Hier beginnt Teil IV: "Feintuning" und Vertiefung
mit den Kapiteln
14 Muster in Anwendungsbereichen und Modellen
15 Die Zeit in Datenmodellen und Datenbanken
In den obigen Kapiteln wurde der grundsätzliche Aufbau relationaler Datenmodelle vorgestellt. Bei der Erstellung von Datenmodellen für bestimmte Anwendungsbereiche muss dieses Instrumentarium eingesetzt werden. Dabei stößt man aber nicht nur auf einfache Strukturmerkmale, die sich problemslos in obiges abbilden lassen, sondern auch auf kompliziertere Strukturen , wie sie in realen Anwendungsbereichen eben vorliegen.
Diese erscheinen als Muster der Realwelt, die soweit wie möglich in Muster des relationalen Datenmodells abgebildet werden müssen. Semantik (der Realwelt/des Anwendungsbereichs) sucht Syntax (des relationalen Modells). Zum Beispiel folgende:
Semantik sucht Syntax
- Enthaltensein von Objekten ineinander (eine Festplatte ist in einem PC enthalten)
- Ähnlichkeit von Objekten (Objekte mit gemeinsamen Attributen: alle Angestellte, Entwickler, Haustechnikpersonal)
- Existenzabhängigkeit (die einen Objekte können ohne die anderen nicht existieren, z.B. (wenn eingebaut) Chip und Motherboard in einem PC, usw.
Da diese Muster für die Objekte und deren datenbanktechnische Verwaltung große Bedeutung besitzen, werden sie auch in den Datenmodellen ausgedrückt. Sie sind in der semantischen und objektorientierten Modellierung größtenteils schon länger bekannt, werden aber in der relationalen Theorie meist nur unzureichend thematisiert.
14.1 Ähnlichkeit - Generalisierung / Spezialisierung
Es gibt Objekte in Anwendungsbereichen, die sich in vielen Attributen gleichen, in einigen aber nicht. Betrachten wir die Angestellten eines Unternehmens. Gemeinsam könnten sie die Attribute
- Personalnummer (PersNr), Name, Vorname (VName), Abteilungsbezeichnung (AbtBez), Einstellungsdatum (EinstDat)
haben. Für die Entwickler wären noch die Attribute
- Entwicklungsumgebung (EntwU), Programmiersprache (ProgSpr) (jeweils nur eine, die meist genutzte)
denkbar. Für das leitende Management könnte noch das
- Entgeltmodell (Entgelt)
festgehalten werden.
Generalisierung / Spezialisierung (Gen/Spez)
Vgl. zur Herkunft der Begrifflichkeit [Staud 2019] bzw. die Literatur zur objektorientierten Theorie.
Wie bewältigt man ein solches Muster? Nimmt man alle Attribute zusammen in eine Relation, gibt es für Nicht-Entwickler und Nicht-Manager Attribute, die nicht belegt werden können ("semantisch bedingte Leereinträge", vgl. dazu das Dozentenbeispiel am Schluss des Abschnitts). Das ist eine höchst unzulängliche Struktur in (attributbasierten) Dateien und Datenbanken. In der semantischen Modellierung und in der objektorientierten Theorie wurde deshalb für dieses Muster die sog. Generalisierung / Spezialisierung (Gen/Spez) entwickelt. Diese kann in die relationale Theorie übernommen werden. Sie besteht hier darin, für alle gemeinsamen Attribute eine eigene Relation anzulegen, das wäre die sog. Generalisierung, und für die Attribute der jeweiligen spezialisierten Gruppen eine eigene, die Spezialisierungen. In unserem Beispiel entstehen damit folgende Relationen:
Angestellte (#PersNr, Name, VName, AbtBez, EinstDat)
Entwickler (#PersNr, EntwU, ProgSpr)
TopManagement (#PersNr, Entgelt)
Als Schlüssel wird jeweils PersNr genommen. Auf diese Weise erhält man Relationen, bei denen für jedes Objekt und jedes Attribut eine Attributsausprägung vorliegen kann, es braucht also keine semantisch bedingten Leereinträge geben.
Ein abstraktes Beispiel
Im folgenden Beispiel gehen wir von einer Standardsituation in Modellierungsprojekten aus: Mehrere Relationen liegen vor und plötzlich "entdeckt" man, dass sie gemeinsame Attribute haben. Betrachten wir die drei Relationen R1, R2 und R3 mit den angeführten Attributen:
Gemeinsame Attribute entdecken
R1 (#A1, A2, A3, A4, A5)
R2 (#A1, A2, A3, A6, A7, A8)
R3 (#A1, A2, A3, A6, A9, A10)
Offensichtlich haben die drei Relationen die Attribute A1, A2 und A3 gemeinsam, während ihre übrigen Attribute verschieden sind. In einem solchen Fall wird man die gemeinsamen Attribute in eine eigene Relation tun, die "oberste" Generalisierung. Sie soll R4 genannt werden.
R4 (#A1, A2, A3)
Das macht ein weiteres Motiv für die Gen/Spez deutlich: Ein bestimmtes Attribut soll nur einmal im Datenmodell und dann in der Datenbank auftauchen und nicht mehrfach. R4 stellt die Generalisierung der anderen drei Relationen dar. Diese behalten den Schlüssel, verlieren aber die übrigen gemeinsamen Attribute:
"Sparsame" Modellierung
R1 (#A1, A4, A5)
R2 (#A1, A6, A7, A8)
R3 (#A1, A6, A9, A10)
Diese drei Relationen stellen damit Spezialisierungen dar. Grafisch lässt sich dieses Datenmodell wie in der folgenden Abbildung ausdrücken. Die grafische Notation für dieses Muster hat kein eigenes grafisches Element, wie dies bei Entity Relationship - Modellen (ERM) und in Klassendiagrammen der objektorientierten Theorie der Fall ist. Man erkennt sie nur daran, dass die Relationen denselben Schlüssel haben und an den Min-/Max-Angaben zwischen diesen.
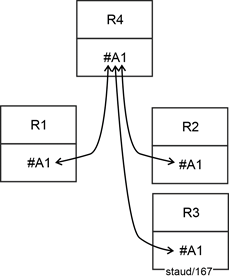
Abbildung 14.1-1: |
Generalisierung / Spezialisierung - Abstrakt |
Betrachtet man die textliche Fassung dieses Datenmodells genauer, bemerkt man, dass R2 und R3 ein weiteres Attribut gemeinsam haben, R6. Dies erfordert eine weitere Zerlegung. Das gemeinsame Attribut wird nach R5 ausgelagert. R5 ist dann Spezialisierung von R4 und Generalisierung von R2 und R3. Insgesamt gilt damit:
Gleichzeitig Generalisierung und Spezialisierung
Generalisierung aller Relationen, "oberste" Generalisierung:
R4 (#A1, A2, A3)
Spezialisierung von R4:
R1 (#A1, A4, A5)
Spezialisierung von R4, Generalisierung von R2 und R3:
R5 (#A1, A6)
Spezialisierungen von R5:
R2 (#A1, A7, A8)
R3 (#A1, A9, A10)
Vererbung “relational”
Obige textliche Darstellung zeigt die Aufteilung der Attribute auf die Relationen. Die folgende Abbildung klärt den Zusammenhang zwischen den Relationen. Die evtl. nötige Verknüpfung erfolgt über die Primärschlüssel. Benötigt nun eine Anwendung oder Auswertung, die auf R2 fokussiert auch die Attribute von R5 und R4 bzw. deren Ausprägungen, kann sie sich diese durch die relationele Verknüpfung von den dortigen Relationen holen. Vgl. dazu das Beispiel am Abschnittsende. Diese Technik nennt man in der objektorientierten Theorie Vererbung (die obere Relation "gibt" den "unteren" ihre Attribute im Bedarfsfall). Vgl. [Staud 2019, Abschnitt 6.6].
