volltextübersetzer beruhen jeweils auf einem Übersetzungsprogramm (SWBez). Es kann sein, dass ein Volltextübersetzer mit verschiedenen Programmen angeboten wird (z.B. Zielgruppenspezifisch). Natürlich dient ein Programm u.U. vielen Volltextübersetzern (z.B. Deutsch nach Englisch, Französisch nach Deutsch). Für diese Programme wird festgehalten, welche Dokumentarten (DokArt) sie auswerten können (Word, PDF, Bildformate, usw.) und ob es möglich ist, die Programmleistung in Textprogramme zu integrieren (IBK; Integrierbarkeit).
- Die Programme für die digitalen Wörterbücher werden nicht erfasst.
- Für die Programme der Volltextübersetzer werden außerdem die Softwarehäuser, die an der Erstellung mitgearbeitet haben, mit ihrer Anschrift (nur die Zentrale) festgehalten. Es wird auch die zentrale E-Mail-Adresse erfasst. Ein Programm stammt von einem einzigen Softwarehaus.
- Festgehalten wird auch, wann die Zusammenarbeit mit dem Softwarehaus bzgl. eines Programmes begann (Beginn) und – gegebenenfalls – wann sie endete (Ende). Diese Angaben sind natürlich i.d.R. je nach Produkt, bei dem zusammengearbeitet wurde, unterschiedlich.
- Für alle digitalen Produkte (Wörterbücher/Systemlexikon usw. + Programme) werden außerdem die Systemvoraussetzungen festgehalten. Welche minimale Hardwareanforderung (Hardware) gegeben ist (anhand des Prozessors), wieviel Arbeitsspeicher sie benötigen (ArbSpeich), wieviel freier Plattenspeicher (PlattSpeich) nötig ist (in MB) und welche Betriebssystemversion (BS) genutzt werden kann. Dies sind in der Regel mehrere.
- Für alle Produkte des Verlags werden die Bezeichnung (Bez), der Typ (Wörterbuch, Übersetzungsprogramm, …) sowie der Listenpreis (LPreis) erfasst.
|
|
11.7.2 Lösungsschritte |
|
Hier wird nun obiger Text Schritt für Schritt bearbeitet und das Datenmodell erarbeitet. |
|
Abschnitt 1 |
|
- Alle Wörterbücher und Volltextübersetzer (vgl. unten) mit den Sprachen, die abgedeckt sind (z.B. Deutsch nach Englisch und Englisch nach Deutsch, Deutsch nach Französisch und Französisch nach Deutsch), …). Es ist grundsätzlich möglich, dass ein Wörterbuch auch nur eine Richtung abdeckt.
|
|
Hier sind zwei Tatsachen ableitbar. Erstens, dass es wohl Wörterbücher und Volltextübersetzer als solche gibt – und zwar wahrscheinlich als „Spitze“ einer Generalisierungshierarchie. Nennen wir sie Produkte und geben ihnen den Schlüssel ProdNr. Zweites, dass die abgedeckten Sprachen zu erfassen sind, und zwar als mehrwertige Attribute an diesem Entitätstyp: |
Mehrwertiges Attribut Sprachen |
|
|
Abbildung 11.7-1: Entitätstyp Produkte – Version 1 |
|
Sprachen: mehrwertiges Attribut |
|
Nächste Abschnitte |
|
- Für jedes gedruckte Wörterbuch wird auch festgehalten, wie viele Einträge es hat (Einträge), für welche Zielgruppe es gedacht ist (Schüler, Studierende, „Anwender“, „Profi-Anwender“, Übersetzer) (Zielgruppe), wann es auf den Markt gebracht wurde (ErschDatum) und wie viele Seiten es hat (AnzSeiten).
|
|
Hier wird eine erste Spezialisierung deutlich: Gedruckte Wörterbücher. Sie werden WöBüBuch genannt und haben (erstmal) die oben angeführten Attribute. |
|
- Für jedes digitale Wörterbuch wird auch festgehalten, wann es auf den Markt gebracht wurde (ErschDatum), welche Bezeichnung (SWBez) die aktuelle Software hat (z.B. Professional English 7.0), wie viele Einträge es hat (Einträge) und für welche Zielgruppe es gedacht ist (Schüler, Studierende, „Anwender“, „Profi-Anwender“, Übersetzer) (Zielgruppe).
|
|
Damit ist die zweite Spezialisierung klar: digitale Wörterbücher. Dieser Entitätstyp wird WöBüDigital genannt. Da hier zum Teil dieselben Attribute wie in WöBüBuch auftauchen, gibt es also Attribute, die der Generalisierung zuzuordnen sind: Einträge, ErschDatum und Zielgruppe. Konkret ergibt sich damit insgesamt aus obigem das folgende ER-Modell-Fragment: |
|
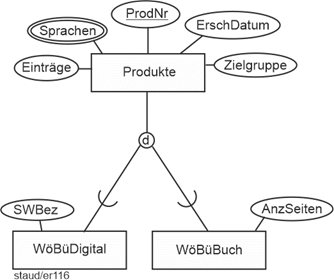
|
|
Es kann vermutet werden, dass die Generalisierung / Spezialisierung noch weitergeführt wird, deshalb legen wir eine Tabelle mit den zugehörigen Entitätstypen und Attributen an. |
|
Attributtabelle: Produkte und ihre Spezialisierungen - 1 |
|
| Alle Produkte |
Gedruckte Wörterbücher (WöBüBuch) |
Digitale Wörterbücher (WöBüDigital) |
| Sprachen |
Sprachen |
Sprachen |
| Einträge |
Einträge |
Einträge |
| Zielgruppe |
Zielgruppe |
Zielgruppe |
| ErschDatum |
ErschDatum |
ErschDatum |
| |
AnzSeiten |
|
| |
|
SWBez |
| |
So die erste Fassung der Matrix – noch völlig ungeordnet.
|
|
- Für jeden „Volltextübersetzer“ (Programm zur automatischen Übersetzung) wird auch festgehalten, welche Sprachen abgedeckt sind, wie viele Einträge das Systemlexikon hat (Einträge), für welche Zielgruppe das Produkt gedacht ist und wann es auf den Markt gebracht wurde (ErschDatum). Festgehalten wird ob man den Käufern anbietet, es durch Internetzugriffe regelmäßig aktualisieren zu lassen. Falls ja, wie lange dies möglich ist (AktJahre), z.B. 5 Jahre ab Kauf.
|
|
Dies zeigt eine weitere Spezialisierung, die Volltextübersetzer. Ergänzen wir damit unsere Attributtabelle: |
|
Attributtabelle: Produkte und ihre Spezialisierungen – 2 |
|
| Alle Produkte |
Gedruckte Wörterbücher (WöBüBuch) |
Digitale Wörterbücher (WöBüDigital) |
Volltextübersetzer (VTÜ) |
| Sprachen |
Sprachen |
Sprachen |
Sprachen |
| Einträge |
Einträge |
Einträge |
Einträge |
| Zielgruppe |
Zielgruppe |
Zielgruppe |
Zielgruppe |
| ErschDatum |
ErschDatum |
ErschDatum |
ErschDatum |
| |
AnzSeiten |
|
|
| |
|
SWBez |
|
| |
|
|
AktJahre |
| |
Das Attribut AktJahre legen wir ganz pragmatisch so an: Bei fehlender Aktualisierungsmöglichkeit wird ein sog. Null Value eingetragen, ansonsten die Zahl der Jahre.
|
Pragmatik |
Eine ganz korrekte Lösung bestünde darin, für die VTÜ mit Aktualisierungsmöglichkeit einen eigenen Entitätstyp anzulegen und dort das Attribut AktJahre hinzuzufügen. Dieser Entitätstyp wäre dann eine Spezialisierung von Volltextübersetzer. |
|
Bereinigen wir nun noch die Tabelle, indem wir die oberste Generalisierung mit all den Attributen ausstatten, die in allen untergeordneten Spezialisierungen vorkommen und alle Attribute in Spezialisierungen streichen, die in übergeordneten Generalisierungen vorkommen, ergibt sich folgende Tabelle: |
|
Attributtabelle: Produkte und ihre Spezialisierungen – 3 |
|
| Alle Produkte |
Gedruckte Wörterbücher (WöBüBuch) |
Digitale Wörterbücher (WöBüDigital) |
Volltextübersetzer (VTÜ) |
| Sprachen |
|
|
|
| Einträge |
|
|
|
| Zielgruppe |
|
|
|
| ErschDatum |
|
|
|
| |
AnzSeiten |
|
|
| |
|
SWBez |
|
| |
|
|
AktJahre |
| |
Damit wird folgende Generalisierung / Spezialisierung deutlich:
|
|
Die Zahl der Einträge, die Sprachen, die Zielgruppe und das Erscheinungsdatum (ErschDatum) erfassen wir weiterhin bei Produkte (weil alle Spezialisierungen diese Attribute aufweisen), das Attribut SWBez bei WöBüDigital, das Attribut AnzSeiten bei WöBüBuch und das Attribut AktJahre bei Volltextübersetzer. |
|
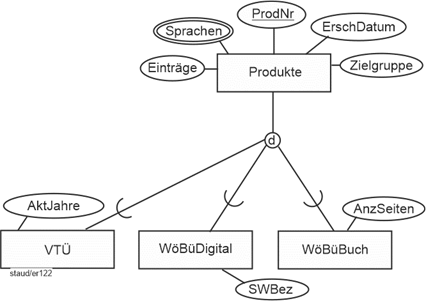
|
|
Abbildung 11.7-2: Generalisierung / Spezialisierung rund um Produkte |
|
Nächster Abschnitt |
|
- Die Volltextübersetzer beruhen jeweils auf einem Übersetzungsprogramm (SWBezVTÜ). Es kann sein, dass ein Volltextübersetzer mit verschiedenen Programmen angeboten wird (z.B. zielgruppenspezifisch). Natürlich dient ein Programm u.U. vielen Volltextübersetzern (z.B. Deutsch nach Englisch, Französisch nach Deutsch). Für diese Programme wird festgehalten, welche Dokumentarten (DokArt) sie auswerten können (Word, PDF, Bildformate, usw.) und ob es möglich ist, die Programmleistung in Textprogramme zu integrieren (IBK; Integrierbarkeit).
|
|
Hier werden nun die Übersetzungsprogramme zu einem Datenbankobjekt. Da gleich auch noch Attribute für die Programme angegeben werden, muss für sie tatsächlich ein Entitätstyp angelegt werden. |
Attribut zu Entitätstyp |
Programme können mehrere Dokumentarten auswerten, deshalb ist das Attribut DokArt mehrwertig: |
|
|
|
Abbildung 11.7-3: Entitätstyp Üb_Programme |
|
Es wird auch gleich die Beziehung zwischen Übersetzungsprogrammen und den Volltextübersetzern geklärt. Für diese muss ein eigener Beziehungstyp VÜ_P eingerichtet werden. |
|
|
|
Abbildung 11.7-4: Beziehungstyp VÜ_P |
|
Da ein Übersetzungsprogramm vielen Volltextübersetzern dienen kann, umgekehrt aber ein bestimmter Volltextübersetzer nur ein Übersetzungsprogramm hat, sind die Min-/Max-Angaben wie folgt: |
|
- 1:1 beim Entitätstyp VTÜ
- 1:n beim Entitätstyp ÜB_Programme
|
|
Nächste Abschnitte |
|
- Die Programme für die digitalen Wörterbücher werden nicht erfasst.
- Für die Programme der Volltextübersetzer werden außerdem die Softwarehäuser, die an der Erstellung mitgearbeitet haben, mit ihrer Anschrift (nur die Zentrale) festgehalten. Es wird auch die zentrale E-Mail-Adresse erfasst. Es kommt durchaus vor, dass ein Programm von mehreren Softwarehäusern erstellt wird.
- Festgehalten wird auch, wann die Zusammenarbeit mit dem Softwarehaus bzgl. eines Programmes begann (Beginn) und – gegebenenfalls – wann sie endete (Ende). Diese Angaben sind natürlich i.d.R. je nach Produkt, bei dem zusammengearbeitet wurde, unterschiedlich.
|
|
Der erste Abschnitt stellt klar, dass die Programme für die digitalen Wörterbücher lediglich als Attribut und nicht als eigener Entitätstyp erfasst werden sollen. |
|
Der zweite Abschnitt führt die Softwarehäuser als Datenbankobjekte ein, hier also als Entitätstyp. Erfasst wird eine einzige Anschrift sowie die zentrale Mail-Adresse. Der folgende Satz gibt den Hinweis, dass zwischen Programmen und Softwarehäusern eine n:m-Beziehung vorliegt, wenn man davon ausgeht, dass ein Softwarehaus im Zeitverlauf auch an mehreren Programmen des Verlags mitgearbeitet hat. Zusammen mit dem Hinweis auf die zu erfassenden Start- und Endtermine im dritten Abschnitt ergibt sich folgendes Modellfragment: |
|
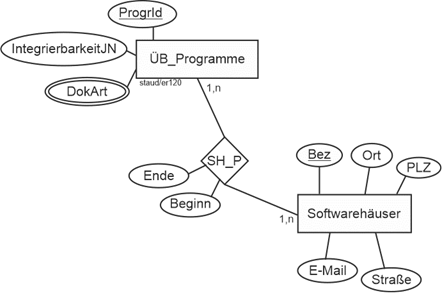
|
Attribute auf Beziehungstyp |
Abbildung 11.7-5: Beziehung zwischen Übersetzungsprogrammen und Softwarehäusern |
|
Nächster Abschnitt |
|
- Für alle digitalen Produkte (Wörterbücher/Systemlexikon usw. + Programme) werden außerdem die Systemvoraussetzungen festgehalten. Welche minimale Hardwareanforderung (Hardware) gegeben ist (anhand des Prozessors), wieviel Arbeitsspeicher sie benötigen (ArbSpeich), wieviel freier Plattenspeicher (PlattSpeich) nötig ist (in MB) und welche Betriebssystemversion (BS) genutzt werden kann. Dies sind in der Regel mehrere.
|
|
Obiger Punkt führt über die Festlegung der Systemanforderungen neue Attribute für alle digitalen Produkte ein. Ergänzen wir zur Klärung dieses Sachverhalts die Attributtabelle um diese Attribute: |
|
Attributtabelle: Produkte und ihre Spezialisierungen - 4 |
|
| Alle Produkte |
WöBüBuch |
WöBüDigital |
VTÜ |
| Sprachen / mehrwertig |
|
|
|
| Einträge |
|
|
|
| Zielgruppe |
|
|
|
| ErschDatum |
|
|
|
| |
AnzSeiten |
|
|
| |
|
SWBez |
|
| |
|
|
Erweiterbarkeit |
| |
|
Hardware |
Hardware |
| |
|
ArbSpeich |
ArbSpeich |
| |
|
PlattSpeich |
PlattSpeich |
| |
|
BS |
BS |
| |
Damit ergibt sich, dass WöBüDigital und VTÜ einige Attribute gemeinsam haben. Dies führt dazu, dass eine weitere Spezialisierung von Produkte angelegt wird, die in der Spezialisierungshierarchie zwischen Produkte und WöBüDigital / VTÜ liegt. Sie soll ProdukteDig genannt werden.
|
Weitere Spezialisierung |
Ergänzen wir obige Attribute in der Attributtabelle und streichen die Attribute der Generalisierung in ihren Spezialisierungen ergibt sich die folgende Attributtabelle. |
|
Attributtabelle: Produkte und ihre Spezialisierungen - 5 |
|
| Alle Produkte |
WöBüBuch |
ProdukteDig |
WöBüDigital |
VTÜ |
| Sprachen / mehrwertig |
|
|
|
|
| Einträge |
|
|
|
|
| Zielgruppe |
|
|
|
|
| ErschDatum |
|
|
|
|
| |
AnzSeiten |
|
|
|
| |
|
|
SWBez |
|
| |
|
|
|
Erweiterbarkeit |
| |
|
Hardware |
|
|
| |
|
ArbSpeich |
|
|
| |
|
PlattSpeich |
|
|
| |
|
BS / mehrwertig |
|
|
| |
Damit wird dann eine neue Generalisierungs- / Spezialisierungsstruktur deutlich. Der Entitätstyp ProdukteDig wird als Generalisierung der digitalen Wörterbücher und der Volltextübersetzer eingebaut.