Attribute weiterreichen, per SQL
Die Primärschlüssel der Generalisierungen und Spezialisierungen stehen in folgendem Verhältnis zueinander: Die oberste Generalisierung enthält alle Schlüsselausprägungen. Jede ihrer Spezialisierungen enthält eine Teilmenge davon. Dies ist in der nächsten Abbildung auch durch die Wertigkeiten ausgedrückt. Die Kardinalität ist 1:1, die Min-/Max-Angaben sind 0,1 und 1,1 da nicht jedes Objekt der Generalisierung an einer bestimmten Spezialisierung teilnehmen muss, umgekehrt aber jedes Objekt der Spezialisierung verknüpft sein muss. Auch R5 als Generalisierung enthält alle Schlüsselausprägungen von R5, R3 und R2, die beiden letztgenannten aber nur Teilmengen von R5.
Mengen und Teilmengen
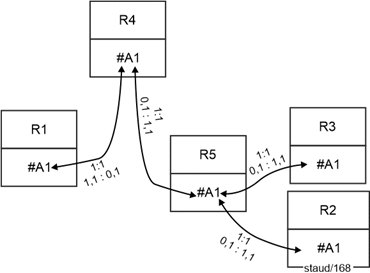
Abbildung 14.1-2: |
Generalisierung / Spezialisierung - Zweistufig und abstrakt |
Bleiben noch zwei Fragen:
- Überlappen sich die Spezialisierungen (ist ihre Teilmenge nicht leer) oder tun sie es nicht (Überlappung).
- Decken die Spezialisierungen alle Ausprägungen der Generalisierung ab, ist also die Vereinigungsmenge der Spezialisierungen gleich der Generalisierung, oder ist sie es nicht (Überdeckung).
Beides muss bedacht und (bei Abfragen, Auswertungen) berücksichtigt werden, schlägt sich aber im Datenmodell nicht nieder. Eine Detailbetrachtung hierzu findet sich für die objektorientierte Modellierung in [Staud 2019, Abschnitt 6.4].
Beispiel Dozenten
Das folgende Beispiel soll den Sachverhalt noch deutlicher machen und auf das Problem der semantisch bedingten Leereinträge hinweisen. Im Rahmen der Modellierung einer Hochschule habe sich für die Dozenten folgende Relation ergeben:
Dozenten (#DozNr, Name, VName, Raum, IntDozTel, IntDozSpr
ExtDozOrt, ExtDozStr, E-Mail, ExtDozTelOrg, ExtDozTelPriv, ExtDozOrg)
DozNr: Dozentennummer
VName: Vorname
IntDozTel: Telefonnummer des internen Dozenten
IntDozSpr: Sprechstunde des internen Dozenten
ExtDozOrt:: Wohnort des externen Dozenten)
ExtDozStr: Straße der Adresse des externen Dozenten
E-Mail: Mailadresse des internen oder externen Dozenten
ExtDozTelOrg: Telefonnummer des externen Dozenten an seinem Arbeitsplatz ("Organsiation")
ExtDozTelPriv: Private Telefonnummer des externen Dozenten.
ExtDozOrg: Organisation, in der der externe Dozent arbeitet.
Die Attribute mit "Int..." beziehen sich also auf die internen Dozenten, die mit "Ext..." auf die externen. In einer so gestalteten Relation wird es immer semantisch bedingte Leereinträge geben. Beschreibt ein Tupel einen internen Dozenten, können nur die Attribute Ausprägungen erhalten, die interne Dozenten beschreiben. Umgekehrt gilt dasselbe. Attribute für externe Dozenten erhalten nur Ausprägungen, wenn das betreffende Tupel auch externe Dozenten beschreibt. Lediglich die Attribute, die beide Dozententypen beschreiben, erhalten immer (für alle Tupel) Ausprägungen.
Semantisch bedingte Leereinträge
Die folgende Abbildung möchte dies veranschaulichen. Die Dozenten 1001 bis 1003 sind externe Dozenten, die übrigen interne. Ein "x" bedeutet, dass semantisch ordnungsgemäße Einträge an der jeweiligen Stelle möglich sind. Fragezeichen bedeuten, dass dies nicht möglich ist. Sind da Einträge, sind sie falsch, weil Attribute beschrieben werden, die es für die jeweilige Gruppe nicht gibt.

Abbildung 14.1-3: |
Generalisierung / Spezialisierungung - Semantisch bedingte Leereinträge |
Eine solche Struktur wird in der Datenmodellierung durch die oben eingeführte Generalisierung / Spezialisierung aufgelöst. Dazu wird die Relation zerlegt. Die Attribute für beide Dozententypen kommen in eine Relation (die Generalisierung), die für die externen und internen Dozenten jeweils in eine andere (Spezialisierungen):
Dozenten (#DozNr, Name, VName, Raum, E-Mail)
DozIntern (#DozNr, IntDozTel, IntDozSpr)
DozExtern (#DozNr, ExtDozOrt, ExtDozStr, E-Mail, ExtDozTelOrg, ExtDozTelPriv, ExtDozOrg)
Vgl. zu diesem Thema auch die Beispiele in den Kapiteln 16 und 17, insbesondere Sprachenverlag.
Damit entstehen drei Relationen, die keine der oben beschriebenen Lücken aufweisen. Im Bedarfsfall müssen aber, z.B. für Auswertungen, die Attribute der Generalisierung mit denen einer Spezialisierung zusammengebracht werden. Dies geschieht über den Schlüssel, der ja in der Generalisierung und in allen Spezialisierungen gleich ist.
Anwendungsbereich Fahrzeuge aller Art
Das folgende Beispiel zeigt eine Generalisierung / Spezialisierung mit zahlreichen Ebenen. Es soll um ein Unternehmen gehen, das Fahrzeuge aller Art vermietet. Folgende Attribute werden für die Fahrzeugtypen erfasst:
- Für alle Fahrzeuge: Tag der Anschaffung (TagAnsch), Preis, nötiger Führerschein zum Fahren des Fahrzeugs (Führerschein)
Zusätzlich für die einzelnen Untertypen:
- Für PKW: Motorart (Diesel, Benziner, Elektro, Hybrid, Wasserstoff, …), Motorstärke (PS). Hierunter fallen Limousinen, Cabriolets (Dach fest oder flexibel: Dachart), Sportwagen (Beschleunigung von 0 auf 100: Beschl) und Familienautos (Zahl der Sitzplätze)
- für LKW: Getriebeart (Getriebe)
- Für Busse: Zahl der Sitzplätze (Plätze)
- Für Kettenfahrzeuge: bewältigbare Steigung (Steigung)
- Für militärische Kettenfahrzeuge: mit oder ohne Bewaffnung (Waffejn). Hier wird außerdem festgehalten, ob es sich um Kampfpanzer (für diese wird Feuerkraft erfasst) oder um Brückenlegepanzer (für diese wird Brückenlänge erfasst) handelt.
- Für zivile Kettenfahrzeuge: Schiebekraft (wieviel Erde sie maximal wegschieben können)
Folgendes gehört nicht zum Muster Gen/Spez, dient nur zur Abrundung.
Die Ausleihe eines jeden Fahrzeugs wird mit Beginn (Tag der Ausleihe) und Ende (Tag der Rückgabe) festgehalten. Es versteht sich, dass ein Kunde öfters ein Fahrzeug ausleihen kann und dass ein Fahrzeug im Zeitverlauf möglichst oft ausgeliehen werden soll. Nach jeder Rückgabe des Fahrzeugs durch einen Kunden wird der Fahrzeugzustand festgehalten (ZustandF). Die Ausprägungen sind tadellos, normal, beschädigt, schwer beschädigt, funktionsunfähig. Ziel ist hier, die Historie der Zustandsentwicklung festzuhalten. Von den Ausleihern werden die Adressangaben (nur eine Adresse) erhoben (Name, Vorname, PLZ, Ort, Straße, Telefon). Sie erhalten außerdem einen Status, der folgende Ausprägungen haben kann: Neukunde (0), langjähriger solider Kunde (1), nicht solider Kunde (2).
Die folgende Tabelle ordnet die Attribute den Fahrzeugtypen zu.
Attribute zu Fahrzeugtypen
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fahrzeuge |
x |
x |
x |
x |
x |
|
|
|
|
|
|
|
|
|
|
|
|
| PKW |
x |
x |
x |
x |
x |
x |
x |
|
|
|
|
|
|
|
|
|
|
| LKW |
x |
x |
x |
x |
x |
|
|
x |
|
|
|
|
|
|
|
|
|
| Busse |
x |
x |
x |
x |
x |
|
|
|
x |
|
|
|
|
|
|
|
|
| Kettenfahrzeuge |
x |
x |
x |
x |
x |
|
|
|
|
x |
|
|
|
|
|
|
|
| Familienautos |
x |
x |
x |
x |
x |
x |
x |
|
|
|
x |
|
|
|
|
|
|
| Sportwagen |
x |
x |
x |
x |
x |
x |
x |
|
|
|
|
x |
|
|
|
|
|
| Cabriolets |
x |
x |
x |
x |
x |
x |
x |
|
|
|
|
|
x |
|
|
|
|
| Kettenfahrzeuge Zivil |
x |
x |
x |
x |
x |
|
|
|
|
x |
|
|
|
x |
|
|
|
| Kettenfahrzeuge Militärisch |
x |
x |
x |
x |
x |
|
|
|
|
x |
|
|
|
|
x |
|
|
| Kampfpanzer |
x |
x |
x |
x |
x |
|
|
|
|
x |
|
|
|
|
x |
x |
|
| Brückenlegepanzer |
x |
x |
x |
x |
x |
|
|
|
|
x |
|
|
|
|
x |
|
x |
Anmerkung: Ein x bedeutet, dass das Attribut für den jeweiligen Fahrzeugtyp Bedeutung hat.
Attribute der Spaltenüberschriften:
1 Nr
2 FZTyp (Typ des Fahrzeugs)
3 TagAnsch (Tag der Anschaffung)
4 Preis (Preis des Fahrzeugs)
5 Führerschein (Benötiger Führerschein)
6 PS (Motorleistung, heute in kW gemessen)
7 Motarart (Art des Motors)
8 Getriebe (Art des Getriebes)
9 Plätze (Anzahl der Sitzplätze)
10 Steigung (Höchste bewältigbare Steigung)
12 Beschl (Beschleunigungsvermögen des Fahrzeugs, von 0 auf 100)
13 Dachart (Art des Daches)
14 Schiebekraft (Größte durch das Fahrzeug verschiebbare Menge an Erde)
15 WaffeJN (Waffenausstattung ja/nein)
16 Feuerkraft (Feuerkraft des Geschützes)
17 Brückenlänge (Länge der ausklappbaren Brücke)
Lösung 1 (textlich)
Als oberste Generalisierung ergibt sich die Relation Fahrzeuge mit den für alle Fahrzeugen gültigen Attributen:
Fahrzeuge (#Nr, FZTyp, TagAnsch, Preis, Führerschein)
FZTyp (Fahrzeugtyp): Ein solches Attribut, das die Zugehörigkeit zu einer Spezialisierung zeigt, ist zwar optional, aber sinnvoll. Es erleichtert die SQL-Abfragen entlang der Gen/Spez-Hierarchie.
Die folgenden vier Relationen sind Spezialisierungen von Fahrzeuge mit jeweils zusätzlichen Attributen.
PKW (#Nr, PS, Motarart)
LKW (#Nr, Getriebe)
Busse (#Nr, Plätze)
Kettenfahrzeuge (#Nr, Steigung)
PKW und Kettenfahrzeuge sind gleichzeitig auch Generalisierungen für weitere Relationen. PKW für die folgenden:
Familienautos (#Nr, Sitzplätze)
Sportwagen (#Nr, Beschl)
Cabriolets (#Nr, Dachart)
Kettenfahrzeuge für:
KettenfahrzeugeZivil (#Nr, Schiebekraft)
KettenfahrzeugeMilitärisch (#Nr, WaffeJN)
Die Relation KettenfahrzeugeMilitärisch hat die Spezialisierungen:
Kampfpanzer (#Nr, Feuerkraft)
Brückenlegepanzer (#Nr, Brückenlänge)
Nicht zur Generalisierung / Spezialisierung gehören die Relationen Ausleiher und Ausleihe:
Ausleiher (#Nr, Name, Vorname, PLZ, Ort, Straße, Telefon, Status)
Ausleihe (#(KNr, FahrzNr, Beginn), Ende, ZustandF)
Erinnerung: Ein Schlüssel einer Spezialisierung enthält eine Teilmenge der Schlüsselausprägungen des Schlüssels der Generalisierung.
Die folgende Abbildung zeigt die grafische Lösung. Hier wird die gestufte Gen/Spez-Hierarchie besonders deutlich. Für eventuelle Auswertungen werden die Tupel der Relationen über den Schlüssel zusammengebracht. Mittels SQL können natürlich beliebige Relationen verknüpft werden (vgl. Kapitel 19), allerdings wird die Menge der gemeinsamen Tupel nur dann nicht leer sein, wenn die Abfrage entlang einer bestimmten Generalisierung / Spezialisierung liegt.
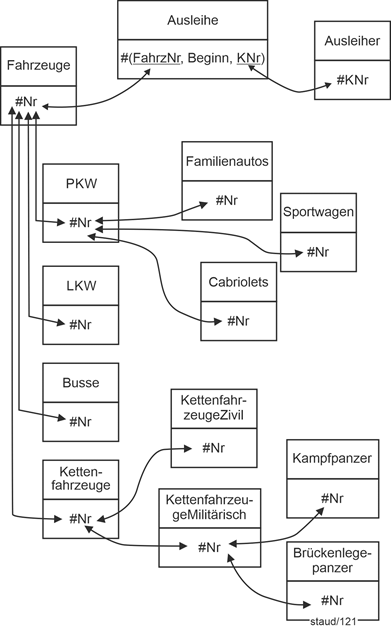
Abbildung 14.1-4: |
Muster Gen/Spez - mehrstufig am Beispiel Fahrzeuge |
Zusammengefasst
Die Generalisierung / Spezialisierung klärt die sinnvolle Speicherung von Relationen, die zwar viele Attribute gemeinsam haben, einige aber nicht. Zusammen mit dem Schlüssel werden alle gemeinsamen Attribute in einer Relation erfasst (Generalisierung). Die Spezialisierungen kommen mit ihren spezifischen Attributen und dem Schlüssel ebenfalls in jeweils eine Relation.