|
|
Dies ist ein Beispiel dafür, wie durch die Generalisierung / Spezialisierung die Attribute des Datenmodells und später der Datenbank effizient angelegt werden. |
|
Die Information zu den Betriebssystemversionen wird als mehrwertiges Attribut von ProdukteDig angelegt. Damit ergibt sich folgendes Modellfragment: |
|
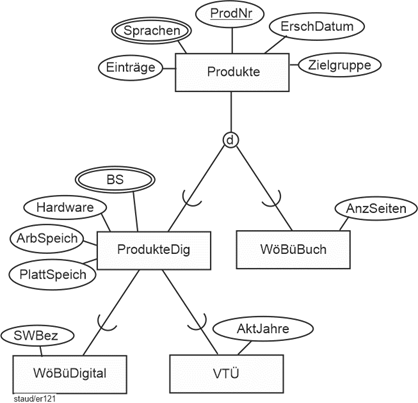
|
|
Abbildung 11.7-6: Generalisierung / Spezialisierung rund um Produkte – Endfassung |
|
Wie hier gerade zu sehen war, kann durch weitere Modellinformationen eine bestehende Generalisierung / Spezialisierung verändert werden. Dies kommt nicht selten vor. |
|
Was die obigen Attributtabellen vielleicht auch deutlich gemacht haben ist, dass für die Bewältigung komplexer Generalisierungs- / Spezialisierungsstrukturen diese Tabellen ein hilfreiches Werkzeug sind. |
|
Letzter Abschnitt |
|
- Für alle Produkte des Verlags werden die Bezeichnung (Bez), der Typ (Wörterbuch, Übersetzungsprogramm, …) sowie der Listenpreis (LPreis) erfasst.
|
|
Mit diesen Attributen vervollständigen wir den Entitätstyp Produkte. |
|
11.7.3 Das gesamte ER-Modell |
|
Fügt man die einzelnen Modellfragmente zusammen, ergibt sich das folgende Entity Relationship - Modell für den Anwendungsbereich Sprachenverlag. |
|
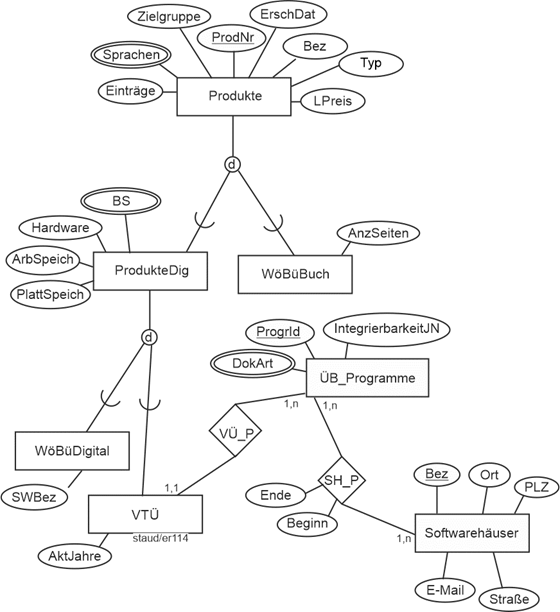
|
|
Abbildung 11.7-7: ER-Modell Sprachenverlag – Endfassung |
|
|
|

|
|
|
|
11.8 Hochschule – Vorlesungsbetrieb |
|
Zu diesem Beispiel gibt es die Aufgabenstellung und den Lösungsweg |
|
Anwendungsbereich Vorlesungsbetrieb einer Hochschule. Folgendes soll erfasst werden: |
|
- Besuch von Vorlesungen durch Studierende
- Besuch von Prüfungen durch Studierende
- Durchführung von Lehrveranstaltungen durch Dozenten
|
|
Folgendes soll erfasst werden: |
|
- Die Lehrveranstaltungen (LV) als solche mit ihrer Bezeichnung (BezLV) und der Angabe des Semesters, indem sie nach Studienplan stattfinden (SemPlan). Außerdem soll festgehalten werden, in welchem Studiengang (BezSG) sie stattfinden (Bachelor WI, Bachelor AI, Master WI, usw.) und von welchem Typ sie sind (Typ; Vorlesung, Übung, Projekt).
- Die Prüfungen, die Studierende besuchen. Dabei soll die Art der Prüfung (ArtPrüfung), die zugehörige Lehrveranstaltung (BezVeranst), die Bezeichnung des Studienganges (BezStudiengang) und die erzielte Note erfasst werden. Für Klausuren außerdem die Voraussetzungen, um den wievielten Versuch es sich handelt (Versuch) und die Länge. Für mündliche Prüfungen ebenfalls die Länge und wieviele Prüfer anwesend sein müssen (ZahlPrüfer). Für jeden Besuch einer Prüfung wird festgehalten, in welchem Semester er erfolgte und welche Note erzielt wurde.
- Die Dozenten mit Name, Vorname, E-Mail , Telefonnummer (Tel) und Typ (intern / extern). Für die internen Dozenten werden die Sprechstunden (Sprechst) erfasst, für die externen die private und. geschäftliche Telefonnummer, die Organisation, in der sie tätig sind (Org) und die Adresse (PLZ, Ort, Straße)
- Die konkreten Termine einer jeden Lehrveranstaltung mit Tag, Beginn, Ende, Raum, Semester (die Redundanz, die in der gleichzeitigen Erfassung von Tag und Semester liegt, wird akzeptiert).
- Die Studierenden mit Matrikelnummer (MatrNr), Namen (Name), Vornamen (Vorname), Mail-Account (E-Mail) und ihren Adressen (Heimatadresse, Adresse am Studienort, usw.) mit PLZ, Ort und Straße.
- Welcher Dozent welche Lehrveranstaltung grundsätzlich zu halten bereit (und fähig) ist und welcher Dozent welche Lehrveranstaltung ganz konkret gehalten hat.
- Welche konkreten Termine bei jeder Lehrveranstaltung realisiert werden und wer sie durchführt. Es ist durchaus möglich, dass sich mehrere Dozenten die Veranstaltungstermine einer Lehrveranstaltung aufteilen.
- Der Besuch der einzelnen Veranstaltungstermine durch die Studierenden. An dieser Hochschule ist es üblich, die Anwesenheit zu kontrollieren. Deshalb wird für jeden Veranstaltungstermin einer LV festgehalten, welche Studierenden anwesend waren.
|
|
11.8.1 Entitätstypen |
|
Als Entitäten und Entitätstypen sofort erkennbar sind die Lehrveranstaltungen (LV). Sie werden identifiziert und beschrieben. |
|
Die Attribute sind angegeben, wir ergänzen lediglich einen numerischen Schlüssel (LVNr), da mit ihm in der Datenbankpraxis besser umzugehen ist. |
|
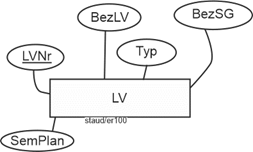
|
|
Abbildung 11.8-1: Beispiel Hochschule – Lehrveranstaltungen (LV) |
|
Nun die Prüfungen, die im zweiten Spiegelstrich angefordert werden. Es wird ausgeführt, dass es sich um die konkreten einzelnen Prüfungen handelt, nicht um die abstrakten Prüfungen des Studienplanes. |
Prüfungen |
Hier muss erkannt werden, dass eine Generalisierung / Spezialisierung vorliegt. Die Generalisierung wird Prüf_Allg genannt. Die Spezialisierungen sind Klausuren (Prüf_Kl) mit den spezifischen Attributen Versuch und Voraussetzung und mündliche Prüfungen (Prüf_MP) mit ZahlPrüfer. |
|
Auch hier wurde wieder ein numerischer Schlüssel ergänzt (PrüfNr). Damit ergibt sich das folgende Modellfragment. |
|
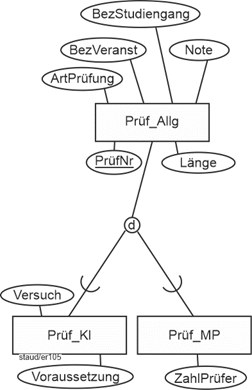
|
|
Abbildung 11.8-2: ER-Modell Hochschule – Prüfungen |
|
Auch beim Entitätstyp der Dozenten, muss erkannt werden, dass die Attribute in eine Generalisierung / Spezialisierung hinein aufgelöst werden müssen. Es gibt Attribute, die für alle Dozenten Gültigkeit haben (der Entitätstyp wird Doz_Allg genannt) und weitere, die nur auf externe Dozenten (Doz_Extern) und interne Dozenten (Doz_Intern) anwendbar sind. Mit einem hinzugefügten numerischen Schlüssel (DozNr) ergibt sich folgende Aufteilung: |
Gen/Spez bei Dozenten |
- Doz_Allg erhält DozNr, Name, Vorname, E-Mail und Telefon. Da wir in der Anforderung sehen, dass für die externen Dozenten die private und die geschäftliche Telefonnummer erfasst werden sollen, legen wir dieses Attribut als mehrwertiges an.
- Doz_Intern erhält das Attribut Sprechst.
- Doz_Extern erhält die Attribute PLZ, Ort, Straße und Org.
|
|
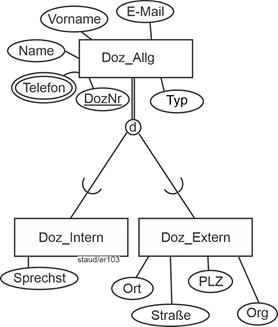
|
|
Abbildung 11.8-3: ER-Modell Hochschule – Dozenten |
|
Als nächstes werden in der Anforderungsliste Studierende genannt. Sie gibt es ganz sicher als Entitätstyp („Identifizierung + Beschreibung“) mit den Attributen MatrNr, Name, Vorname und E-Mail. |
Studierende |
Da die Erfassung mehrerer Adressen angefordert wird, wird ein eigener Entitätstyp notwendig (Adressen). Er erhält die Attribute PLZ, Ort und Straße. Wir ergänzen wieder einen Schlüssel: AdressNr. |
Adressen |
Nun die Beziehung. Die Min-/Max-Angabe bei Studierende ist sicher 1,n. Doch was ist mit der Min-/Max-Angabe bei Adressen? Eigentlich 1,1. Allerdings ist es so, dass verschiedene Studierende auch dieselbe Adresse haben können (Wohnheim, Hochhaus, usw.). Damit wird die Min-/Max-Angabe bei Adressen auch 1,n. Der dabei entstehende Beziehungstyp wird StudAdr genannt. |
|
Oft wird an dieser Stelle gefragt, ob man hier nicht als Min-Angabe jeweils 0 nehmen kann. Ja, das kann man. Man lässt dann zu, dass es Einträge in die Datenbank gibt für Studierende (noch) ohne Adresse und Adressen ohne Studierende. |
|
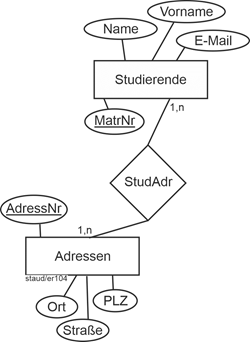
|
|
Abbildung 11.8-4: ER-Modell Hochschule – Studierende mit ihren Adressen |
|
Im nächsten Punkt werden die Dozenten angesprochen. Erfasst werden soll, welche Lehrveranstaltung (LV) ein Dozent grundsätzlich zu halten bereit ist. Eine notwendige Information für die Planung der Lehre. Dies kann durch einen Beziehungstyp Lehrfähigkeit zwischen LV und Doz_Allg gelöst werden. Für die konkret gehaltenen Lehrveranstaltungen legen wir einen Beziehungstyp Lehrtätigkeit an. Er muss mit Attributen versehen werden: Semester (SS, WS) und Jahr (in dem das Semester beginnt. Auf Nachfrage erfahren wir, dass hin und wieder Veranstaltungen geteilt und mehrfach gehalten werden müssen, u.U. vom selben Dozenten. Deshalb ergänzen wir noch das Attribut Nr. Die Wertigkeit dieser Beziehungen wird unten betrachtet. |
Dozenten und Lehre |
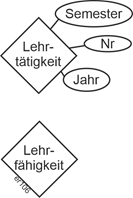
|
|
Abbildung 11.8-5: ER-Modell Hochschule – Lehrfähigkeit und Lehrtätigkeit |
|
Als nächstes wird in der Anforderungsliste gefordert, zu erfassen, welche Termine bei jeder Lehrveranstaltung (LV) konkret durchgeführt werden. Dazu müssen wir einen Entitätstyp Veranstaltungstermine anlegen. Hier muss man erkennen, dass die einzelnen Termine existenzabhängig sind von ihren Lehrveranstaltungen. Ohne Lehrveranstaltung keine Termine, bzw., wenn dann später eine LV aus der Datenbank gelöscht wird, müssen auch die zugehörigen Termine gelöscht werden. Es handelt sich also um einen singulären Entitätstyp. Die Attribute legen wir wie folgt fest: Semester, Tag, Beginn, Ende, Raum. Damit sind die einzelnen Termine eindeutig festgelegt. Für den Schlüssel genügt Tag, Beginn, Raum, da dies bereits eindeutig ist. In der Praxis wird hier oft ein Schüssel generiert, z.B. VTerminId („20211200800M220“), wir belassen es hier beim zusammengesetzten Schlüssel. |
Dozenten und LV-Termine |
Die Beziehung besteht ja zum Entitätstyp LV, der Beziehungstyp wird deshalb LVT genannt (siehe Abbildung). Um die weitere Beziehung und um die Wertigkeiten kümmern wir uns unten, im „Beziehungsteil“. |
|
Redundanz im Datenmodell? |
|
Das Attribut Semester könnte auch aus den Datumsangaben und dem Wissen, wann das Semester beginnt und endet berechnet werden. Dann müßte aber der Anfang und das Ende der Semester in den einzelnen Jahren auch in der Datenbank hinterlegt werden und jede Abfrage hätte dies zu berücksichtigen. Hier wird deshalb der einfachere Wege gewählt, die Semesterangabe bei den Terminen zu hinterlegen, auch wenn dadurch Redundanz entsteht. |
|
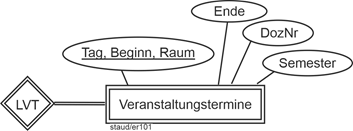
|
|
Abbildung 11.8-6: ER-Modell Hochschule – Veranstaltungstermine |
|
11.8.2 Beziehungstypen |
|
In der folgenden Abbildung sind die obigen Fragmente zusammengefügt und die jetzt betrachteten Beziehungen vermerkt. |
|
Nachdem die Entitätstypen modelliert sind, können jetzt die noch nicht modellierten Beziehungen betrachtet werden. |
|
Wie sehen die Min-/Max-Angaben bei der Beziehung |
LVT |
LV – LVT – Veranstaltungstermine |
|
aus? Auf der Seite des singulären Entitätstyps 1,1, denn ein Termin gehört zu genau einer Lehrveranstaltung. Beim Entitätstyp LV ergibt sich 1,n, da eine Lehrveranstaltung mindestens einen Termin hat, i.d.R. aber mehrere. |
|
In der Anforderungsliste ist auch gefordert, dass festgehalten wird, welcher Dozent ganz konkret welchen Veranstaltungstermin wahrnimmt. Der Beziehungstyp wird DVT (Dozenten – Veranstaltungstermine) genannt. Damit geht es um folgende Beziehung: |
DVT |
Doz_Allg – DVT – Veranstaltungstermine |
|
Es ist hier wohl so, dass die Termine einer Lehrveranstaltung auch zwischen mehreren Dozenten aufgeteilt werden können. Damit ergeben sich folgende Min-/Max-Angaben: |
|
- 1,n bei Doz_Allg.