14.2 Einzel- und Typinformation
In Kapitel 3 und insbesondere in Abschnitt 3.4 wurde gezeigt, wie einzelne Objekte zu Objektklassen zusammengefasst werden. In einer Klasse sind dann Objekte, die genau dieselben Attribute besitzen. Diese werden dann in der Datenbank verwaltet. Jedes Attribut beschreibt somit alle einzelnen Objekte der Klasse, jedem Objekt kann eine Attributsausprägung zugewiesen werden. Nun gibt es aber Situationen in Anwendungsbereichen, wo der Klasse als Ganzes ebenfalls Attribute und Attributsauswertungen zugewiesen werden müssen. Insgesamt liegen dann Attribute für die Einzelobjekte und für die Objektklasse vor.
Attribute für die Einzelobjekte und die Klasse
In der objektorientierten Theorie wird dieses Muster durch die sog. Klassenattribute erfasst. Vgl. [Staud 2019, Abschnitt 2.3].
Dieses Muster – es wird hier Einzel/Typ-Muster genannt – ist in den Anwendungsbereichen ständig präsent und muss dementsprechend auch in den Datenmodellen der Anwendungsbereiche umgesetzt werden. Leider wird es oft übersehen, was zu Redundanz in den Datenbeständen führt. Seine Grundlage ist also, dass es Objekte (aller Art) gibt, die sich sehr ähneln und die demzufolge gleiche Attribute haben (Tiere einer Gattung, technische Geräte eines Typs, Menschen einer Gruppe,...), bei denen aber auch gleichzeitig die Gattungen / Gerätetypen / Menschengruppen Attribute aufweisen.
Je nach Anwendungsbereich und Objekttyp wird die Gesamtheit aller Objekte auf abstrakte Weise unterschiedlich benannt: Ganz allgemein und zurückgreifend auf die objektorientierte Theorie Klassen (Objektklassen). Falls es sich um Tiere handelt Gattungen, bei Geräten Typen (Gerätetypen), bei Menschen Gruppen, usw.
Will man bei solchen Objekten die Informationen der einzelnen Objekte mit denen der Klasse ergänzen und fügt man diese einfach der Relation mit den Einzelinformationen hinzu, ist dies redundant. Einige Beispiele:
- In einem Zoo werden evtl. die einzelnen Tiere (Schimpanse Eddi, Orang Utan Franz, Elefant Paul, ...) durch Attribute erfasst, zum anderen auch die Gattungen (Schimpansen, Orang Utans, Elefant der Gattung, ...). Natürlich nur für Großtiere, die als Individuen in Erscheinung treten.
- In der Technik wird in bestimmten Situationen das einzelne Stück erfasst (einzelne Kraftfahrzeuge, Festplatten, Flugzeugersatzteile, ...), zum anderen auch die gleichartigen Gruppen (Kraftfahrzeuge, Festplatten, Flugzeugersatzteile eines Typs, ...).
- Bei Menschen wird oftmals der einzelne Mensch erfasst (mit Personalnummern, Namen, usw.) und auch die Gruppe, zu der er gehört (Mitarbeiter IT, Leiharbeiter, Leitendes Management, ...).
Liegt eine solche Situation vor, gibt es drei Möglichkeiten:
- In der Datenbank und damit im Datenmodell werden nur Attribute zu den einzelnen Objekten erfasst. Dann gibt es eine Relation zu diesen und alles ist in Ordnung. Das entspricht der Standardsituation.
- Es werden nur Attribute zur Klasse (Typ, Gattung, Gruppe) erfasst. Dann gibt es eine Relation zu diesen und die Sache ist ebenfalls geklärt. Lediglich bei einer eventuellen relationalen Verknüpfung mit einer anderen Relation muss aufgepasst werden. Vgl. dazu die Beispiele unten.
- Zu beidem, zu den einzelnen Objekten und zur Klasse sind Attribute zu erfassen. Dann müssen zwei Relationen angelegt werden (eine für die einzelnen Objekte, eine für die Klasse) und die Attribute müssen auf diese aufgeteilt werden. Attribute, die einzelne Objekte beschreiben, kommen in die Relation mit den Einzelinformationen. Beschreiben sie die Klasse als Ganzes, kommen sie in eine Relation mit den Typinformationen. Vgl. dazu die folgenden Beispiele.
Es gibt also in der Datenbank u.U. einzelne Objekte, zum anderen aber auch die Zusammenfassung gleichartiger Objekte. Die Zusammenfassung wird hier einheitlich für alle im jeweiligen Bereich üblichen Bezeichnungen (Typ, Gattung, Gruppe, usw.) Typ genannt. Das Muster soll dann Einzel/Typ-Muster genannt werden.
Muster Einzel/Typ
Beispiel: Zootiere - einzeln und als Gattung
Die folgende Abbildung zeigt das Muster in einem Anwendungsbereich, in dem es um Tiere geht, z.B. in einem Zoo. Die Tiergattungen des Zoos könnten aus Schimpansen, Orang Utans, Elefanten usw. bestehen. Für sie wird die Relation TiereGattung mit den Attributen Bezeichnung (Bez), Anzahl der Mitglieder (Anzahl), einer Angabe zur Klassifikation (Klassif) und Hinweisen zur Art der Unterbringung (ArtUnt) erfasst. Für die einzelnen Tiere in der Relation TiereEinzeln gibt es eine Tiernummer (TNr), einen Namen (Name), den Geburtstag (GebTag), das Geschlecht und die Nummer des Gebäudes, in dem sie untergebracht sind (GebNr). Zur Verbindung der beiden Relationen wird die Gattungsbezeichnung in TiereEinzeln aufgenommen. Diese beiden Relationen beschreiben den Sachverhalt absolut redundanzfrei.
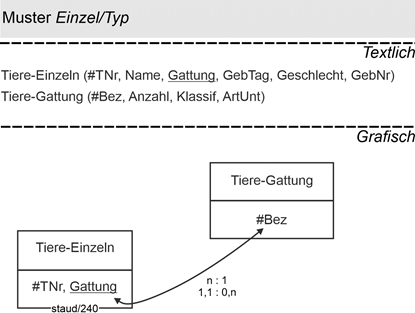
Abbildung 14.2-1: |
Muster Einzel/Typ zu Zootieren |
Muster Einzel/Typ bei technischen Teilen
Im folgenden Beispiel soll es um hochwertige technische Teile gehen, z.B. Ersatzteile für Flugzeuge, für Kraftwerke, usw. Auf jeden Fall um Teile, die auch einzeln identifiziert werden und nicht nur als Typen, wie es in diesen Anwendungsbereichen ja meist der Fall ist.