- 1,x bei Veranstaltungstermine. x hängt von den Gepflogenheiten der Hochschule ab. Wieviele Dozenten dürfen maximal einen Veranstaltungstermin wahrnehmen. Normalerweise ist x gleich 2. Somit ergibt sich als Min-/Max-Angabe 1,2.
|
|
Nun die Beziehung |
Lehrfähigkeit |
LV – Lehrfähigkeit – Doz_Allg |
|
Typischerweise gilt: Ein Dozent kann eine oder mehrere Lehrveranstaltungen halten. „Eine“ z.B. im Fall von externen Lehrbeauftragten, „mehrere“ bei Hauptamtlichen, denn dafür wurden sie berufen. |
|
Umgekehrt gilt, dass eine Lehrveranstaltung normalweise von mindestens einem Dozenten gehalten werden kann. Da wir aber später auch neue Lehrveranstaltungen in der Datenbank anlegen wollen, für die wir u.U. nicht gleich einen Dozenten haben, wählen wir hier als Min-Angabe 0. Insgesamt also 0,n. |
|
Für die Beziehung |
Lehrtätigkeit |
LV – Lehrtätigkeit – Doz_Allg |
|
gilt: Ein Dozent hält in einem Semester keine (Praxissemester), eine oder mehrere Lehrveranstaltungen und eine Lehrveranstaltung wird von mindestens einem oder auch mehreren Dozenten gehalten. Daraus folgen 1,n bei LV und 0,m bei Doz_Allg. |
|
Werfen wir einen Blick auf die später entstehende Datenbank: |
|
Dadurch, dass die Lehrtätigkeit zum einen über die Lehrveranstaltung als Ganzes und zum anderen über die einzelnen Veranstaltungstermine erfasst wird, ergibt sich Redundanz. Aus dem Halten der Termine könnte die Lehrtätigkeit abgeleitet werden. Ganz pragmatisch, um die späteren SQL-Abfragen nicht zu verkomplizieren, wird hier die Lösung über den Beziehungstyp Lehrtätigkeit gewählt. |
|
Möglich wäre hier auch, die Lehrtätigkeit nicht eingeben, sondern aus DVT berechnen zu lassen. Dann wäre ein abgeleitetes Attribut nötig. |
|
Bei VTBesuch geht es um den Besuch der einzelnen Veranstaltungstermine durch Studierende (Veranstaltungsterminbesuch; VTBesuch). Der Beziehungstyp muss zwischen Veranstaltungstermine und Studierende eingefügt werden: |
VTBesuch |
Veranstaltungstermine – VTBesuch – Studierende |
|
Die Min-/Max-Angaben ergeben sich wie folgt: x,n bei Studierende. „x“ steht für die Mindestanzahl von Terminen, die besucht werden müssen. Bei einer dem Verfasser bekannten Hochschule darf man von 13 Semesterwochen höchstens drei fehlen. Also wäre hier x gleich 10, die Wertigkeit also 10,13. Dies hängt aber von der Prüfungsordnung der Hochschule ab. |
|
Für jeden Veranstaltungstermin gilt, dass mindestens 3 Studierende anwesend sein müssen, woraus sich 3,n ergibt. |
|
Die nächste Beziehung betrifft den Prüfungsbesuch. Der Beziehungstyp PrüfBesuch wird zwischen Studierende und Prüf_Allg eingefügt: |
PrüfBesuch |
Studierende – PrüfBesuch – Prüf_Allg. |
|
Er erhält das Attribut Semester, durch das festgehalten wird, in welchem Semester der Besuch der Prüfung erfolgte und ein Attribut (erzielte) Note. |
|
Die Wertigkeiten sind wie folgt: Ein Studierender besucht keine, eine oder mehrere Prüfungen pro Semester (0,n). Eine Prüfung wird von mindestens einem Studierenden besucht (1,m). |
|
11.8.3 Gesamtmodell |
|
Hier nun das Gesamtmodell einschließlich aller Beziehungen. |
|
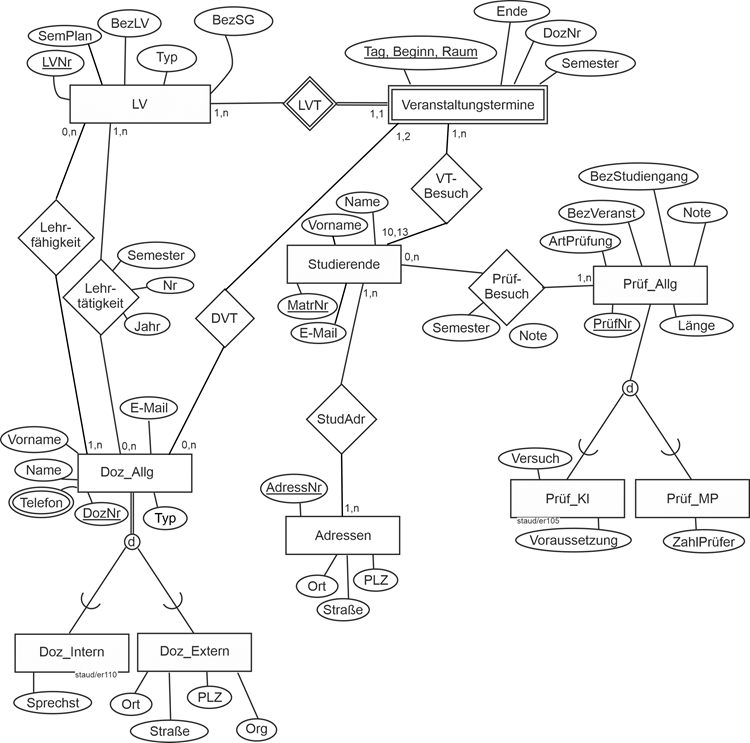
|
|
Abbildung 11.8-7: ER-Modell Hochschule |
|
|
|
|
|
12 SERM – Strukturierte Entity-Relationship-Modelle |
|
Vgl. zu dieser Methode auch den Wikipedia-Eintrag „Structured-Entity-Relationship-Modell“. |
|
Sinz schlägt in seiner Erweiterung des Entity Relationship - Ansatzes (vgl. [Sinz 1990]) einige Veränderungen vor, die praktische Bedeutung gewannen und die zu sog. Strukturierten Entity Relationship - Datenmodellen (SERM) führten. Besondere Bedeutung gewann dieser Ansatz, weil die semantische Datenmodellierung der SAP auf diesem Ansatz aufbaut(e). |
Von ERM zu SERM |
|
|
12.1 Grundkonzepte |
|
Dieser Modellierungsansatz geht von den üblichen ER-Konzepten aus, wie sie oben dargestellt wurden. Es entstehen also graphisch ausgedrückte semantische Modelle mit Elementen (die Informationen erfassen) und Beziehungen zwischen diesen. Die Beziehungen haben ebenfalls Wertigkeiten, dafür werden aber hauptsächlich die Min-/Max-Angaben und nicht die Kardinalitäten genutzt. |
|
Für dieses Kapitel gilt: Wenn es um ER-Modelle geht, wird die in den obigen Kapiteln eingeführte Begrifflichkeit und grafische Notation verwendet, wenn es um strukturierte ER-Modelle geht, die von Sinz. |
Hinweis |
Die Begriffe |
|
| ER-Modellierung |
Strukturierte ER-Modellierung |
| Entitätstyp |
Entity-Typ (E-Typ) |
| Kombinierter Typ 1 |
Relationship-Typ (R-Typ) |
| Kombinierter Typ 2 |
Entity Relationship - Typ (ER-Typ): Entity-Typ + Relationship-Typ |
| |
|
| Min-/Max-Angabe |
Komplexitätsgrad |
| |
Für die Schreibweise einer Min-/Max-Angabe gilt: 0,n in Entity Relationship - Modellen, (0,*) in der SER-Modellierung.
|
|
Unter Hinweis auf die gegenüber Kardinalitäten höhere Aussagekraft der Min-/Max-Angaben definiert Sinz vier Grundtypen von Komplexitätsgraden: (0,1), (0,*), (1,1), (1,*). Der Stern steht in dieser Notation für „mehrere“. |
|
N:m - Beziehungen werden in zwei 1:n - Beziehungen aufgelöst, so dass er in Bezug auf ein Universitätsbeispiel schreiben kann: |
Zwei mal
1:n
statt n:m |
"Zwischen Studierenden und Vorlesungen liegt sicherlich – z.B. in einem Universitätsdatenmodell – eine n:m - Beziehung vor, da ein Studierender mehrere Vorlesungen besucht und eine Vorlesung von mehreren Studierenden besucht wird." [Sinz 1990] |
|
Betrachten wir ein Beispiel. |
|
|
|
Abbildung 12.1-1: Min-/Max-Angaben mit der Methode SERM |
|
Hier wurde festgelegt, dass ein Studierender tatsächlich auch mal (in einem Semester) keine Vorlesungen hören, dass er aber auch beliebig viele besuchen kann. Umgekehrt wird festgelegt, dass eine Vorlesung von mindestens 5 Studierenden besucht werden muss, dass diese Zahl aber auch höher sein kann. |
|
Jede solche n:m - Beziehung wird in diesem Ansatz in zwei 1:n - Beziehungen zerlegt, was im Folgenden gezeigt wird. |
|
Sinz weist richtig darauf hin, dass alle "normalen" Varianten und Erweiterungen des ERM "bipartite Graphen" darstellen, während sein Ansatz SERM einen "quasi-hierarchischen Graph" darstellt. Auch dies wird im weiteren erläutert. Die Begriffe Knoten und Kanten, die hier hin und wieder benutzt werden, stammen aus der Graphentheorie. |
Vgl. für eine Einführung in die Graphentheorie [Diestel 2017] |
Gehen wir für die weiteren Ausführungen von der Darstellung und Notation in [Sinz 1990] aus, wie sie die folgende Abbildung zeigt. |
|
|
|
Abbildung 12.1-2: Darstellung und Notation bei Sinz |
|
Sinz bezeichnet die Kardinalität zwischen A und B mit b(A,B) und die Min-/Max-Angaben mit Komplexitätsgrad comp(A,b) bzw. comp(B,b). Er kommt dann bezüglich der möglichen Komplexität der Beziehung b(A,B) zu folgender Tabelle: |
|
Komplexitätsgrade und Kardinalitäten |
|
| b(A,B) |
comp(A,b) |
comp(B,b) |
| 1:1 |
(0,1) oder (1,1) |
(0,1) oder (1,1) |
| 1:N |
(0,*) oder (1,*) |
(0,1) oder (1,1) |
| N:1 |
(0,1) oder (1,1) |
(0,*) oder (1,*) |
| M:N |
(0,*) oder (1,*) |
(0,*) oder (1,*) |
| |
Betrachten wir als Beispiel die zweite Zeile genauer unter Bezugnahme auf die obige Grafik. Die Kardinalität 1:n umfasst tatsächlich die angegebenen Fälle:
|
|
- comp(A,b)=(0,*) bedeutet, dass ein Objekt von A nicht an der Beziehung teilhaben muss, dass es aber auch an mehreren Beziehungen teilhaben kann.
- comp(A,b)=(1,*) bedeutet, dass jedes Objekt von A mindestens eine Beziehung eingeht, dass es aber auch an mehreren Beziehungen teilhaben kann.
- comp(B,b)=(0,1) bedeutet, ein Objekt von B nicht an der Beziehung teilhaben muss und falls dies doch der Fall ist, mit maximal einer Beziehung.
- comp(B,b)=(1,1) bedeutet, dass jedes Objekt von B genau eine Beziehung eingeht.
|
|
12.2 Existenzabhängigkeit |
|
Mit Hilfe dieses Konzepts definiert er nun Existenzabhängigkeiten. Er greift dabei auf das Konzept der referentiellen Integritätsbedingungen (vgl. [Staud 2021, Abschnitt 5.2]) der relationalen Datenmodellierung zurück. Dabei werden |
|
"... in einer Beziehung b(A,B) Existenzabhängigkeiten nicht zwischen den Entity-Typen A und B, sondern zwischen dem Relationship-Typ b und einem Entity-Typ angegeben. Während A und B nicht notwendig voneinander abhängen, hängt b stets von A und B ab." [Sinz 1990] |
|
Damit kommt er zu zwei Formen der Existenzabhängigkeit eines Relationship-Typs b von einem Entity-Typ E (vgl. die folgende Grafik): |
|
- Einseitige Existenzabhängigkeit (b hängt von E ab): comp(E,b)=(0,1) oder comp(E,b)=(0,*)
- Wechselseitige Existenzabhängigkeit (b und E sind wechselseitig abhängig): comp(E,b)=(1,1) oder comp(E,b)=(1,*).
|
|
|
|
Abbildung 12.2-1: Einseitige und wechselseitige Existenzabhängigkeiten |
|
Von zentraler Bedeutung für den Ansatz ist nun folgende Festlegung: |
|
"Ein Entity-Typ wird mit denjenigen Relationship-Typen, mit denen er durch eine (1,1) - Beziehung verbunden ist, zu einem Entity-Relationship-Typ (ER-Typ) zusammengefasst. Gegenüber dem ERM entsteht dadurch ein dritter Objekttyp. Im SER-Diagramm ist ein ER-Typ sowohl Zielknoten (R-Anteil) als auch Startknoten (E-Anteil) von Kanten." [Sinz 1990, S. 26] |
|
Ein „dritter Objekttyp“ entsteht, weil er noch einen Relationship-Typ (R-Typ) einführt, der durch den entsprechenden Typ der ER-Modellierung motiviert ist. Er ist allerdings anders definiert, dazu unten mehr. |
|
Insgesamt führt Sinz damit drei verschiedene Knoten ein: den normalen Entity-Typ, den Entity-Relationship-Typ (ER-Typ) und den Relationship-Typ (R). Die grafische Darstellung der beiden neuen Grafikelemente ist wie folgt: |
|


|
|
Betrachten wir zur Verdeutlichung das Beispiel aus [Sinz 1990]. Zuerst in der ganz normalen ERM-Darstellung, wie in den ersten Kapiteln dargestellt. Das Beispiel sollte weitgehend selbsterklärend sein. |
|
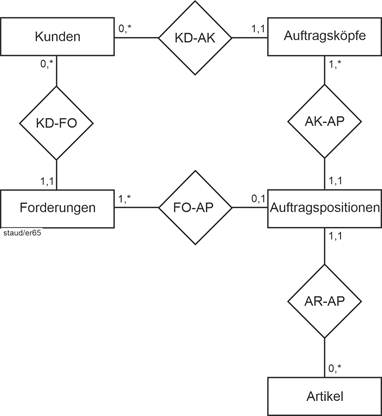
|
|
Abbildung 12.2-2: ER-Modell Kunden – Aufträge – Artikel
Quelle: [Sinz 1990, S. 21]. |
|
Der Entitätstyp Forderungen erfasst Forderungen, die gegenüber Kunden bzgl. bestimmter Auftragspositionen bestehen: |
|
- Eine Forderung bezieht sich auf eine Auftragsposition oder mehrere.
- Zu einer Auftragsposition gibt es keine oder eine („maximal eine“) Forderung.
|
|
Umwandlung: ERM zu SERM |
|
Wir wandeln nun dieses ERM in ein SERM um, wobei gleichzeitig auch die relationale Umsetzung angegeben wird. |
|
Für die Pfeilspitzen gilt: |
|
- Einfache Pfeilspitze: Bezug auf eine Entität des Ziels
- Doppelte Pfeilspitze: Bezug auf mehrere Entitäten des Ziels
- Senkrechter Strich vor den Pfeilspitzen: Beziehung ist – vom Start aus gesehen, optional.
- Kein senkrechter Strich: Eine Entität des Startelements muss teilhaben
|
|
Beginnen wir mit dem Fragment Kunden / Forderungen. Gemäß den Min-/Max-Angaben bleibt Kunden als Entity-Typ erhalten. Wegen der Min-/Max-Angabe 1,1 bei Forderungen wird aus KD-FO und Forderungen der ER-Typ Forderungen. Vgl. dazu die folgende Abbildung. In dieser ist auch die relationale Form dieses Fragments angegeben: Die Relation Forderungen erhält den Fremdschlüssel KundenNr. Es gibt also keine Forderungen, die nicht mit einem Kunden verknüpft sind. |
Kunden / Forderungen |
Wegen der Forderung nach referentieller Integrität, wie sie in der relationalen Theorie (sinnvollerweise) gefordert wird. Vgl. [Staud 2021, Abschnitte 5.2 und 5.9]. |
|
Die Pfeilspitze beim SERM-Fragment drückt aus, dass zu einem Kunden keine, eine oder mehrere Forderungen bestehen. Die 1,1-Angabe im ERM ist im SERM durch die Verschmelzung, die zum ER-Typ geführt hat, eingebaut. |
|

|
|
Abbildung 12.2-3: Vom ERM zum SERM – Fragment Kunden / Forderungen |
|
Die graphische Anordnung der SERM-Elemente erfolgt bewusst so wie in der obigen Abbildung. In SER-Modellen werden, wie weiter unten gezeigt wird, die E-, ER- und R-Typen von links nach rechts in Spalten angeordnet, gemäß ihrem Abhängigkeitsgrad. |
|
Nun das Fragment Kunden / Auftragsköpfe. Hier liegen dieselben Min-/Max-Angaben vor, wie im vorigen Fragment. Kunden liegt ja schon als Entity-Typ vor, Auftragsköpfe wird zum ER-Typ. Vgl. die folgende Abbildung, auch wiederum mit der relationalen Umsetzung. |
Kunden / Auftragsköpfe |
|
|
Abbildung 12.2-4: Vom ERM zum SERM – Fragment Kunden / Auftragsköpfe |
|
Betrachten wir nun das Fragment Auftragsköpfe / -positionen /Artikel. Hier liegt bei den Auftragspositionen zweimal die Min-/Max-Angabe 1,1 vor, so dass Auftragspositionen ein ER-Typ mit Verknüpfungen zu Auftragsköpfe und Artikel wird. Da Auftragsköpfe von Kunden abhängig ist, denken wir dafür eine weitere Spalte an. Artikel ist unabhängig und bekommt deshalb in der Abbildung einen Platz ganz links, sozusagen in Spalte 1. Auftragsköpfe in Spalte 2 und Auftragspositionen in Spalte 3. Die folgende Abbildung zeigt das SERM-Fragment. In diesem sind die auch Wertigkeiten angegeben: |
Auftragsköpfe / -positionen /Artikel |
- Ein Auftragskopf muss mindestens eine Auftragsposition haben.
- Ein Artikel kann in keiner, einer oder mehreren Auftragspositionen vorhanden sein
|
|
Das relationale Fragment zeigt die Umsetzung in relationale Strukturen. In Auftragspositionen wird die ArtikelNr als Fremdschlüssel übernommen. Als Schlüssel nehmen wir die AuftrNr und wegen der Differenzierung nach Positionen noch die Positionsnummer (PosNr), womit die Min-/Max-Angaben erfüllt sind: Jede Auftragsposition muss eine Auftragsnummer haben und zu jedem Auftragskopf gibt es mindestens eine Auftragsposition. |
|
|
|
Abbildung 12.2-5: Vom ERM zum SERM – Fragment Auftragsköpfe / -positionen /Artikel |
|
Nun zum Fragment Forderungen / Auftragspositionen. Nach dem Entity Relationship - Modell gilt: Eine Forderung bezieht sich auf mindestens eine Auftragsposition. Zu einer Auftragsposition kann es maximal eine einzige Forderung geben. |
Forderungen / Auftragspositionen |
Forderungen gibt es schon als ER-Typ, Auftragspositionen ebenfalls. Es gibt keine 1,1-Angabe, so dass kein ER-Typ entstehen kann. Dafür ist der Relationship-Typ (R-Typ) gedacht. Dies wird auch anhand der relationalen Umsetzung klar. Eine solche Struktur (0 als Min-Angabe) erfordert eine eigene Relation. |
|
Die Pfeilspitzen beim R-Typ drücken die Beziehungswertigkeiten korrekt aus: |
|
- Zu jeder Forderungsauftragsposition gibt es mindestens eine Forderung.
- Zu jeder Forderungsauftragsposition gibt es keine oder maximal eine Auftragsposition.
|
|
Der untere Teil der Abbildung zeigt wiederum die relationale Umsetzung. FO-AP erhält einen zusammengesetzten Schlüssel, bestehend aus der ForderungsNr und dem wiederum zusammengesetzten Schlüssel (AuftrNr, PosNr). Zusammengesetzte Schlüssel signalisieren höchste Abhängigkeit. Wegen der elementaren Forderung nach Vollständigkeit des Schlüssels („Objektintegrität“, vgl. [Staud 2021, Abschnitt 5.9]) gibt es in FO-AP nur einen Eintrag, wenn es entsprechende Forderungen und Auftragspositionen gibt. |
|
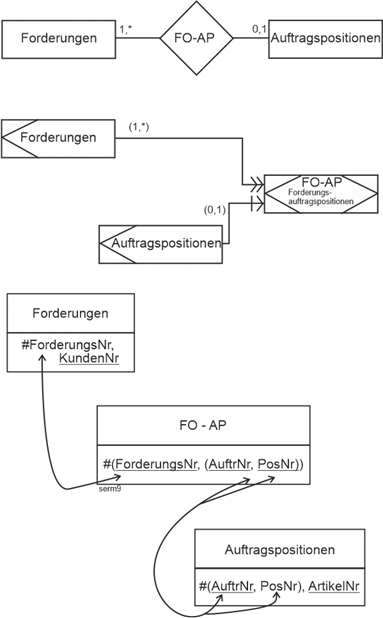
|
|
Abbildung 12.2-6: Vom ERM zum SERM – Fragment Forderungen / Auftragspositionen |
|
Fügt man damit die entstandenen Elemente zusammen, entsteht das SER-Modell der folgenden Abbildung. In dieser sind nun auch die oben erwähnten Spalten für die Abhängigkeitsgrade angegeben. Dazu unten mehr. |
|
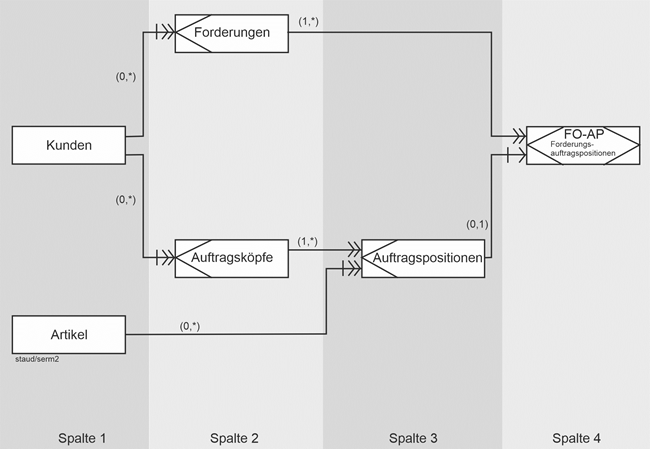
|
|
Abbildung 12.2-7:SER-Modell Kunden – Aufträge – Artikel |
|
Sinz verwendet für die gerichteten Beziehungen etwas andere Pfeile. Hier wurde die Pfeilnotation der SAP verwendet (vgl. den nächsten Abschnitt), was inhaltlich keine Bedeutung hat. |
|
Die Quelle für die obige Abbildung ist [Sinz 1990, S. 27]. Lediglich die Verbindungslinien wurden leicht verändert und nach der inzwischen gebräuchlicheren SAP-SERM-Notation gestaltet. Außerdem wurden die Spalten eingefügt. Mit ihnen werden unten die Abhängigkeitsgrade diskutiert. |
|
Verdeutlichung |
„1,1 – Verschmelzung“ |
Für die Min-/Max-Angaben 1,1 gilt also: Es wird jeweils ein Entity-Typ mit den Relationship-Typen zu einem Entity-Relationship-Typ (ER-Typ) zusammengefasst, die durch 1:1 - Beziehungen verbunden sind. Dem entspricht – bei der Übertragung in ein relationales Datenmodell – die Situation, dass dem Entity-Typ ein Fremdschlüssel hinzugefügt wird, der Schlüssel des anderen Entity-Typs. Er ist sozusagen Repräsentant des Relationship-Typs. Somit gilt hier, dass aus dem Beziehungstyp KD-AK zusammen mit dem Entitätstyp Auftragskopf der Entity-Relationship-Typ (ER-Typ) Auftragskopf wird (vgl. Abbildung unten). |
|

|
|
Abbildung 12.2-8: Von Entitätstyp und 1:1 - Beziehung zu ER-Typ |
|
Genau dasselbe geschieht mit dem Entitätstyp Forderung und dem Beziehungstyp KD-FO. |
|
|
|
Abbildung 12.2-9: Von Entitätstyp und 1:1 - Beziehung zu ER-Typ |
|
Im Falle des Entity-Typs Auftragsposition werden die beiden Beziehungstypen AK-AP und AR-AP hinzugenommen und in einen ER-Typ Auftragsposition verwandelt. |
|
|
|
Abbildung 12.2-10: Von Entitätstyp und 1:1 - Beziehung zu ER-Typ |
|
Zwei der Entitätstypen von Abbildung 12.2-2 erweisen sich als unabhängig von den anderen: Kunde und Artikel. Sie bleiben also Entitätstypen, bzw., in der Begrifflichkeit von Sinz Entity-Typen. |
|
Zwischen den damit erzeugten E-, ER- und R-Typen besteht nun eine Abhängigkeit im Sinne dieses Ansatzes. Diese Abhängigkeit hat eine Richtung und wird deshalb durch gerichtete Pfeile ausgedrückt. Folgende gerichteten(!) Beziehungen liegen in dem entstehenden SERM nun vor: |
Abhängigkeit mit Richtung |
- 0,* zwischen E-Typ Kunden und ER-Typ Forderungen
- 0,* zwischen E-Typ Kunde und ER-Typ Auftragsköpfe
- 0,* zwischen E-Typ Artikel und ER-Typ Auftragspositionen
- 1,* zwischen ER-Typ Forderungen und R-Typ FO-AP
- 1,* zwischen ER-Typ Auftragsköpfe und ER-Typ Auftragspositionen
- 0,1 zwischen ER-Typ Auftragspositionen und R-Typ FO-AP
|
|
Von den Startelementen (den jeweils links angeordneten) aus gesehen, geht es somit nur noch um die Frage, ob jede Entität an der Beziehung teilnehmen muss oder nicht (optional oder nicht). |
|
Von den Zielelementen aus gesehen geht es nur noch darum, ob maximal eine Entität oder mehrere an der Beziehung teilhaben. |
|
Nun die Abhängigkeiten: Völlig unabhängig sind Artikel und Kunde (Spalte 1). Diese beiden Entity-Typen benötigen keine anderen für ihre Existenz. Die durch sie repräsentierten Daten entstehen im Weltausschnitt bzw. Anwendungsbereich. Sie werden ganz links eingeordnet. |
Von links nach rechts immer abhängiger. |
Forderungen und Auftragsköpfe dagegen können nur existieren, falls es zugehörige Kunden gibt. Sie sind also von Kunden abhängig und werden deshalb in einer zweiten Spalte auf der rechten Seite angeordnet. |
|
Für Auftragspositionen gilt, dass sie nur existieren können, falls in Artikel und in Auftragsköpfe entsprechende Entitäten vorhanden sind. Dabei gilt: Einen Auftragskopf muss es geben, die Artikelangabe ist optional. Die Auftragspositionen sind deshalb in einer dritten Spalte. |
|
Forderungsauftragspositionen (FO-AP) wiederum benötigen Entitäten in Forderungen und in Auftragspositionen und landen deshalb in Spalte 4. |
|
Dieser Ansatz sorgt durch Berücksichtigung der Abhängigkeiten zwischen den Modellelementen und durch Visualisierung dieses Tatbestandes für mehr Übersicht im Datenmodell. Das Mittel, um dies zu erreichen ist letztendlich die Schlüssel-/Fremdschlüssel – Architektur der relationalen Theorie. |
|
Somit ist der SERM-Ansatz zwischen der standardmäßigen ER-Modellierung und der relationalen Modellierung angesiedelt. |
|
Zur Verdeutlichung hier das Relationale Modell zu den obigen beiden Modellen. Die Anordnung wurde ähnlich der im SER-Modell gewählt. |
|
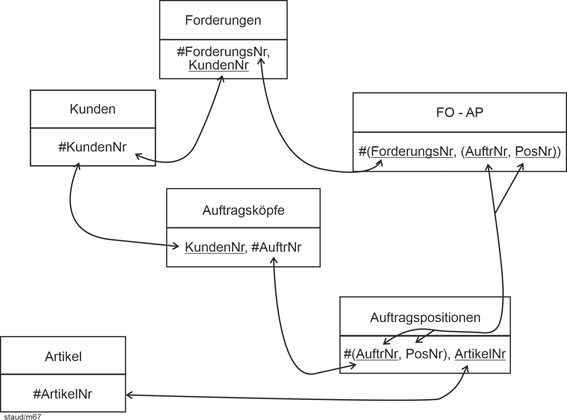
|
|
Abbildung 12.2-11: Relationales Datenmodell Kunden – Aufträge – Artikel |
|
Die Übertragung ist – ausgehend von den obigen zwei Modellen (ERM und SERM) nicht schwierig. Folgende Schlüssel wurden eingeführt, die übrigen eventuellen Attribute sind hierfür ohne Belang: |
Von ERM und SERM nach RM |
- KundenNr als Schlüssel von Kunden
- ArtikelNr als Schlüssel von Artikel
- AuftrNr als Schlüssel von Auftragsköpfe
- ForderungsNr als Schlüssel von Forderungen
- (AuftrNr, PosNr) als Schlüssel von Auftragspositionen
|
|
Mit den Min-/Max-Angaben zwischen Kunden und Auftragsköpfe muss der Kunde in jedem Auftragskopf vermerkt werden. KundenNr wird also Fremdschlüssel in Auftragsköpfe. Bei der Beziehung zwischen Artikel und Auftragspositionen führen die Min-/Max-Angaben dazu, dass die ArtikelNr Fremdschlüssel in Auftragspositionen wird. Genau gleich wird die Beziehung zwischen Forderungen und Kunden verarbeitet. |
|
Etwas weniger klar ist die Beziehung FO-AP zwischen Auftragspositionen und Forderungen. Die Min-/Max-Angaben drücken aus, dass es für jede Forderung mindestens eine Entität in FO-AP gibt. Eine Auftragsposition muss aber nicht zu einer Forderungsauftragsposition führen, falls ja, höchstens zu einer. Dies kann nur durch eine eigene Relation modelliert werden. Die Schlüssel- und Fremdschlüsselsituation ist dann wie folgt: |
|
- Der Gesamtschlüssel besteht aus #(ForderungsNr, (AuftrNr, PosNr)).
- ForderungsNr alleine ist auch Fremdschlüssel.
- Die Attributkombination (AuftrNr, PosNr) ist ebenfalls Fremdschlüssel.
|
|
Ein Fremdschlüssel, der aus zwei Attributen besteht, ist durchaus ungewöhnlich, hier aber unvermeidlich. |
|
So entstand das obige relationale Datenmodell. Der Vergleich mit dem SER-Modell macht deutlich, dass die definierte Existenzabhängigkeit mit dem Gewicht der Fremdschlüssel einhergeht: |
Fremdschlüssel und Abhängigkeit |
Gibt es keine Fremdschlüssel, ist der Entitätstyp unabhängig. Gibt es in Ergänzung des Schlüssels einen Fremdschlüssel, ist die erste Stufe der Existenzabhängigkeit gegeben. Liegt, wie hier in FO-AP, ein zusammengesetzter Schlüssel vor, der nur aus Fremdschlüsseln besteht, ist die höchste Form der Abhängigkeit erreicht. |
|
SERM sind in mehrfacher Hinsicht von großem Nutzen. |
Nutzen |
- Erstens verdeutlichen sie diesen Zweig der semantischen Modellierung, sie helfen beim Verständnis.
- Zweitens ist diese Methode präziser. Sie führt zu eindeutigeren Ergebnissen. Deshalb ist der Ansatz in der praktischen semantischen Modellierung von großem Nutzen.