Für die einzelnen Teile (Relation Teile-Einzeln) wird eine Teilenummer (TeilNr), das Datum der Beschaffung (DatBesch), der Lieferantenname (LiefName; es gibt also unterschiedliche Lieferanten für die einzelnen Teile eines Typs) erfasst. Für die Teiletypen die Typbezeichnung (TeilBez), die Anzahl der für den Typ vorhandenen einzelnen Teile (Anzahl) und der minimale Lagerbestand, der für den Typ vorgehalten wird (MinLag).
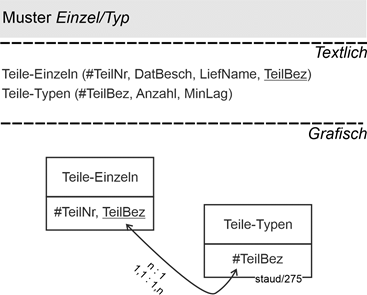
Abbildung 14.2-2: |
Muster Einzel/Typ am Beispiel Teile |
Muster Einzel/Typ bei Festplatten (mit Einbindung ins Datenmodell)
Das folgende Beispiel ist auch aus dem technischen Bereich (Festplatten). Es zeigt zusätzlich, wie diese "Muster-Information" mit dem übrigen Datenmodell verknüpft wird.
Die einzelnen Festplatten (Relation FP-Einzeln) werden durch eine Seriennummer (SerNr), das Datum des Einbaus der Festplatte (DatEinbFP) und das Ergebnis der letzten Fehlerprüfung (FehlPrüf) beschrieben. Die Festplattentypen (FP-Typen) durch die Bezeichnung (PlBez), die Speicherkapazität (Größe) und die Zugriffsgeschwindigkeit (Zugriff). Die Verknüpfung der beiden Relationen geschieht wieder durch die Übernahme des Schlüssels der Typ-Relation als Fremdschlüssel in die Einzeln-Relation. Hier als PlBez nach FP-Einzeln.
Die Verknüpfung mit dem Rest des Datenmodells – hier zur Relation PC – erfolgt in der Regel über die Relation mit den einzelnen Objekten, hier FP-Einzeln. Hier soll die Semantik so sein, dass ein PC mehrere Festplatten haben kann und eine bestimmte Platte in genau einen PC eingebaut ist. Dann ergibt sich die relationale Verknüpfung so, wie es die folgende Abbildung im unteren Teil zeigt: InvPC wird Fremdschlüssel in FP-Einzeln.
Verknüpfung
Der untere Teil der Abbildung zeigt die Min-/Max-Angaben 0,n auf der Seite von FP-Typen. Dies bedeutet, dass wir einen neuen Festplattentyp gefunden haben (sehr viel Speicherplatz, besonders schneller Zugriff,…), den wir erfassen, aber noch nicht einbauen.
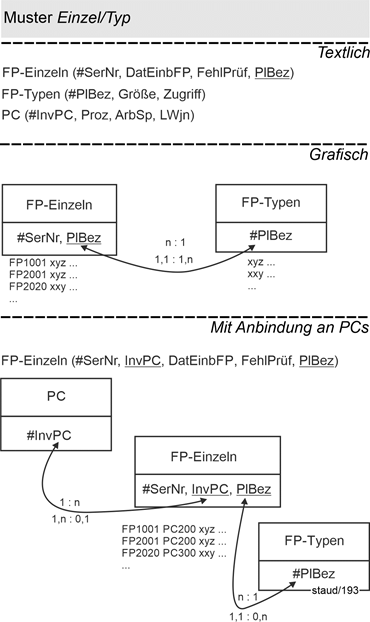
Abbildung 14.2-3: |
Muster Einzel/Typ mit Verknüpfung ins Datenmodell |
Verknüpfung mit Typinformation
Das folgende Beispiel zeigt eine Verknüpfung mit Typinformationen. Die PCs seien über die Relation
Ungenaue relationale Verknüpfung
PC (#InvPC, Proz, ArbSp, LWjn)
erfasst.
Optische Laufwerke sind - erkennbar am Schlüssel - per Typbezeichnung erfasst. Dies bedeutet, hinter einer Bezeichnung können viele Einzelgeräte stehen. Ist dann die Semantik so, dass ein PC mehrere optische Laufwerke haben kann (ein bestimmter Laufwerkstyp kann ja sowieso in vielen PC sein) ergibt sich folgende Lösung:
OptLwPC (#(LWBez, InvPC))
Dies hält fest, wieviele Laufwerkstypen in einem PC enthalten sind. Will man auch die Anzahl der einzelnen Geräte erfassen, muss eine Ergänzung vorgenommen werden:
OptLwPC (#(LWBez, InvPC), Anzahl)
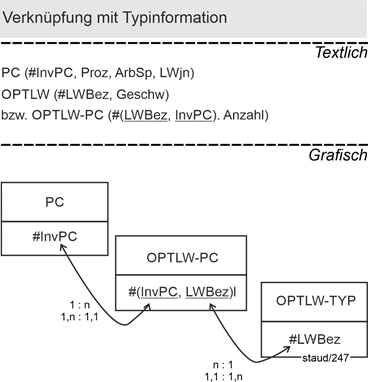
Abbildung 14.2-4: |
Verknüpfung mit Typinformation am Beispiel Optische Laufwerke |
InvPC: Inventarnumme des PC (eindeutig)
Proz: Prozessorbezeichnung
ArbSp: Größe des Arbeitsspeichers
LWjn: Laufwerk vorhanden? (Ja/Nein)
LWBez: Laufwerkbezeichnung
Geschw: Geschwindigkeit des Laufwerks.
Anzahl: Anzahl der Laufwerke im PC
14.3 Enthaltensein - Aggregation
Hier geht es um das Muster, das in der semantischen Datenmodellierung und in der objektorientierten Theorie Aggregation genannt wird. Es drückt aus, dass ein Objekt in einem anderen enthalten ist. Es drückt nicht Existenzabhängigkeit aus, das ist Aufgabe der Komposition, die im nächsten Abschnitt beschrieben wird.
Typisch für dieses Muster ist, dass die enthaltenen Teile eine eigene Existenz besitzen. Das kann auf zweierlei Weise modelliert werden. Entweder betrachtet man die Komponenten auf Typ-Ebene oder als individualisierte Komponenten. Die folgenden Beispiele rund um die Welt der PCs mögen dies verdeutlichen.
Anwendungsbereich PC – Aggregation mit individualisierten Komponenten
Hier soll es um Komponenten gehen, mit denen ein PC ausgestattet werden kann und die mit ihm fest, aber nicht untrennbar (vgl. dazu das Muster Komposition im nächsten Abschnitt) verbunden sind. Also z.B. Grafikkarten, interne Festplatten. Die Komponenten sind individualisiert, d.h. sie haben jeweils einen Schlüssel.
Komponenten auf Typebene
Die folgende Abbildung zeigt das (kleine) Datenmodell. Es gibt eine Relation PC und eine PCKomp für die Komponenten. InvNr bedeutet jeweils Inventarnummer. Sind PC und Komponenten die Ausgangsrelationen, muss die Aggregation durch eine eigene Relation PCKomp ausgedrückt werden:
PCKomp (#InvNrKomp, InvNrPC)
Damit kann die Komponente in Komponenten auch „existieren“, falls sie nicht mehr in einen PC eingebaut ist.
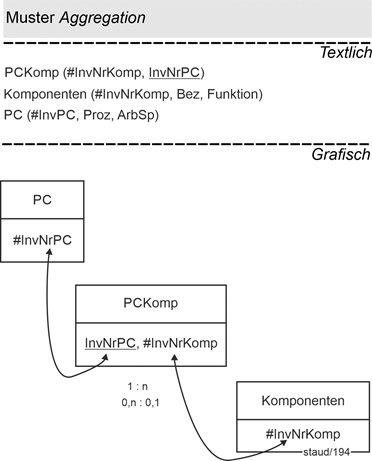
Abbildung 14.3-1: |
Muster Komposition mit individualisierten Komponenten |
Anwendungsbereich PC - Komponenten auf Typebene
Auch hier soll es wieder um die Ausstattung jedes einzelnen PCs mit Komponenten gehen, die Komponenten sollen aber nur über ihre Bezeichung ("Grafikkarte xyz"), also auf Typebene, erfasst werden. Damit verändert sich die Relation zu den Komponenten:
Komponenten-Typen (#BezKomp, Funktion) //BezKomp : Bezeichnung Komponente
Dann ergibt sich die unten angegebene Lösung. Die Agregation wird durch die Relation PCKomp wie folgt ausgedrückt:
PCKomp (#(InvNrPC, BezKomp))
Ein PC kann also mehrere Komponenten zugeordnet bekommen, eine Komponente („Festplatte IBM 123“) kann mehreren PCs zugeordnet werden. Diese Modellierung auf Typebene ist allerdings ungenau, da die konkrete Anzahl von Komponenten des gleichen Typs so nicht erkannbar ist. Sollte auch dies ausgedrückt werden, müßte die Anzahl (z.B. der „Typ-gleichen“ Festplatten ) noch angegeben werden:
PCKomp (#(InvNrPC, BezKomp), Anzahl)
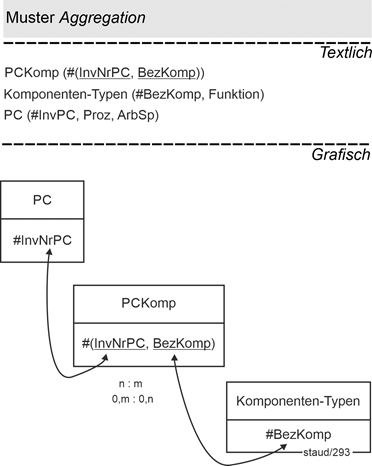
Abbildung 14.3-2: |
Muster Aggregation mit Komponenten auf Typebene |
Anwendungsbereich Teile / rekursiv
Eine oftmals vorkommende Aggregation ist die rekursive Beziehung von (technischen) Teilen, die andere Teile enthalten, und dies auf mehreren Ebenen. Zur Veranschaulichung stelle man sich ein Gerät vor, z.B. ein Fahrrad oder ein Flugzeug. Das ganze Gerät besteht aus Grobkomponenten, jede dieser aus Subkomponenten, usw., bis man bei elementaren Komponenten angekommen ist. Eine solche Zusammenstellung von Komponenten mit den in ihnen enthaltenen Subkomponenten ist Grundlage von Stücklisten.
Enthaltensein
Die folgende Abbildung zeigt ein Beispiel. Die Relation für das Enthaltensein wird TeileEnth genannt. Sie stellt Teile in Beziehung: Teile mit „A“ (TeilNrA) enthalten Teile mit „B“ (TeilNrB), Anzahl gibt an, wieviele. Das Ganze ist mehrstufig, auch in den Beispielsdaten.
Relation Teile-Enth
| TeilNrA |
TeilNrB |
Anzahl |
|---|---|---|
| K1001 |
K1005 |
1 |
| K1001 |
K1006 |
1 |
| K1002 |
K1006 |
1 |
| K1002 |
K1007 |
2 |
| K1003 |
K1008 |
2 |
| K1005 |
K1009 |
1 |
| K1005 |
K1010 |
1 |
| ... |
|
|
Die Semantik („TeilNrB ist in TeilNrA enthalten“) muss im Anwendungsprogramm hinterlegt sein. Die folgende Abbildung zeigt diese Relation und ihre Anbindung an eine i.d.R. notwendige Relation, mit der die Teile beschrieben werden (Teile).
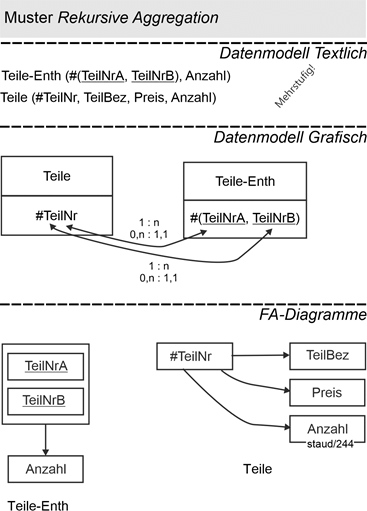
Abbildung 14.3-3: |
Muster Aggregation am Beispiel einer rekursiven Beziehung |
Wie man sehen kann, drückt das Datenmodell nicht sehr viel von der Semantik der mehrstufigen rekursiven Beziehung aus, so dass tatsächlich der Hauptanteil der Semantik durch das Anwendungsprogramm umgesetzt werden muss.
14.4 Enthaltensein und Existenzabhängigkeit - Komposition
Bei diesem Muster geht es auch um Enthaltensein, wie bei der Aggregation, allerdings sind die enthaltenen Teile untrennbar mit dem übergeordneten Teil verbunden. Zumindest datenbanktechnisch aber manchmal auch ganz real im Anwendungsbereich sind die enthaltenen Teile existenzabhängig vom "Ganzen": Wird ein"Ganzes" gelöscht, verschwinden auch die Komponenten. Am leichtesten kann man sich dies an den Anwendungsbereichen Rechnungsstellung und Gebäude vorstellen:
- Wird der Rechnungskopf gelöscht, verschwinden auch die Rechnungspositionen
- Wird das Gebäude aus der Datenbank genommen, z.B. weil es verkauft wurde, müssen auch die zugehörigen Büros herausgenommen werden (falls sie datenbanktechnisch erfasst waren).
Typisch für alle Varianten ist, dass der Schlüssel der übergeordneten Relation als Schlüsselattribut und Fremdschlüssel in die untergeordnete eingefügt wird.
Anwendungsbereich Rechnungsstellung
Das klassische Beispiel für dieses Muster ist die Beziehung zwischen Rechnungsköpfen (ReKöpfe) und Rechnungspositionen (RePos) der jeweiligen Rechnung. Sie gehören untrennbar zusammen und die Rechnungspositionen verschwinden auch, wenn die Rechnung aus der Datenbank gelöscht wird.
Modelliert werden kann dies wie im folgenden Beispiel gezeigt. RePos erhält einen zusammengesetzten Schlüssel, bestehend aus Rechnungsnummer (ReNr) und Positionsnummer (PosNr). ReNr ist gleichzeitig auch Fremdschlüssel.