- Drittens wird die Umsetzung des Modells in eine konkrete Datenbank erleichtert und weniger fehleranfällig.
|
|
|
|
|
|
13 SAP-SERM. Der SAP-Ansatz für die semantische Modellierung |
|
Quelle für diesen Abschnitt ist die aktuelle SAP Dokumentation (siehe Quellenangaben), abgerufen im Dezember 2021. Außerdem Modellfragmente, die in den 1990-er Jahren bei einer R/3-Version erhoben werden konnten. Da es nur um deren strukturelle Eigenschaften geht und nicht um die inhaltlichen, dürften sie ihre Relevanz auch behalten haben. |
|
Im Übrigen: Jahrzehntelange Beschäftigung mit Datenbanken und Datenmodellen lehrten mich, dass die Grundlagen, z.B. die jeweiligen Modellierungsansätze, sich nur wenig über die Zeit ändern. |
|
|
|
13.1 Das Grundkonzept |
|
Das informationelle Gerüst eines Unternehmens wird in Datenbanken erfasst. Dem Ansatz von ERP-Software entsprechend ist es hier (oft) eine einzige, das gesamte Unternehmen und all seine Aktivitäten beschreibende Datenbank [Anmerkung] . |
|
Eine zeitgemäße und zum Kontext dieses Textes passende Auffassung von Datenbanken ist daher die folgende: Datenbanken stellen die Informationen zur Verfügung, die für die Abwicklung der Geschäftsprozesse benötigt werden. |
|
Beim Datenbankdesign hat man ein Modell eines bestimmten Ausschnitts der Realität zu erstellen. Dieser Weltausschnitt (in diesem Kontext wird auch oft von Anwendungsbereich gesprochen) wird in die Datenbank hinein abgebildet. Im Fall der ERP-Software von SAP besteht der Weltausschnitt somit aus dem gesamten (vorgedachten) Unternehmen. |
Weltausschnitt |
Die hier anstehende Frage ist die des Datenbankdesigns. Hier hat sich in den letzten Jahrzehnten in Datenbanktheorie und (eher zögerlich) Datenbankpraxis die Auffassung durchgesetzt, dass es sinnvoll ist, im ersten Schritt ein Semantisches Datenmodell zu erstellen, so wie es in den obigen Kapiteln vorgestellt wurde, und anschließend eines, das näheren Bezug zum ausgewählten Datenbanksystem hat, z.B. ein relationales. |
Datenbankdesign |
Genauso geht auch die SAP vor, allerdings mit einer Besonderheit. |
|
Vgl. für eine umfassende Darstellung der relationalen Theorie [Staud 2021]: |
|
- Staud, Josef Ludwig: Relationale Datenbanken. Grundlagen, Modellierung, Speicherung, Alternativen. 2. Auflage 2021. Verlag tredition GmbH, Paperback: 978-3-347-35883-6 Hardcover: 978-3-347-35884-3 E-Book: 978-3-347-35885-0
|
Eine Alternative wäre die Übertragung des semantischen Modells in ein objektorientiertes. Vgl. hierzu und für eine umfassende Darstellung der objektorientierten Datenmodellierung [Staud 2019]: |
|
- Staud, Josef Ludwig: Unternehmensmodellierung – Objektorientierte Theorie und Praxis mit UML 2.5. (2. Auflage). Berlin u.a. 2019 (Springer Gabler)
|
Eine solche Übertragung erfolgte aber nach Kenntnis des Verfassers nicht. |
|
Im Kern erstellt die SAP Datenmodelle auf zwei Ebenen. Auf einer semantischen Ebene (die Methode wird SAP-SERM genannt) und auf der Ebene des Relationalen Datenmodells, im Data Dictionary. |
Einordnung:
ERM
SERM
SAP-SERM |
Ein Data Dictionary ist ein Verzeichnis aller Elemente einer Datenbank, sozusagen eine Metadatenbank. Zu diesen Elementen gehören, im Fall einer Relationalen Datenbank, die eingerichteten Relationen, die Attribute, die Sichten (views), die Semantischen Integritätsbedingungen (constraints) und alles andere, was das Datenmodell festlegt. |
|
Während der relationale Ansatz bei der SAP dem Standard entspricht, weist der semantische Modellierungsansatz Besonderheiten auf. SAP-SERM ist eine Variante des oben vorgestellten SERM-Ansatzes von Sinz. SERM wiederum entstammt den Modellierungsansätzen, die zu den Entity Relationship Modellen führten. Der Entity Relationship - Ansatz wiederum ist der erfolgreichste Vertreter der Gruppe der Semantischen Datenmodelle, die in den 70er und 80er Jahren intensiv diskutiert wurden. Die wichtigste Methode davon ist die nach Chen, die in den Kapiteln 1 – 11 vorgestellt wurde. |
|
Die folgende Abbildung verdeutlicht diesen Zusammenhang. Dabei bedeutet der erste Pfeil, dass ER-Modellierung ein Teilgebiet unter vielen der Semantischen Datenmodellierung war. Die beiden anderen Pfeile bedeuten jeweils eine Modifikation des darüber angegebenen Ansatzes. |
Semantische Datenmodellierung |
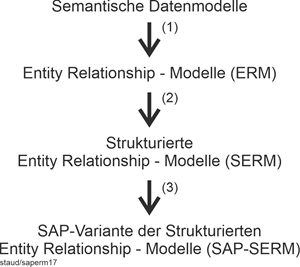
|
|
Abbildung 13.1-1: Varianten Semantischer Datenmodellierung |
|
13.2 Die Methode SAP-SERM |
|
Wie in der Datenbanktheorie üblich, unterscheiden auch die SAP-Modellierer eine logische und eine physische Ebene des Datenbankdesigns. Mit der logischen Ebene ist (hier) das Relationale Datenmodell gemeint, die physische meint die konkreten Dateistrukturen. |
Physische und
logische Ebene |
Die logische Ebene wird im SAP-Sprachgebrauch mit dem Data Dictionary gleichgesetzt. In der Sprache der SAP stellt sich der Zusammenhang wie folgt dar: |
|
„Im SAP-System wird die physische Organisation der Daten in der Datenbank überlagert durch eine logische Ebene, auf der alle Daten in einheitlicher Weise beschrieben werden. Diese logische Sicht der Daten wird im SAP Data Dictionary hergestellt und basiert auf dem relationalen Datenmodell.“ [SAP-BCDD, S. 2-1] |
|
Inzwischen wird das SAP Data Dictionary ABAP Dictionary genannt und leistet noch einiges mehr (vgl. SAP Dokumentation, Stichwort ABAP Dictionary (https://help.sap.com/erp2005_ehp_06/helpdata/de/cf/21ea0b446011d189700000e8322d00/frameset.htm), Stand 8.12.2021). |
|
Insgesamt ergeben sich damit drei Ebenen: die Semantische Ebene mit einem SAP-SERM, die logische Ebene mit einem Relationalen Datenmodell und die physische Ebene der konkreten Dateiorganisation. |
Drei Ebenen |
In diesem Kapitel wird im Folgenden die erste dieser Ebenen, die semantische, in ihrer SAP-spezifischen Ausprägung erläutert. |
|
|
|
Abbildung 13.2-1: Semantische, logische und physische Ebene des Datenbankdesigns |
|
Wie in allen Entity Relationship - Ansätzen werden auch hier für die Methode SAP-SERM im ersten Schritt Objekte und Beziehungen unterschieden. Oftmals werden dafür die englischen Begriffe entity und relationship verwendet, einige Autoren des deutschsprachigen Raumes verwenden für Objekte den Begriff Entität. |
Objekt,
entity,
Entität |
Der Objektbegriff wird hier im allgemeinsten Sinne verwendet: alles was für die Datenbank durch Informationen beschrieben wird. Da letzteres heute noch in der Regel [Anmerkung] Attribute sind, kann obige Definition damit so formuliert werden: |
|
Objekt im datenbanktechnischen Sinn sind alle Phänomene der Realwelt, die für die Datenbank durch Attribute beschrieben werden. |
|
Die zentralen Begriffe für diese SAP-Variante der Datenmodellierung sind damit Entität, Beziehung und Attribut. |
|
Attribute
Für die Zwecke dieses Abschnitts genügt folgende Definition: Ein Attribut besteht aus einer Bezeichnung und der Definition der möglichen Werte für das Attribut (Attributausprägungen). Ein einfaches Beispiel ist das Attribut Farbe mit den Ausprägungen weiß, schwarz, gelb, usw. Attribute werden irgendwelchen Informationsträgern (sie werden unten Objekte bzw. Entitäten genannt) zugeordnet. Attribute sind somit eine formale Fassung des umgangssprachlichen Eigenschafts- bzw. Merkmalsbegriffs. Vgl. für eine ausführliche allgemeine Darstellung dazu [Staud 2021, Kapitel 2] und für die ERM-spezifische hier oben Abschnitt 2.5. |
|
In der SAP-Dokumentation finden sich folgende Definitionen: |
|
„Eine Entität ist ein konkretes oder abstraktes Objekt (z. B. Herr Meyer, das Projekt ‘Vertriebsinformationssystem’), das sich eindeutig identifizieren lässt und für das Informationen gespeichert werden sollen. Entitäten werden nach ihren Eigenschaften in Entitätstypen eingeteilt. |
Entität |
Einem Entitätstyp sind Attribute zugeordnet, mit denen die Entitäten dieses Entitätstyps beschrieben werden. Die Eigenschaften von Entitäten werden durch konkrete Werte für die Attribute beschrieben. |
|
Ein Attribut besteht aus einer Bezeichnung und der Definition der möglichen Werte für das Attribut (z. B. das Attribut Farbe mit den Werten weiß, schwarz, gelb, usw.). Ein oder mehrere Attribute sind als Schlüsselattribute ausgezeichnet. Die Werte der Schlüsselattribute identifizieren eindeutig eine Entität innerhalb eines Entitätstyps.“ |
|
Quelle: SAP-Dokumentation, Stichwort Entitätstypen (https://help.sap.com/doc/saphelp_autoid70/7.0/de-DE/22/bd178e460a11d188fe0000e8323d3a/content.htm?no_cache=true), abgerufen am 8.12.2021. |
|
Auch die Beispiele, die in der Quelle angegeben werden, sind durchweg stimmig: |
|
Entitäten, Entitätstypen, Attribute |
|
| Begriff |
Beispiel |
| Entitäten |
Herr Meyer
Frau Müller
Frau Schmidt
Projekt ‘Vertriebsinformationssystem’
Projekt ‘Lagerverwaltung’ |
| Entitätstypen |
Mitarbeiter
Projekt |
| Attribute |
Attribute des Entitätstyps ‘Mitarbeiter’:
Personalnummer (Schlüsselattribut)
Name
Adresse
Eintrittsdatum Attribute des Entitätstyps ‘Projekt’:
Projektnummer (Schlüsselattribut)
Name
Beginn
Ende
Projektleiter |
| |
Quelle: ebenda |
|
Der Schritt von den Entitäten zu den Entitätstypen entspricht einer Klassenbildung, wie sie oben in Kapitel 3 beschrieben wurde. Dies beschreibt die folgende Definiton besser:
|
Entitätstypen |
„Ein Entitätstyp beschreibt eine Menge von Entitäten gleicher Eigenschaften (Attribute), besitzt einen Namen, hat Bedeutung“ [SAP-BC030, S. 3-9]. |
|
Beziehungen |
|
Wie im ER-Ansatz üblich werden hier – neben Entitäten – auch Beziehungen betrachtet. Allerdings – gemäß dem SERM-Ansatz – in einer gegenüber dem allgemeinen ER-Ansatz eingeschränkten Form. Geht es um die Beziehungen zwischen Entitätstypen, wird von Beziehungstyp gesprochen. Dabei wird, wie in der klassischen Entity Relationship - Theorie, die Klassenbildung der Entitäten für die Beziehungen nachvollzogen. |
|
Im Vergleich zur klassischen ER-Modellierung und entsprechend dem Ausgangspunkt SERM sind Beziehungen in diesem Ansatz wesentlich genauer gefasst und enger definiert. Sie bestehen ausschließlich zwischen jeweils zwei Entitätstypen, nicht zwischen drei oder mehr, wie es ansonsten auch möglich ist. Sie sind gerichtet und die Richtung drückt eine Hierarchie aus, was in der konventionellen ER-Modellierung nicht üblich ist. Demzufolge werden Beziehungen durch die beiden beteiligten Entitätstypen definiert. Den „vorgestellten“ nennt die SAP Start-Entitätstyp bzw. existenzunabhängigen oder referierten Entitätstyp, den nachfolgenden zweiten Ziel-Entitätstyp oder existenzabhängigen Entitätstyp. |
Enge Definition von Beziehungen |
In der Komponente der ERP-Software, mit der die Bearbeitung der Datenmodelle möglich ist, dem Data Modeler wird zwischen den eingehenden und ausgehenden Beziehungen eines Entitätstyps unterschieden: |
Eingehende und ausgehende Beziehungen |
- Eingehende Beziehung: der gewählte Entitätstyp ist in diesem Fall der Ziel-Entitätstyp (abhängige Entitätstyp) und der andere der Start-Entitätstyp (der unabhängige oder referierte Entitätstyp).
- Ausgehende Beziehung: der gewählte Entitätstyp ist in diesem Fall der Start-Entitätstyp (der unabhängige oder referierte Entitätstyp) und der andere der Ziel-Entitätstyp (abhängige Entitätstyp).
|
|
Beziehungen in SAP-SERM haben drei Eigenschaften: |
|
- Kardinalität
- Art
- und eine betriebswirtschaftliche Bedeutung.
|
|
Mit Kardinalität der Beziehung ist das gemeint, was auch ansonsten in den attributbasierten Ansätzen gemeint ist, allerdings gibt es im SAP-SERM keine n:m - Beziehungen. Konkret werden folgende Kardinalitäten unterschieden: |
Kardinalitäten – Übersicht |
- 1:M - Beziehungen in der üblichen Festlegung: Eine Entität des einen Entitätstyps steht mit mehreren des anderen in Beziehung.
- 1:CM - Beziehung: Eine Entität des einen Entitätstyps steht mit keinem einem oder mehreren des anderen in Beziehung.
- 1:1 - Beziehung in der üblichen Notation: Eine Entität des einen Entitätstyps steht mit einem des anderen in Beziehung.
- 1:C - Beziehung: Eine Entität des einen Entitätstyps steht mit keinem oder einem des anderen in Beziehung.
|
|
Folgende weitere Abkürzungen werden hier benutzt: Der Buchstabe "M", der üblicherweise nur "mehr als eins" bzw. "viele" bedeutet, soll hier auch noch Pflichtfeld (mandatory), der Buchstabe "C" Optionalität (conditional) und T Zeitabhängigkeit (temporary) signalisieren. |
Mandatory, Conditional, Temporary |
Die folgende Abbildung zeigt die grafische Darstellung der Beziehungen. Zwischen je zwei durch Rechtecke repräsentierten Entitätstypen (vgl. unten) wird jeweils einer dieser Pfeile eingefügt: |
|
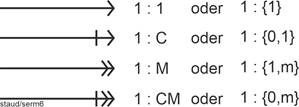
|
|
Abbildung 13.2-2: Beziehungsarten und ihre grafische Notation in SAP-SERM |
|
Entitätstypen werden in SAP-SERM wie üblich durch Rechtecke mit Beschriftung dargestellt. Die Attribute der Entitätstypen werden nicht angegeben, sie können aber bei Bedarf eingesehen werden. Beziehungstypen haben hier keine Attribute im modelltechnischen Sinn. Dies ist auch naheliegend, da sie ja den Beziehungstypen der SER –Modelle entsprechen. |
|
Die Art einer Beziehung bzw. eines Beziehungstyps kann hierarchisch, aggregierend, referentiell oder extern sein. |
Art einer Beziehung |
Hierarchischer Beziehungstyp |
|
Mit dem Begriff hierarchischer Beziehungstyp ist in SAP-SERM eine Beziehung zwischen zwei Entitätstypen gemeint, bei der der Ziel-Entitätstyp existenzabhängig ist vom Start-Entitätstyp. Konkret meint dies, dass die Existenz einer Entität des Ziel-Entitätstyps abhängt von einer Entität des Start-Entitätstyps. Das folgende Beispiel mit der Kardinalität 1:CM zeigt die grafische Darstellung. |
|

|
|
Abbildung 13.2-3: Grafische Darstellung von Beziehungstypen in SAP-SERM am Beispiel eines Hierarchischen Beziehungstyps. |
|
In der Sprache des SAP-SERM ist hier der Entitätstyp Fachbereiche der Start-Entitätstyp und Kurse der Ziel-Entitätstyp. |
|
Die SAP Dokumentation gibt folgende Definition: |
|
„Ein hierarchischer Beziehungstyp zwischen zwei Entitätstypen liegt vor, wenn gilt: |
|
- Der Ziel-Entitätstyp ist vom Start-Entitätstyp existenzabhängig, d.h. die Lebensdauer einer Ausprägung des Ziel-Entitätstyps ist kleiner oder gleich der Lebensdauer der Ausprägung des Start-Entitätstyps. |
|
- Der Ziel-Entitätstyp wird vom Start-Entitätstyp erzeugt, d.h. der Start-Entitätstyp hat direkten Einfluss auf die Merkmalsausprägung. |
|
. Der Ziel-Entitätstyp stellt eine semantische Verfeinerung dar, d.h. der Ziel-Entitätstyp ist eine Gliederung des Start-Entitätstyps, die den Start-Entitätstyp näher beschreibt. |
|
- Der Schlüssel des Start-Entitätstyps wird Teil des Schlüssels des Ziel-Entitätstyps. Die Beziehung zwischen zwei Entitäten darf nicht geändert werden.“ |
|
Quelle: SAP Dokumentation, Stichwort Beziehungen (https://help.sap.com/doc/saphelp_autoid70/7.0/de-DE/22/bd178e460a11d188fe0000e8323d3a/frameset.htm), abgerufen am 8.12.2021. |
|
Modellierungstechnisch äußert sich dies also so, dass der Schlüssel des Start-Entitätstyps zu einem Teil des Schlüssels des Ziel-Entitätstyps wird. |
|
Alle im Folgenden angeführten Beispiele wurden sprachlich leicht verändert (Mehrzahl bei Bezeichnungen von Entitätstypen, Länge der Attributsbezeichnungen). |
|
Als Beispiel bringt die SAP-Dokumentation die Beziehung veranstaltet mit dem Start-Entitätstyp Fachbereiche und dem Ziel-Entitätstyp Kurse. |
|
Der Start-Entitätstyp Fachbereiche besitzt (im Universitätsbeispiel der SAP-Dokumentation) die Attribute |
Attribute |
- Fachbereichsnummer (FachbNr; dieses dient auch als Schlüsselattribut) und Fachbereichsname.