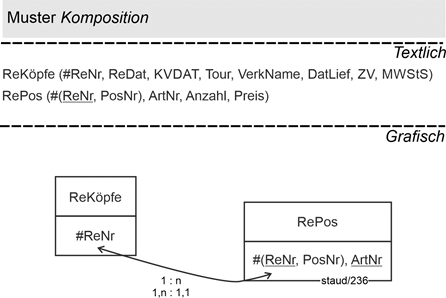
Abbildung 14.4-1: |
Muster Komposition im Anwendungsbereich Rechnungsstellung |
Anwendungsbereich PC
Hier soll es um Komponenten gehen, die mit dem PC fest verbunden sind und mit ihm (normalerweise) zu existieren aufhören. Z.B. die WLAN-Komponente, das Kartenlesegerät, usw. Diese sind datenbanktechnisch existent, haben also eine eigene Beschreibung, ausgedrückt durch Attribute. Die Modellierung erfolgt so, dass der Schlüssel der übergeordneten Relation PC zum Fremdschlüssel in der untergeordneten Relation Komponenten wird. Da ein Tupel ohne Fremdschlüsseleintrag nicht existieren kann, verschwinden die Einträge in Komponenten, wenn der entsprechende PC ausgemustert wird.
Vgl. das Modellbeispiel in Abschnitt 16.3
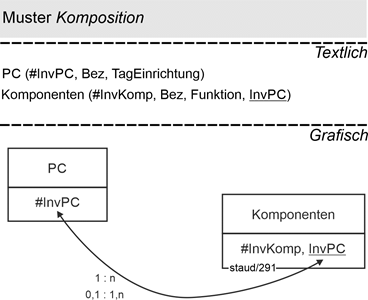
Abbildung 14.4-2: |
Muster Komposition im Anwendungsbereich PC |
Ich weiß, dass die "Bastler" diese Komposition leicht zu einer Aggregation machen, indem sie z.B. eine solche Komponente eben doch ausbauen und woanders verwenden, hier soll aber mal - z.B. im Rahmen einer PC-Massenfertigung - von der Komposition ausgegangen werden.
Anwendungsbereich Zoo
Im folgenden Beispiel wird angenommen, dass es zu jedem (größeren) Tier des Zoos eine Tierakte gibt, die bei seiner Geburt entsteht und beim Tod vernichtet wird. Sie besteht aus einzelnen Einträgen, die durch eine Aktennotiznummer (AktNotizNr) identifiziert werden.
Das zugehörige Gesamtmodell Zoo wird in Abschnitt 17.6 vorgestell.
Dies kann durch das folgende Beispiel ausgedrückt werden. Neben der Relation zu den einzelnen Tieren gibt es auch eine zu den Tierakten mit dem angegebenen Schlüssel. Die Struktur des Schlüssels sichert die Existenzabhängigkeit. Gibt es eine bestimmte Tiernummer nicht mehr, müssen auch die entsprechenden Akteneinträge verschwinden.
Semantik sucht Syntax
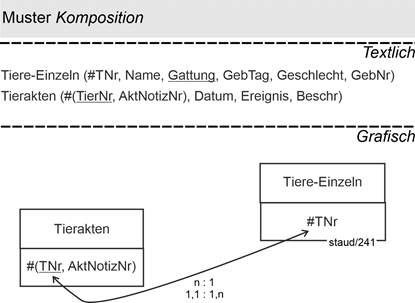
Abbildung 14.4-3: |
Muster Komposition im Anwendungsbereich Zoo |
Anwendungsbereich Sportverein
Das folgende Modellfragment stammt aus dem Beispiel Sportverein, vgl. Abschnitt 16.2. Es geht um Begegnungen von Mannschaften des Vereins mit anderen (fremden) Mannschaften. Dies könnte, wie unten gezeigt, modelliert werden. Da die zeitlichen Aspekte schon recht identifizierend wirken (eine Mannschaft kann zu einem Zeitpunkt nur gegen einen Gegner spielen) genügt es, die Mannschaftsnummer um den Tag und den Beginn der Begegnung zu ergänzen. Gegner und Ergebnis können außerhalb des Schlüssels platziert werden.
Zusätzliche Zeitaspekte
Auch bei dieser Konstruktion ist gesichert, dass die Begegnungen existenzabhängig sind von den Mannschaften. Würde zum Beispiel eine Mannschaft aufgelöst, müssten auch deren Begegnungen gelöscht werden.
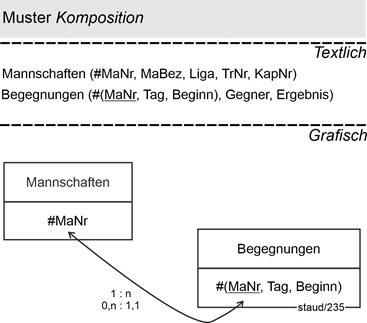
Abbildung 14.4-4: |
Muster Komposition im Anwendungsbereich Sportverein |
Anwendungsbereich Fachliteratur
In Abschnitt 16.4 wird eine Datenbank zu Fachliteratur vorgestellt. Erfasst werden alle Typen von Fachliteratur, auch Sammelbände und die einzelnen Beiträge in den Sammelbänden. Dabei gilt: Ein Sammelbandbeitrag (SBB) gehört zu genau einem Sammelband (SB). Existenzabhängigkeit ist auch gegeben. Wenn ein Sammelband aus der Datenbank genommen wird, muss auch jeder SBB gelöscht werden. Die folgende Abbildung zeigt dies und zusätzlich die Einbettung in das Modell:
Vgl. Abschnitt 16.1
- Sammelbände (SB) sind eine Spezialisierung von Mono+SB (vgl. die Verknüpfung an Position 2), der Relation mit den gemeinsamen Attributen von Monographien (Mono) und Sammelbänden, vgl. Abschnitt 16.4.
- Sammelbandbeiträge (SBB) eine von ZSA-SBB, der Relation mit den gemeinsamen Attributen von Zeitschriftenaufsätzen (ZSA) und Sammelbandbeiträgen, vgl. Abschnitt 16.4.
- Der grau schraffierte Teil der Abbildung zeigt die Komposition (Position 1).
Abkürzungen:
Mono: Monographie
ZSA: Zeitschrifenaufsatz
WerkNr: Schlüssel von Werke (Überbegriff zu jeglicher Fachliteratur)
Vgl. auch Abschnitt 16.4
Die Semantik wird durch den Fremdschlüssel SBNr in der Relation SBB ausgedrückt und die Verknüpfung mit der WerkNr (vgl. Position 1). Damit ist modelltechnisch gesichert, dass die Tupel in SBB nur existieren, wenn die von SB vorhanden sind.
Semantik sucht Syntax
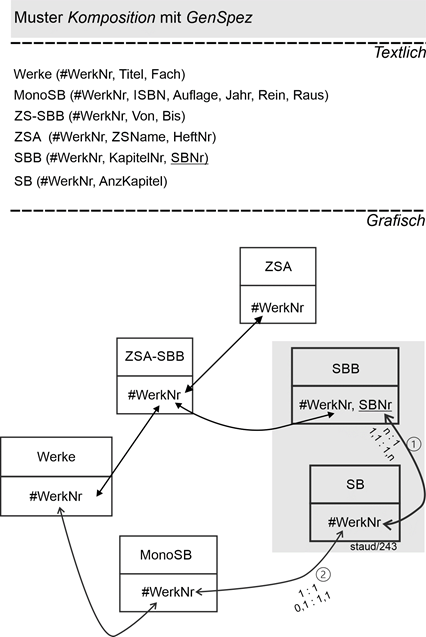
Abbildung 14.4-5: |
Muster Komposition im Anwendungsbereich Fachliteratur |
14.5 Beziehungsattribute
Beziehungen zwischen Relationen (bzw. den dort erfassten Objekten) sind erst mal genau dies: Beziehungen (wie oben gesehen) . Sie verknüpfen (typischerweise) einen Schlüssel und einen Fremdschlüssel und drücken damit die Beziehung aus. Manchmal weisen sie aber zusätzlich auch Eigenschaften auf, die als Attribute modelliert werden müssen. Diese sollen Beziehungsattribute genannt werden.