|
|
Der Ziel-Entitätstyp Kurse besitzt die Attribute |
|
- FachbNr, Kursnummer (KursNr), KursLNr (Nummer des/der KursleiterIn), Kursname. FachbNr und KursNr dienen zusammen als Schlüssel dieses Entitätstyps.
|
|
Aufpassen: In der Dokumentation wird hier Schlüssel mit Schlüsselattribut verwechselt. FachbNr und KursNr sind Teil eines zusammengesetzten Schlüssels, also Schlüsselattribute. |
|
Die Existenzabhängigkeit wird dann in der relationalen Umsetzung durch den Fremdschlüssel FachbNr ausgedrückt (vgl. zu Fremdschlüsseln [Staud 2021, Kapitel 5.9]). Wegen der Nähe der SER-Modellierung und damit auch der SAP-SER-Modellierung zum relationalen Ansatz kann der Zusammenhang sehr anschaulich mit der relationalen textlichen Notation dargestellt werden: |
|
Fachbereiche (#FachbNr, Fachbereichsname) |
|
Kurse (#(FachbNr, KursNr), KursLNr, Kursname) |
|
Dieses Beispiel erlaubt auch, nochmals den Begriff der Existenzabhängigkeit zu betrachten, der in der SAP-Terminologie eine bedeutende Rolle spielt. Hier ist die Tatsache gemeint, dass jede Ziel-Entität zu ihrer Identifikation eine Start-Entität benötigt. Im obigen Beispiel: Jeder Kurs benötigt einen Fachbereich, was durch den zusammengesetzten Schlüssel festgelegt wird. |
Existenzabhängigkeit |
Die große Bedeutung ist berechtigt. Wird diese Existenzabhängigkeit modelltechnisch nicht ausreichend beachtet, gibt es datentechnische Defizite. Unverknüpfte evtl. redundante Daten „bevölkern“ die Datenbank. Die Datenbank verliert ihre Integrität. |
|
Aggregierender Beziehungtyp |
|
Die folgende Struktur wird Aggregierender Beziehungstyp genannt. Hier sind immer drei Entitätstypen im Spiel, zwei Start-Entitätstypen und ein Ziel-Entitätstyp. Wieder wird die Existenzabhängigkeit des Ziel-Entitätstyps vom Start-Entitätstyp als Definitionsmerkmal genannt. Hier besteht sie sogar bezüglich zweier Start-Entitätstypen. Der Ziel-Entitätstyp wird vom Start-Entitätstyp erzeugt, d.h. der Start-Entitätstyp hat direkten Einfluss auf die Merkmalsausprägung. In der SAP-Sprache: |
|
„Ein Entitätstyp geht aus der Begriffsverknüpfung von mindestens zwei Ausgangsentitäten hervor.“ [SAP-BC030, S. 3-14] |
|
Betrachten wir ergänzend die aktuelle Definition der SAP Dokumentation: |
|
„Ein aggregierender Beziehungstyp zwischen zwei Entitätstypen liegt vor, wenn gilt: |
|
- Der Ziel-Entitätstyp ist vom Start-Entitätstyp existenzabhängig, d.h. die Lebensdauer einer Ausprägung des Ziel-Entitätstyps ist kleiner oder gleich der Lebensdauer der Ausprägung des Start-Entitätstyps. |
|
- Der Ziel-Entitätstyp wird vom Start-Entitätstyp erzeugt, d.h. der Start-Entitätstyp hat direkten Einfluss auf die Merkmalsausprägung. |
|
- An der Bildung des Ziel-Entitätstyps ist mindestens ein zweiter Start-Entitätstyp beteiligt, der sich vom ersten Start-Entitätstyp unterscheidet. |
|
- Die Schlüssel der Start-Entitätstypen werden Teile des kanonischen Schlüssels des Ziel-Entitätstyps.“ |
|
Quelle: SAP Dokumentation, Stichwort Beziehungen (https://help.sap.com/doc/saphelp_autoid70/7.0/de-DE/22/bd178e460a11d188fe0000e8323d3a/frameset.htm), abgerufen am 8.12.2021 |
|
Im folgenden Beispiel kann somit ein Student mehrere Kurse besuchen und ein Kurs kann mehrere Studierende haben. Zusätzlich drücken die Pfeilspitzen aus, dass die Teilnahme an den Beziehungen konditional ist. |
Beispiel |
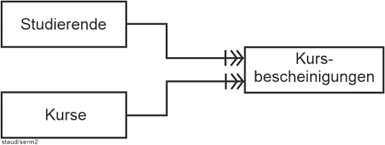
|
|
Abbildung 13.2-4: Grafische Darstellung aggregierender Beziehungstypen in SAP-SERM. |
|
In einer solchen Konstellation wird die eigentliche Beziehung, die zwischen Studenten und Kursen, durch den Schlüssel des Entitätstyps Kursbescheinigungen erfasst, der die Schlüssel von Studenten und Kurse enthält. |
|
Hier wieder die Angabe der Entitätstypen in relationaler Notation (die Punkte deuten die Liste weiterer Attribute an): |
|
Studierende (#StudNr, ...) |
|
Kurse (#KursNr, ...) |
|
Kursbescheinigung (#(StudNr, KursNr), …) |
|
Die Schlüssel der Start-Entitätstypen werden Teile des Schlüssels des Ziel-Entitätstyps. Der einzige Unterschied zwischen dem aggregierenden und dem hierarchischen Beziehungstyp ist, dass bei letzterem zwei Start-Entitätstypen vorliegen. |
|
Referentieller Beziehungstyp: |
|
Beim sogenannten Referentiellen Beziehungstyp geht es um die Situation, dass im Ziel-Entitätstyp auf den Start-Entitätstyp verwiesen wird, ohne dass die Existenz des Zielentitätstyps davon abhängt. Im folgenden Prozessfragment soll z.B. erfasst werden, dass Professoren Kurse halten. |
|

|
|
Abbildung 13.2-5: Referentielle Beziehungstypen – Beispiel Professoren / Kurse |
|
Betrachten wir die Definition der SAP-Dokumentation: |
|
„Ein referentieller Beziehungstyp liegt vor, wenn gilt: |
|
- Der Ziel-Entitätstyp ist vom Start-Entitätstyp existenzabhängig. |
|
- Der Start-Entitätstyp legt den Kontext des Ziel-Entitätstyps fest, d.h. eine Attributgruppe des Start-Entitätstyps ist im Ziel-Entitätstyp vorhanden, die den Ziel-Entitätstyp jedoch nicht erzeugt. |
|
- Die Schlüsselattribute des Start-Entitätstyps werden als Nicht-Schlüsselattribute in den Ziel-Entitätstyps übernommen. Eine Beziehung zwischen zwei Entitäten darf geändert werden. |
|
Beispiel |
|
- Zwischen den Entitätstypen Professoren (Start-Entitätstyp) und Kurse (Ziel-Entitätstyp) besteht die Beziehung ist Leiter von mit der Kardinalität 1:CN. |
|
- Der Start-Entitätstyp Professoren besitzt die Attribute Nummer (Schlüsselattribut), Name, Adresse und Besoldungsklasse. |
|
- Der Ziel-Entitätstyp Kurse besitzt die Attribute Fachbereichsnummer (Schlüsselattribut), Kursnummer (Schlüsselattribut), Nummer des/der KursleiterIn und Kursname.“ |
|
Quelle: SAP Dokumentation, Stichwort Beziehungen (https://help.sap.com/doc/saphelp_autoid70/7.0/de-DE/22/bd178e460a11d188fe0000e8323d3a/frameset.htm), abgerufen am 8.12.2021. |
|
Die Schlüsselattribute des Start-Entitätstyps werden also als Nicht-Schlüsselattribute in den Ziel-Entitätstyp übernommen. |
|
Zur Verdeutlichung die Umsetzung des Zitatbeispiels in die relationale Notation (mit angepassten Bezeichnungen). |
|
Professoren (#ProfNr, Name, Adresse, Besoldungsklasse) |
|
Kurse (#(FachbNr, KursNr), KursLNr, Kursname) |
|
Anmerkung: Kurse gab es bereits, siehe oben. Das „neue Thema“ betrifft nur die Kursleitung (ist Leiter von). Die Relation wird also ergänzt. |
|
Die Beziehung ist_Leiter_von drückt sich darin aus, dass das Attribut KursLNr (Kursleiter/in-Nummer) Fremdschlüssel ist. Die Realisierung der Beziehung im Beispiel bedeutet, dass jeder Kurs eine/n Kursleiter/in hat, dass aber die Professoren nicht unbedingt Kurse abhalten müssen. |
|
Die folgende Abbildung stellt den Zusammenhang „Beziehungstypen und Existenzabhängigkeit“ dar. |
|
|
|
| Klassifikation der
Beziehungstyparten |
|
starke
Existenzabhängigkeit |
schwache
Existenzabhängigkeit |
| erzeugend |
hierarchisch aggregierend |
konditionell-aggregierend |
| Kontext |
referentiell |
konditionell-referentiell temporär-referentiell |
| |
Quelle: SAP Dokumentation, Stichwort Beziehungen (https://help.sap.com/doc/saphelp_autoid70/7.0/de-DE/22/bd178e460a11d188fe0000e8323d3a/frameset.htm), abgerufen am 9.12.2021 |
|
Bei der Existenzabhängigkeit wird in der SAP-SER-Modellierung somit unterschieden zwischen starker und schwacher Existenzabhängigkeit. Bei der starken Existenzabhängigkeit wird gefordert, dass für jede Ausprägung des Ziel-Entitätstyps eine Zuordnung zu genau einer Ausprägung des Start-Entitätstyp vorhanden sein muss. Gilt diese Bedingung nur für eine (zeitabhängige) Teilmenge des Ziel-Entitätstyps, so spricht man von schwacher Existenzabhängigkeit [ebenda]. |
Starke und schwache Existenzabhängigkeit |
Mit dem nun eingeführten Begriff der Abhängigkeit zwischen den Entitätstypen bzw. Entitäten können die Kardinalitäten neu formuliert werden. Die n:m - Beziehungen ergeben sich damit wie folgt: |
Neuinterpretation |
- n = 1, also 1:m
Zu jeder abhängigen Entität gibt es genau eine unabhängige Entität.
- n = C, also C:m
Es kann Entitäten des abhängigen Entitätstyps geben, die keine Beziehung zu einer Entität des Start-Entitätstyps besitzen.
- m = 1, also n:1
Zu jeder Entität des Start-Entitätstyps gibt es genau eine abhängige Entität.
- m = C, also n:C
Zu jeder Entität des Start-Entitätstyps gibt es höchstens eine abhängige Entität.
- m = N, also n:N
Zu jeder Entität des Start-Entitätstyps gibt es mindestens eine abhängige Entität.
- m = CN, also m:CN
Zu jeder Entität des Start-Entitätstyps gibt es beliebig viele abhängige Entitäten.
|
|
Die Kardinalitäten C:1, C:C, C:CN und C:N sind vor allem bei referentiellen Beziehungen sinnvoll. Möglich sind sie auch bei aggregierenden Beziehungen, nicht aber bei hierarchischen, da hier verlangt ist, dass alle abhängigen Entitäten eine Entität des Start-Entitätstyps referieren müssen, d.h., dass es zu jedem Entitätstyp des abhängigen Entitätstyp eines im unabhängigen Entitätstyp gibt. |
|
Externe Beziehungen. Eine Beziehung wird in SAP-SERM extern genannt, wenn sie zwischen einem Entitätstyp innerhalb eines Datenmodells und einem Entitätstyp außerhalb dieses Datenmodells besteht. |
|
Generalisierung / Spezialisierung |
|
Alle attributbasierten Datenbankansätze tun sich schwer mit folgender (oben schon besprochener) Situation (in der Sprache des SAP-SERM-Ansatzes): Ein Entitätsyp ET1 hat bestimmte Attribute, sagen wir A1, ..., A5. Andere Entitätstypen haben dieselben Attribute aber zusätzlich noch einige mehr. ET2 z.B. A6 und A7 und ET3 die Attribute A8, A9, A10. Insgesamt also: |
Vgl. auch Abschnitt 5.1 |
ET1: A1, A2, A3, A4, A5 |
|
ET2: A1, A2, A3, A4, A5, A6, A7 |
|
ET3: A1, A2, A3, A4, A5, A8, A9, A10 |
|
Wie soll eine solche Situation modelliert werden? Sie drückt ja eigentlich Ähnlichkeit im Sinne des attributbasierten Ansatzes aus: Die Entitätstypen haben viele Attribute gemeinsam, einige wenige nicht. |
|
In den ER-Ansätzen wurde für diese Situation schon sehr früh das Konzept der Generalisierung / Spezialisierung entwickelt (vgl. Abschnitt 5.1). Es gibt einen „allgemeinen“ Entitätstyp, die Generalisierung, (im obigen Beispiel ET1) und die Spezialisierungen (im obigen Beispiel ET2 und ET3). ET1 ist dann die Generalisierung der beiden Spezialisierungen. Die semantische Datenmodellierung, zu der ja auch SAP-SERM gehört, drückt sich damit um die Frage der konkreten Speicherung solcherart erfasster Daten (ist ja auch nicht ihre Aufgabe) und verlagert diese in die logische Modellierung und physischepn Speicherung. |
|
Doch nun hierzu ein Beispiel aus dem Universitätsdatenmodell der SAP, der Anschaulichkeit wegen auch in relationaler Notation. Der allgemeine Entitätstyp seien alle Hochschulangehörige. Ihre Attribute seien eine MitarbNr, ihr Name und weitere. Eine der Spezialisierungen seien Studierende mit den Attributen StudNr, BetrProf (BetreuenderProfessor) und Studienbeginn. Eine andere Spezialisierung seien die Professoren mit folgenden Attributen: |
Universitätsdatenmodell |
#ProfNr, Name, Adresse, Besoldungsklasse. |
|
Ein zugegeben einfaches Modell, das aber ausreicht, dieses Konzept nochmals zu verdeutlichen. Insgesamt ergeben sich damit folgende Attribute (in relationaler Notation), wenn bei den Spezialisierungen die Attribute der Generalisierung weggelassen werden: |
|
Hochschulangehörige (#MitarbNr, Name, …) |
|
Studierende (#StudNr, BetrProf, Studienbeginn) |
|
Professoren (#ProfNr., Name, Adresse, Besoldungsklasse) |
|
Wegen der Generalisierung / Spezialisierung gilt: Die Menge der Ausprägungen von MitarbNr umfasst die Ausprägungen von StudNr und ProfNr und kann noch weitere Ausprägungen enthalten. |
|
Die grafische Notation in SAP-SERM zeigt die folgende Abbildung. Der Schlüssel der Generalisierung wird, wie auch im obigen Beispiel, in die Spezialisierungen übernommen. Dabei kann er umbenannt werden. |
|
Spezialisierungen können unterschiedlich strukturiert sein. Liegt eine Situation vor, in der sich die Spezialisierungen nicht überlappen, keine Entität also in mehr als einer Spezialisierung vorkommt, dann spricht man von einer disjunkten Spezialisierung. Die obige dürfte mit Sicherheit disjunkt sein, da eine Person üblicherweise entweder Studierender oder Professor/in ist. |
Eigenschaften einer Spezialisierung |
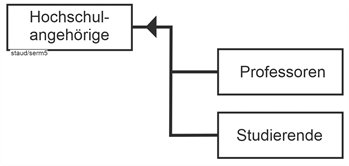
|
|
Abbildung 13.2-6: Generalisierung / Spezialisierung in der SAP-Notation |
|
Eine weitere Eigenschaft von Spezialisierungen betrifft die Frage, ob alle Entitäten der Generalisierung in die Spezialisierungen eingehen. Ist dies der Fall, bezeichnet man die Spezialisierung als vollständig. Obige Spezialisierung ist mit Sicherheit nicht vollständig, da es noch andere Personen außer Studierenden und Professoren an einer Universität gibt. |
|
Generalisierungen/Spezialisierungen müssen im Übrigen weder disjunkt noch vollständig sein. Diese beiden Eigenschaften von Spezialisierungen sind keine Besonderheit des SAP-SERM, sondern entstammen der allgemeinen ER-Modellierung (vgl. Abschnitt 5.1) |
|
13.3 Zusammenfassendes Modellierungsbeispiel |
|
Die folgende Abbildung zeigt ein Beispiel, das weitgehend dem Universitäts-Beispiel der SAP-Unterlagen entstammt und das die oben angeführten Modellfragmente enthält. Es wurde nach den Data Dictionary-Modellfragmenten in [SAP-BC030] und den Hinweisen in der aktuellen SAP Dokumentation erstellt. |
|
Die einzelnen Beziehungen wurden mit Nummern markiert. (1) und (2) stellen eine Generalisierung / Spezialisierung dar (wie oben schon gesehen). Sie bedeutet: Hochschulangehörige sind (hier) entweder Professoren oder Studierende. Konkrete Bedeutung: Hochschulangehörige haben bestimmte Attribute gemeinsam, die im gleichnamigen Entitätstyp erfasst werden. Professoren und Studierende haben jeweils noch spezifische Attribute, die bei ihrem Entitätstyp angeordnet sind. |
Vgl. Abbildung 13.3-2 für das entsprechende relationale Modell |
Bei der späteren Übertragung in relationale Strukturen (vgl. Abbildung 13.3-2) bedeutet ein Generalisierungs-/Spezialisierungsverhältnis, dass die Relationen durch 1:1 - Beziehungen verknüpft sind, so dass die Beziehung (1) konkret bedeutet: |
|
- Ein Universitätsangehöriger kann ein Professor sein, muss es aber nicht.
Auf Datenebene: Ein Tupel der Relation Mitarbeiter kann mit höchstens einem Tupel von Professoren verknüpft sein, muss es aber nicht.
|
|
Entsprechend bedeutet die Beziehung (2): |
|
- Ein Mitarbeiter kann ein Studierender sein, muss es aber nicht.
Auf Datenebene: Ein Tupel der Relation Mitarbeiter kann mit höchstens einem Tupel von Professoren verknüpft sein, muss es aber nicht.
|
|
Solche 1:1 - Beziehungen werden in Relationalen Datenmodellen dadurch gelöst, dass der Schlüssel der „übergeordneten“ Relation auch als Schlüssel in der „untergeordneten“ benutzt wird. In der Sprache der relationalen Theorie wird hier sozusagen der Fremdschlüssel zum Schlüssel, was ja üblicherweise nicht der Fall ist. Vgl. die ausführliche Darstellung hierzu in [Staud 2021, Kapitel 5]. |
|
Doch nun zurück zur semantischen Modellierung. Die Beziehung (3) zwischen Professoren und Studierende drückt in diesem Datenmodell ein Betreuungsverhältnis aus. Ein Professor kann keinen oder mehrere Studierende betreuen. Im relationalen Sinn handelt es sich dabei um eine 1:n - Beziehung, die durch einen Fremdschlüssel (hier ProfNr) in Studierende erfasst wird. In der SAP-Notation wird allerdings dieser Fremdschlüssel noch näher spezifiziert. Die Angabe OPT legt ihn als optionalen Fremdschlüssel fest, was hier bedeutet, dass der Fremdschlüssel in Studierende keinen Eintrag haben muss, z.B. wenn der jeweilige Studierende gerade nicht betreut wird. Hier müssen also bewusst semantisch bedingte Leereinträge in Kauf genommen werden. |
Betreuung |
In der korrekten relationalen Notation müsste dies durch eine eigene Relation Betreuungsverhältnis gelöst werden, die nur konkrete Betreuungsverhältnisse erfasst. Vgl. [Staud 2021, Kapitel 5]. |
|
Die Beziehung (4) drückt aus, dass ein Professor keinen, einen oder mehrere Kurse hält. Wieder handelt es sich um eine 1:n - Beziehung, die erfasst wird, indem in Kurse als Fremdschlüssel die ProfNr genommen wird. Aber auch hier spezifiziert dieser Ansatz etwas genauer: OBL macht den Fremdschlüssel zu einem obligatorischen, was hier bedeutet, dass bei jedem Kurs ein Professor eingetragen sein muss. |
Lehre |
Nach der relationalen Theorie wäre dieser Fremdschlüssel auf jeden Fall zu befüllen („referentielle Integrität“). |
|
Beziehung (5) legt fest, dass Professoren Publikationen (die in der Datenbank erfasst sind) haben oder auch nicht. Der Zusatz ID legt wiederum fest, dass es sich in Publikationen um einen identifizierenden Fremdschlüssel handelt. Diese Beziehung kann auch anders herum beschrieben werden: Eine Publikation kann dann in die Datenbank aufgenommen werden, falls sie von einem in ihr erfassten Professor stammt und dann muss dieser auch angegeben werden. |
Publikationen |
Die Beziehungen (6) und (7) zeigen, wie in diesem Ansatz n:m - Beziehungen (Verbindungsrelationen im relationalen Sinn, vgl. [Staud 2021, Kapitel 5]) erfasst werden. Die n:m - Beziehung besteht zwischen Kurse und Studierende: Ein Kurs kann mehrere Studierende haben, ein Studierender kann mehrere Kurse besuchen. |
n:m - Beziehungen |
Standardmäßig wird im Entity Relationship - Ansatz eine solche Beziehung als Beziehungstyp angelegt, kann mit Attributen versehen werden und taucht in der grafischen Notation als Raute auf. Im Relationalen Modell muss eine solche Beziehung mit drei Relationen gelöst werden, wovon eine die eigentliche Verknüpfung widerspiegelt (die Verbindungsrelation). |
|
Im SAP-SERM wird die gesamte Beziehung in zwei 1:n - Beziehungen aufgelöst. Kursteinahme stellt die eigentliche Verknüpfung dar. Dieser Entitätstyp muss die Schlüssel aus Kurse (KursNr) und Studierende (StudNr) enthalten. Diese beiden sind dort zusammen Schlüssel, vgl. das relationale Modell unten. Dieses Beispiel macht deutlich, dass SAP-SERM, genauso wie SERM, näher am Relationalen Ansatz ist als an der klassischen Entity Relationship - Modellierung. |
SAP-SERM: nahe an RM |
Doch zurück zum SAP-Sprachgebrauch: Beziehung (6) hält fest welcher Studierende an welchem Kurs teilnimmt, indem in Kursteilnahme der Schlüssel des Studierenden als Fremdschlüssel auftaucht. ID legt wiederum fest, dass dieser Fremdschlüssel eingetragen werden muss (identifizierender Fremdschlüssel). Entsprechendes gilt für Beziehung (7), nur dass hier verlangt wird, dass jeder Kurs tatsächlich auch in Kursteilnahme erscheint: Jeder Kurs muss in mindestens einem Tupel von Kursteilnahme erscheinen. Seine KursNr erscheint dort in der relationalen Umsetzung als Fremdschlüssel und Teil des Schlüssels. |
Kursbesuch |
Beziehung (8) beschreibt den Zusammenhang zwischen Fachbereiche und Kurse. Jeder Fachbereich muss bei mindestens einem Kurs auftreten und wird dort als identifizierender Fremdschlüssel erfasst. Es werden also z.B. Fachbereiche erst erfasst, wenn dort mindestens ein Kurs veranstaltet wird. |
Organisation |
Beziehung (9) hält fest, dass es zu Kursen auch Kursbeschreibungen gibt. Ein Kurs kann keine, eine oder mehrere Kursbeschreibungen haben. |
Beschreibung |
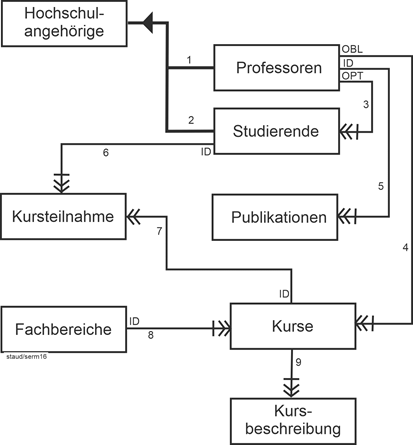
|
|
Abbildung 13.3-1: Datenmodell Universität – Ein Semantisches Datenmodell nach SAP-SERM.
Quelle: Erstellt nach den Data Dictionary Modellfragmenten in [SAP-BC030]. |
|
Auf die Darstellung der Abhängigkeiten durch Anordnung der Entitätstypen wurde hier verzichtet. |
|
Zum Vergleich nun dasselbe Datenmodell in der standardmäßigen relationalen Notation mit den oben angeführten Attributen. Zuerst die textliche Notation: |
|
Fachbereiche (#FachbNr, Fachbereichsname) |
|
Hochschulangehörige (#MitarbNr, Name, …) |
|
Kursbescheinigung (#(StudNr, KursNr), …) |
|
Kursbeschreibung (#KursbeschrNr, …) |
|
Kurse (#(FachbNr, KursNr), KursLNr, Kursname) |
|
Kursteilnahme (#(StudNr, KursNr), …) |
|
Professoren (#ProfNr, Name, Adresse, Besoldungsklasse) |
|
Publikationen (#PublikNr, …) |
|
Studierende (#StudNr, BetrProf, Studienbeginn) |
|
Damit ergibt sich das folgenden Abbildung graphische Datenmodell. Die Nummern an den relationalen Beziehungen entsprechen denen in der obigen Abbildung. |
|
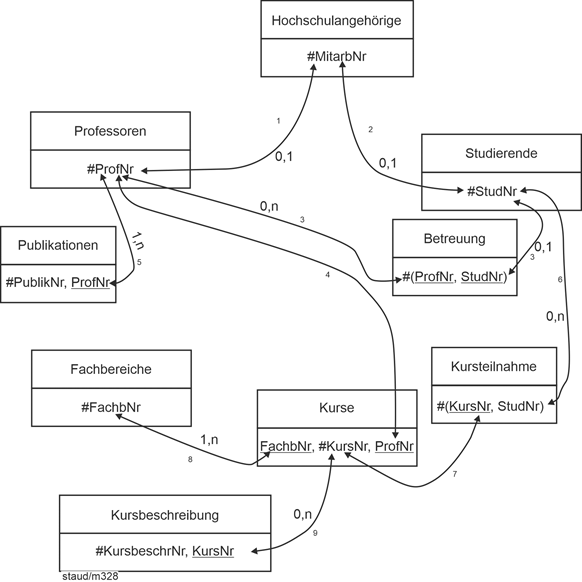
|
|
Abbildung 13.3-2: Datenmodell Universität in relationaler Notation. |
|
Es gilt: |
|
ProfNr ist Teilmenge von MitarbNr |
|
StudNr ist Teilmenge von MitarbNr |
|
Wie durch den direkten Vergleich zu erkennen ist, kann die Übertragung – nicht überraschend – sehr direkt vorgenommen werden. Je Entitätstyp entsteht eine Relation, die Beziehungstypen geben Hinweise auf die notwendigen relationalen Verknüpfungen. Die konkrete Realisierung hängt auch von den Angaben zu Pflicht- und optionalen Attributen ab (OPT, OBL, ID; vgl. oben). |
|
Zur Abrundung zeigt die folgende Abbildung nun noch das Datenmodell in der klassischen ER-Notation. Als Schlüssel wurden die des relationalen Datenmodells genommen. Die Ellipsen mit Punkten deuten die zusätzlichen deskriptiven Attribute an. |
|

|
|
Abbildung 13.3-3: Datenmodell Universität in Standard-ER-Notation. |
|
Soweit die Darstellung der SAP-Technik zur Semantischen Datenmodellierung (SAP-SERM), auch im Vergleich mit relationaler und ER-Modellierung. Im folgenden Abschnitt werden einige (sehr kleine) Ausschnitte aus konkreten SAP SERM - Datenmodellen angegeben. |
|
13.4 Beispiele mit Erläuterungen |
|
Die Kennzeichnung des Ansatzes mit dem Begriff strukturiert geht auf den SERM Ansatz von Sinz (vgl. Kapitel 12) zurück. Die Eigenschaft „strukturiert“ bedeutet, dass die Anordnung der Entitätstypen auf der Grafik durch ihren Abhängigkeitsgrad vorgegeben ist. Sind zwei Entitätstypen über eine Beziehung oder eine Spezialisierung miteinander verbunden, so steht der Start-Entitätstyp (der unabhängige) immer links vom Ziel-Entitätstyp (dem abhängigen). |
Aufbau der Grafiken |
Entsprechend der ER-Modellierung werden auch hier Entitätstypen durch Rechtecke dargestellt, in deren Mitte die Bezeichnung des Entitätstyps steht (vgl. die folgende Abbildung). Attribute werden in der Grafik nicht angegeben, sie können aber jederzeit durch Zugriff auf das Data Dictionary ausgegeben werden. Im Gegensatz dazu wird eine eventuelle Zeitabhängigkeit eines Entitätstyps durch ein Oval an der linken unteren Ecke des Entitätstyps direkt in der Grafik angegeben [SAP Hilfe 1]. Vgl. hierzu die Abbildungen 13.4-3 und 13.4-4. |
Entitätstypen |
Jeder Entitätstyp hat zusätzlich noch eine identifizierende Nummer. Diese steht im linken oberen Feld des Rechtecks. Rechts oben im Rechteck befinden sich zwei kleinere Felder, die nichts direkt mit der Modellierung zu tun haben. Links steht das Customizing-Kennzeichen, das rechte gibt Auskunft über die Art der Zuordnung zum Data Dictionary. |
|
Das Feld für das Customizing-Kennzeichen kann die folgenden Werte annehmen: |
Customizing |
Customizing-Kennzeichen |
|
| Feldinhalt |
Bedeutung |
| Blank |
Entitätstyp wird nicht im Customizing verwendet |
| C |
Entitätstyp wird nur im Customizing verwendet |
| A |
Entitätstyp wird allgemein verwendet |
| |
Quelle: SAP-Hilfe 1 |
|
Das Feld für die Art der Dictionary-Zuordnung kann die folgenden Werte annehmen:
|
|
Art der Dictionary-Zuordnung |
|
| Feldinhalt |
Bedeutung |
| Blank |
Keine Tabelle/kein View zugeordnet |
| T |
Tabelle zugeordnet |
| V |
View zugeordnet |
| |
Quelle: SAP-Hilfe 1 |
|
Die folgende Abbildung zeigt ein Beispiel, den Entitätstyp Einkaufskontrakt, nach dem auch das gesamte Datenmodell benannt ist, aus dem er stammt. Dieses ist weiter unten angegeben (vgl. Abbildung 13.4-2.3-2).