Beziehungen mit Eigenschaften
Betrachten wir zuerst den Fall von zwei Relationen. Hier müssen der Beziehung diejenigen Attribute zugewiesen werden, die weder in die eine noch in die andere der verknüpften Relationen passen.
Zwei Relationen
1:1-Beziehungen
Beginnen wir mit 1:1-Beziehungen. Diese werden im Normalfall ja einfach durch Einrichtung eines Fremdschlüssels in einer der beiden Relationen realisiert. Liegen Beziehungsattribute vor, muss je nach Wertigkeiten vorgegangen werden.
1,1 : 1,1 0,1 : 1,1 0,1 : 0,1
Bei 1,1 : 0,1 (zum Beispiel Angestellte / PC: Jeder Angestellte hat einen zugwiesenen PC, ein PC ist höchstens einem Angestellten zugeordnet) werden die Beziehungsattribute (z.B. der Tag der Einrichtung) der Relation mit dem Fremdschlüssel zugeordnet:
Angestellte – PC
Angestellte (#PersNr, ..., InvNrPC, TagEinrichtung)
PC (#InvNrPC, ...)
Entsprechend wird das Beziehungsattribut für die Wertigkeiten 0,1 : 1,1 gelöst.
Für den Fall einer Beziehung mit den Wertigkeiten 0,1 : 0,1 entsteht ja sowieso eine neue Relation für die Verknüpfung. An diese kann das Beziehungsattribut angehängt werden:
AngPC (#PersNr, #InvNrPC, TagEinrichtung)
Die Schlüssel sind wirklich so, vgl. Abschnitt 5.3
In dieser Relation gibt es nur für jeden wirklich zugewiesenen PC einen Eintrag - und dieser wird um das zusätzliche Attribut TagEinrichtung ergänzt.
1:n-Beziehungen
Bei 1,1 : 1,n - Wertigkeiten können Beziehungsattribute ebenfalls an den Fremdschlüssel angehängt werden, d.h. sie kommen in die Relation, bei der der Schlüssel der anderen Relation nur eine Ausprägung je Objekt hat. Betrachten wir das Beispiel Angestellte - Abteilungen und nehmen wir als Beziehungsattribut den Beginn der Mitarbeit (Beginn) an. Dann ergibt sich die Lösung wie folgt:
Angestellte – Abteilungen
Angestellte (#PersNr, Name, VName, GebDatum, AbtNr, Beginn)
Abteilungen (#AbtNr, Bez, Standort)
Dieselbe Lösung wird bei 1,1 : 0,n gewählt.
Im Falle von 0,1 : 1,n und 0,1 : 0,n entsteht ja eine neue Relation für die Beziehung (vgl. Abschnitt 5.5). Dieser können die Beziehungsattribute zugewiesen werden. Im hier gewählten Beispiel wäre dies die Relation Abteilungszugehörigkeit (AbtZug):
0,1 : 1,n und 0,1 : 0,n
Angestellte (#PersNr, Name, VName, GebDatum)
Abteilungen (#AbtNr, Bez, Standort)
AbtZug (#(AbtNr, PersNr), Beginn)
N:m-Beziehungen
Im Fall von n:m-Beziehungen entsteht ja bei allen Wertigkeiten eine neue Relation, die Verbindungsrelation. In diese können die Beziehungsattribute eingefügt werden. Das folgende Beispiel mit den Wertigkeiten 0,n : 0,m möge dies erläutern. Studierende können keine, eine oder mehrere Prüfungen besuchen, Prüfungen können von keinem, einem oder mehreren Studierenden absolviert werden. Die Verbindungsrelation kann dann einfach um Beziehungsattribute wie Prüfungstag (PruefTag), Note und Prüfungsnummer (PruefNr) ergänzt werden.
0,n : 0,m
1,n : 0,m
0,n : 0,m
0,n : 0.m
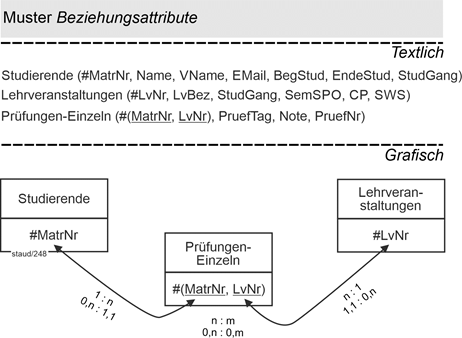
Abbildung 14.5-1: |
Muster Beziehungsattribute im Anwendungsbereich Hochschule |
Auch bei der schon oft eingebrachten Beziehung zwischen Datenbanksystemen und Händlern, können Beziehungsattribute vorliegen. Im folgenden Beispiel sind dies der Marktpreis (MPreis) und der zur Verfügung gestellte Service. Er soll von beidem, dem Datenbanksystem und dem Händler abhängen. Dies bedeutet, dass ein Händler für unterschiedliche Datenbanksysteme unterschiedliche Serviceangebote anbietet.
Datenbanksysteme - Händler
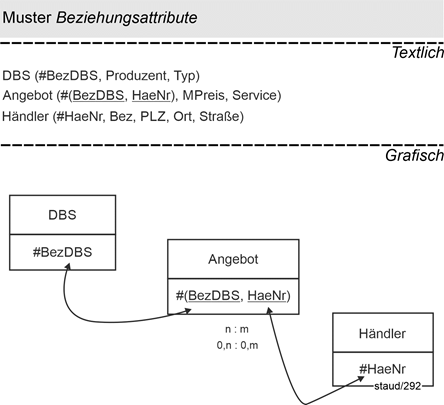
Abbildung 14.5-2: |
Muster Beziehungsattribute im Anwendungsbereich Datenbanksysteme |
Drei- und mehrstellige Beziehungen
Im Falle von mehr als zweistelligen Beziehungen werden die Beziehungsattribute der Verbindungsrelation zugewiesen. Betrachten wir als Beispiel den Anwendungsbereich Sportverein und die Beziehung Training, die Mannschaften, Trainer und Trainingsort in Beziehung setzt:
Mannschaften - Trainer – Trainingsort
Mannschaften (#MaNr, Bez, ...)
Trainer (#TrNr, Name, Vorname, ...)
Trainingsort (#OrtNr, Bez, Typ)
Für jedes Training sollen die Wertigkeiten 1,n : 1,3 : 1,1 gelten. D.h., an einem Training nimmt mindestens eine Mannschaft teil, es wird von maximal drei Trainern gestaltet und es findet immer an genau einem Ort statt (Stadion, Halle, Park, ...). Mit Hinzunahme des Tages und der Annahme, dass pro Tag nur ein Training stattfindet, ergibt sich:
Training (#(MaNr, TrNr, OrtNr, Tag))
Kommen nun Beziehungsattribute hinzu, hier Art (ArtTr) und Intensität (IntensTr) des Trainings, können diese in die Verbindungsrelation eingefügt werden:
Training (#(MaNr, TrNr, OrtNr, Tag), ArtTr, IntensTr))