|
|

|
|
Abbildung 13.4-1: Darstellung eines Entitätstyps in SAP-SERM
Quelle: Entnommen dem Datenmodell Einkaufskontrakt aus SAP R/3, Vom Verfasser grafisch bearbeitet. |
|
Beziehungen werden in den Grafiken als Linien angegeben. Die Bezeichnung der Beziehung ist unter der Linie angeordnet, die Art der Beziehung über der Linie. Folgende Beziehungsarten können angegeben werden: |
Beziehungen |
Art der Beziehung |
|
| Buchstabe |
Art |
| H |
hierarchisch |
| A |
aggregierend |
| R |
referentiell |
| X |
extern |
| |
Quelle: [SAP Hilfe 1] |
|
Kardinalitäten werden, wie oben schon gesehen, durch die Gestaltung der Pfeilspitzen verdeutlicht. Unterschieden wird die rechte und die linke Seite der Kardinalität. Da es sich immer um Beziehungen vom Start-Entitätstyp zu einem Ziel-Entitätstyp handelt, genügt die Festlegung der rechten Seite. Folgende Symbole werden verwendet:
|
Kardinalitäten |
Pfeilsymbole |
|
| Symbol |
Kardinalität des abhängigen Entitätstyps |
| 1 Spitze |
1 |
| Senkrechter Strich plus 1 Spitze |
c |
| 2 Spitzen |
n |
| Senkrechter Strich plus 2 Spitzen |
cn |
| |
Quelle: [SAP Hilfe 1] |
|
Die Positionierung in der Abbildung gibt ebenfalls Hinweise auf die Art der Beziehung: „Hierarchische und aggregierende Beziehungen münden von links ein, referentielle Beziehungen von oben oder von unten“ [SAP Hilfe 1].
|
|
Für die grafische Darstellung einer Generalisierung / Spezialisierung gilt: Der generalisierte Entitätstyp wird immer links von den spezialisierten Entitätstypen angeordnet. Von der Generalisierung führt eine blaue Linie zu jeder der Spezialisierungen. Ein blaues Dreieck (im Original, hier wurde die Farbgebung beseitigt), sozusagen links von allen Spezialisierungen, signalisiert die Generalisierung / Spezialisierung. Vgl. hierzu die Beispiele in den Abbildungen unten. |
Generalisierung/ Spezialisierung |
Die Datenmodelle einer umfassenden ERP-Software müssen naturgemäß sehr groß sein. Deshalb werden, um auch bei Ausgabe mehrerer Datenmodelle den Überblick zu bewahren, die einzelnen Datenmodelle in farbig gekennzeichnete Rechtecke gepackt. Diese musste aus grafischen Gründen bei der Nachbearbeitung der SAP-SERM-Datenmodelle für diese Arbeit beseitigt werden. In diesen Rechtecken steht in der linken oberen Ecke die Kurzbeschreibung des Datenmodells (hier immer angegeben). |
|
Das erste Beispiel in der folgenden Abbildung zeigt ein sehr kleines Datenmodell zum Thema Einkaufskontrakt. |
|

|
|
Abbildung 13.4-2: Datenmodell Einkaufskontrakt
Quelle für alle Datenmodelle dieses Abschnitts: SAP R/3. Vom Verfasser 2005 erfasst und grafisch bearbeitet. |
|
Bedeutung der Abkürzungen an den Beziehungen: |
|
A: aggregierende Beziehung |
|
H: hierarchische Beziehung |
|
Es verdeutlicht die im Datenmodell vorgedachte Strukturierung (Aufteilung der Information) in Einkaufskontrakte, Einkaufskontraktpositionen und Abrufdokumentationen. Wie zu sehen ist, muss es Einkaufskontraktpositionen geben, was für die Abrufdokumentationen nicht gilt. Außerdem ist in diesem Fragment angedeutet, dass der Entitätstyp Einkaufskontraktposition eine Generalisierung anderer Entitätstypen ist. |
|
Die folgende Abbildung zeigt ein wiederum sehr einfaches Datenmodell zum Thema Qualifikation, bei dem der Zeitaspekt mitmodelliert wurde. |
|
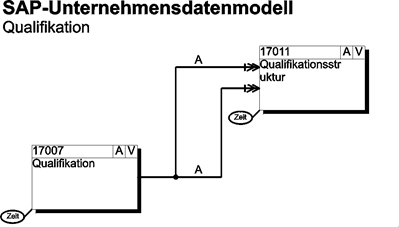
|
|
Abbildung 13.4-3: Datenmodell Qualifikation
Quelle für alle Datenmodelle dieses Abschnitts: SAP R/3. Vom Verfasser 2005 erfasst und grafisch bearbeitet. |
|
Bedeutung der Abkürzung an den Beziehungen: |
|
A: aggregierende Beziehung |
|
Ein etwas größeres Datenmodell zeigt die folgende Abbildung zum Weltausschnitt Bestellung. Hier sind auch Generalisierungen integriert. Zum einen zum Entitätstyp Bestellung selbst, der in Lieferantenbestellung und Umlagerungsbestellung spezialisiert wird. Zum anderen zum Entitätstyp Bestellpositionskondition(en), die in solche mit den Zusätzen „mit Stamm“ und „individuell“ differenziert werden. |
Customizing der Datenstrukturen |
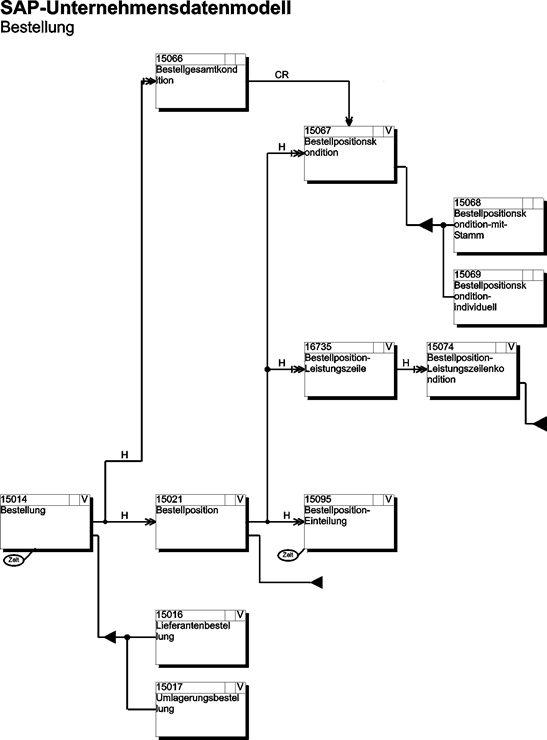
|
|
Abbildung 13.4-4: Datenmodell Bestellung
Quelle für alle Datenmodelle dieses Abschnitts: SAP R/3. Vom Verfasser 2005 erfasst und grafisch bearbeitet. |
|
Bedeutung der Abkürzungen an den Beziehungen: |
|
CR: konditionell-referentiell |
|
H: hierarchische Beziehung |
|
Neben den Beziehungen mit optionalem Charakter gibt es in diesen Datenmodellen durchaus auch welche, die vorliegen müssen. Wie der Abbildung entnommen werden kann, kann es zu einer Bestellung Gesamtkonditionen geben, während zu einer Bestellgesamtkondition einzelne Bestellpositionskonditionen vorhanden sein müssen. Außerdem muss es zu einer Bestellung Bestellpositionen geben (ist ja auch naheliegend) und zu letzteren Bestellpositions-Einteilungen. |
|
Vgl. für weitere Beispiele von SAP SERM – Modellen [Staud 2005, Abschnitt 6.3]. |
|
Soweit die kurze Betrachtung der SAP-spezifischen Semantischen Modellierung. Solche Semantischen Datenmodelle beschreiben in der Regel recht gut den jeweiligen Weltausschnitt. Sie müssen aber, geht es um die Realisierung konkreter Datenbanken, in Strukturen abgebildet werden, die näher an der physischen Datenorganisation [Anmerkung] in Dateien liegen. Im Datenbankbereich wird dies sehr häufig mit einer Abbildung des Semantischen Datenmodells in ein Relationales Datenmodell realisiert. Der Grund ist, dass Relationale Datenmodelle näher an der konkreten Dateiorganisation sind: Bei vielen Datenbanksystemen entspricht eine Relation einer Datei, zumindest aber sind Relationale Datenbanksysteme in der Lage, Relationen aufzunehmen und so zu verwalten, dass die Nutzer mit der konkreten physischen Datenstruktur nur noch wenig zu tun haben. |
Physische Ebene |
Deshalb kommen auch bei SAP an dieser Stelle in der Dokumentation die relationalen Datenbanken und ihre Terminologie mit ins Spiel. Die konkrete Datenbank, auf der die Datenbanksysteme der ERP-Systeme von SAP agieren, ist immer relational. Dies gilt natürlich unabhängig davon, welches Datenbanksystem gewählt wurde. Konkret geht es an dieser Stelle dann immer darum, Semantische Datenmodelle in relationale abzubilden, ganz allgemein (das wird hier betrachtet) und auch zugeschnitten auf die spezifischen Besonderheiten des jeweils gewählten Datenbanksystems (dies ist nicht Gegenstand dieses Textes). |
ERP mit Relationalen Datenbanken |
Wie oben schon angemerkt, sehen die SAP-Modellierer diese physische Datenbankebene in einem engen Zusammenhang mit dem Data Dictionary der Datenbank: |
Data Dictionary |
„Das Data Dictionary ist eine zentrale Informationsquelle über die Daten eines Unternehmens“ [SAP-BCDD, S. 1-1]. |
|
Die SAP bezeichnet ihr Data Dictionary darüber hinaus als ein integriertes, womit sie ausdrücken möchte, dass ihr Data Dictionary vollständig in die Entwicklungsumgebung eingebettet ist. Es ist weiterhin ein aktives, weil es automatisch erfasste oder geänderte Informationen bereitstellt für „aktuelle Laufzeitobjekte, Datenintegrität, Datenkonsistenz und Datensicherheit“ [SAP-BCDD, S. 1-3]. |
|
Vgl. für eine umfassende Darstellung der SAP-Sicht auf das Thema Data Dictionary den Text von Tanmaya Gupta: An Overview on Data Dictionary, abrufbar mit: |
|
https://archive.sap.com/kmuuid2/20472533-1846-2d10-77a0-c2ab8cdb78ed/An%20Overview%20on%20Data%20Dictionary.pdf. Zuletzt abgerufen im Dezember 2021. |
|
Als Funktionen des Data Dictionary werden angegeben [SAP-BCDD, S. 1-4]: |
|
- Verwaltung von Datendefinitionen (Metadefinitionen). Zentrale Beschreibung der im Informationssystem verwendeten Daten.
- Bereitstellung von Informationen für Auswertungen. Es liefert Informationen über die Beziehungen zwischen den Datenobjekten.
- Unterstützung der Softwareentwicklung
- Performance-Optimierung
|
|
Insgesamt liegt hier somit, was die Beschreibung und Erfassung der informationellen Struktur der Unternehmen angeht, die in der folgenden Abbildung skizzierte Situation vor. |
Vom Modell zu den Daten |
Zuerst entsteht das oben beschriebene Semantische Datenmodell. Dieses wird in relationale Strukturen abgebildet, was zu einem Meta-Datenmodell im Data Dictionary führt, das umfassend das gesamte informationelle Gerüst beschreibt. Dieses wird dann in einem konkreten Datenbanksystem in eine Datenbank umgesetzt. |
|
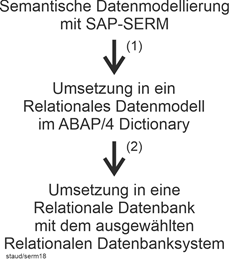
|
|
Abbildung 13.4-5: Vom Semantischen Datenmodell zur Relationalen Datenbank |
|
Gesamteinschätzung SAP SERM |
|
In diesem Abschnitt konnten die semantischen Modellierungstechniken der SAP nur skizziert werden. Trotzdem sollte deutlich geworden sein, dass es sich um sehr ausgefeilte Techniken handelt, die eine den hohen Anforderungen entsprechende semantische Modellierung erlauben. Man merkt diesen Ansätzen die wohltuende Wirkung der hohen praktischen Anforderung an. |
|
Dass diese Methode, aufbauend auf der Methode SERM von Sinz, sehr stark von der relationalen Theorie geprägt ist und eigentlich zwischen semantischer und relationaler Modellierung angesiedelt ist, kann man den Autoren nicht übelnehmen. Erstens weil das letztendlich zu realisierende logische Datenmodell ein relationales ist und zweitens, weil sie ein Ergebnis vorlegen mussten, das in der Praxis effizient eingesetzt werden kann. |
|
Auch nach den Erfahrungen des Verfassers ist ein SERM oder SAP SERM leichter in eine logische (hier: relationale) Datenbank umsetzbar, als ein ERM. Insbesondere die Möglichkeit der Anordnung nach Abhängigkeiten (von links nach rechts) und die damit erfolgte Klärung der Fremdschlüsselarchitektur ist sehr hilfreich. Sie erlaubt eine rasche Übernahme und die Vermeidung von Fehlern. |
|
Vgl. dazu den Unterpunkt Diskussion beim Wikipedia-Eintrag Structured-Entity-Relationship-Modell. |
|
|
|
|
|
14 Literatur |
|
C |
|
Chen 1976
Chen, Peter Pin-Shan: The Entity-Relationship Model – Toward a Unified View of Data. In: ACM Transactions on Database Systems, Vol. 1, No. 1, March 1976, S. 9-36 |
|
D |
|
Diestel 2017
Diestel, Reinhard: Graphentheorie (5. Auflage). Heidelberg 2017 |
|
S |
|
SAP Hilfe 1
SAP Dokumentation zum Data Modeler. Überschrift „Grafik: Darstellungsmethode (SAP-SERM)“ (https://help.sap.com/doc/saphelp_me61/6.1.5/de-DE/4e/00d1683198001de10000000a42189c/frameset.htm), Abruf am 1.12.2021. |
|
SAP Hilfe 2
SAP Dokumentation zum Data Modeler. Überschrift „Strukturierungskonzept: Datenmodell und Datenmodell-Hierarchie“ (https://help.sap.com/doc/saphelp_me61/6.1.5/de-DE/4e/00d1683198001de10000000a42189c/frameset.htm), Abruf am 6.12.2021. |
|
SAP-BC030
SAP Data Dictionary R/3 (R/3 System Release 2.1 Februar 1994). Schulungsunterlagen der Firma SAP. |
|
SAP-BCDD
BC – SAP Data Dictionary. (R/3-System Juli 1992). Schulungsunterlagen der Firma SAP. |
|
Sinz 1990
Sinz, Elmar J.: Das Entity-Relationship-Modell (ERM) und seine Erweiterungen, in: HMD 152 (1990), S. 17 – 29 |
|
Sinz 1992
Sinz, Elmar J.: Datenmodellierung im Strukturierten-Entity-Relationship-Modell (SERM), in: Bamberger Beiträge zur Wirtschaftsinformatik, Nr. 10, 1992 |
|
Staud 1991
Staud, Josef L.: Online Datenbanken. Aufbau, Struktur, Abfragen. Bonn u.a. 1991 (Addison-Wesley Publishing Company, 415 Seiten) |
|
Staud 1993
Staud, Josef L.: Fachinformation Online. Ein Überblick über Online-Datenbanken unter besonderer Berücksichtigung von Wirtschaftsinformationen. Berlin u.a. 1993 (Springer-Verlag, 550 Seiten) |
|
Staud 2005a
Staud, Josef: Datenmodellierung und Datenbankentwurf. Ein Vergleich aktueller Methoden. Berlin u.a. 2005 (Springer-Verlag) |
|
Staud 2010a
Staud, Josef: Unternehmensmodellierung – Objektorientierte Theorie und Praxis mit UML 2.0. Berlin u.a. 2010 (Springer-Verlag) |
|
Staud 2015
Staud, Josef: Relationale Datenbanken. Grundlagen, Modellierung, Speicherung, Alternativen. Vilshofen 2015. ISBN 978-3-9817175-1-8 |
|
Staud 2019
Staud, Josef: Unternehmensmodellierung – Objektorientierte Theorie und Praxis mit UML 2.5. (2. Auflage). Berlin u.a. 2019 (Springer Gabler) |
|
Staud 2021
Staud, Josef Ludwig: Relationale Datenbanken. Grundlagen, Modellierung, Speicherung, Alternativen. 2. Auflage 2021. Verlag tredition GmbH,
Paperback: 978-3-347-35883-6
Hardcover: 978-3-347-35884-3
E-Book: 978-3-347-35885-0 |
|
T |
|
Teorey 1990
Teorey, Toby J.: Database modeling and Design: The Entity-Relationship Approach, San Mateo 1990 |
|
|
|
|