Mit den folgenden Beispielen sollen ER-Modelle vorgestellt werden. Bei einigen Beispielen auch, indem der Entstehungsprozess gezeigt wird – seine Entwicklung „Schritt um Schritt“. In vollem Umfang, mit allen Einzelschritten und an einem realen Beispiel ist dies aus Platzgründen nicht möglich. Trotzdem sollten die Beispiele einen Eindruck davon geben, wie der "semantische Abschnitt" des Datenbankdesigns aussieht.
In der ER-Modellierung ist es in dieser Phase sehr wichtig, den Zusammenhang zwischen Objekten/Beziehungen (hier: Entitäten) und Attributen ganz genau zu erfassen:
- Regel 1: Nur die Attribute werden einer Entität zugewiesen, die genau diese Entität beschreiben (im Kontext der jeweiligen Aufgabe). Genauso für Beziehungen.
- Regel 2: Nur die Entitäten, die genau durch dieselben Attribute beschrieben werden, kommen zusammen in einen Entitätstyp. Dann beschreiben alle Attribute eines Entitätstyps auch alle Entitäten des Typs. Genauso für Beziehungen.
Kommt es doch zu Verletzungen dieser Regel, muss entsprechend gehandelt werden, z.B. durch eine Zerlegung im Rahmen einer Generalisierung / Spezialisierung.
Übrigens: Obige Regeln sichern die effiziente Modellstruktur, die der relationalen Theorie durch die Normalformen herbeigeführt wird.
11.1 Rechnungsstellung
Zu diesem Beispiel gibt es: Aufgabenstellung + Lösungsweg
Diese Aufgabenstellung wird auch in [Staud 2021, Abschnitt 16.1] bearbeitet. Das dort entstandene relationale Datenmodell ist inhaltlich weitgehend mit dem hier vorliegenden ER-Modell identisch.
Mit diesem Beispiel wird die Erstellung eines ER-Modells für den Zweck der Rechnungsstellung gezeigt. Ausgangspunkt ist dabei die in der folgenden Abbildung angegebene Rechnung
 , also ein Geschäftsobjekt (business object), was in der Datenmodellierung durchaus oft der Fall ist. Es gelten – neben der üblichen kaufmännischen Semantik von Rechnungen – die folgenden Bedingungen und semantischen Festlegungen:
, also ein Geschäftsobjekt (business object), was in der Datenmodellierung durchaus oft der Fall ist. Es gelten – neben der üblichen kaufmännischen Semantik von Rechnungen – die folgenden Bedingungen und semantischen Festlegungen:
Rechnungen
- Die Kunden werden mit Namen (Name), Vornamen (VName) und Anrede erfasst. Außerdem wird ein identifizierendes Attribut (KuNr) angelegt.
- Ein Kunde wird zuerst mit nur einer Adresse erfasst. Später dann mit beliebig vielen.
- Ein Kunde kann mehrere Telefonanschlüsse haben.
- In der Datenbank wird auch festgehalten, wer die Kundschaft bedient hat (Verkäufer). Dies wird auf der Rechnung ausgegeben.
- TOUR bezeichnet das Auslieferungsteam (Tour).
- KVDAT gibt den Tag an, an dem die Kundschaft im Möbelhaus war und die Ware bestellt hat (Kvdat).
- Eine Rechnung bezieht sich auf genau einen Auftrag
- Die angegebene Telefonnummer ist die der Rechnungsanschrift
Die Abkürzungen bei Position 1 bedeuten:
889999: Artikelnummer (ArtNr)
B/00/EG: Standort der Ware im Lager (Standort)
COUCHTISCH 1906 EICHE NATUR - MIT LIFT 125x71 cm: Artikelbezeichnung (ArtBez)

Abbildung 11.1-1: |
Geschäftsobjekt Rechnung (Typ Möbelhaus) |
Diese Aufgabe wird mit unterschiedlichen Komplexitätsgraden in drei Stufen gelöst:
- Aufgabe Stufe 1 – Grundstruktur: Für jeden Kunden wird nur eine Anschrift, die Rechnungsanschrift, erfasst. Es wird keine zeitliche Dimension berücksichtigt, d.h. alte Rechnungen müssen nicht aus der Datenbank heraus reproduzierbar sein.
- Aufgabe Stufe 2 – Beliebige Rechnungs- und Lieferadressen: Für jeden Kunden werden beliebig viele Adressen erfasst. Bei jedem Kauf kann ein Kunde eine beliebige seiner Adressen als Lieferadresse bzw. als Rechnungsadresse angeben.
- Aufgabe Stufe 3 – Zeitachse: Einfügen einer zeitlichen Dimension. Die Rechnungen sollen über die Zeit gerettet werden, d.h. es soll möglich sein, beliebige Rechnungen der Vergangenheit aus der Datenbank heraus zu reproduzieren. Also z.B. eine Rechnung vom 20. November 2012 mit den damaligen Preisen, der damaligen Mehrwertsteuer, usw.
11.1.1 Stufe 1
Für die Stufe 1 sammeln wir zuerst die Attribute ein und bestimmen dann die Entitätstypen. Wie immer gilt:
Zu einem Entitätstyp gehören die Attribute, die ihn identifizieren und beschreiben und die für alle Entitäten des Typs gültig sind.
Zuordnungsregel
Nun die Attribute:
- Name: des Kunden
- VName
- PLZ: der Rechnungsanschrift
- Ort
- Straße
- Tel: Telefonnummer. Ein Kunde kann mehrere haben.
- KuNr: Kundennummer. Diese ergänzen wir gleich, da die Erfassung der Kunden ohne eine Kundennummer nicht sinnvoll ist.
- ReNr: Rechnungsnummer. Diese identifiziert Rechnungen.
- ReDatum: Rechnungsdatum
- Verkäufer: die Angabe des Verkäufers erfolgt auf der Rechnung
- KVDAT: Hierbei handelt es sich um das Kaufvertragsdatum.
- Tour: Bezeichnung des Teams, das mit seinem Fahrzeug die Möbel ausliefert. Eine tiefere Semantik liegt nicht vor.
- PosNr: Rechnungspositionsnummer
- ArtNr: Artikelnummer. Eindeutig für die Artikel. Wurde ergänzt als Schlüssel für die Artikel.
- Anzahl der Artikel pro Position
- Standort: Standort der Ware im Lager.
- ArtBez: Artikelbezeichnung
- ZV: Zahlungsvereinbarung
- LiPreis: Listenpreis. Der Preis für die gesamte Position wird berechnet aus Anzahl und Preis.
Für die meisten Artikel liegt noch eine Beschreibung vor (Beschr), die aber nicht auf der Rechnung ausgegeben wird. Der Mehrwertsteuersatz wird im Programm hinterlegt, der Mehrwertsteuerbetrag (MWStB) wird dann daraus und aus der Rechnungssumme berechnet.
Was kann man nun, auch unter Berücksichtigung der ja immer vorliegenden Objekt-/Beziehungsstruktur, von den Attributen ableiten? Problemlos zu erkennen sind die Kunden: als Entitäten und als Entitätstypen. Identifiziert werden sie durch die KuNr. Folgende weitere Attribute beschreiben alle Kunden:
Entitäten und Entitätstypen finden
- Name
- VName
- Anrede
- PLZ
- Ort
- Straße
- Tel (mehrwertig)
Für die Adressangaben gilt dies nur, weil wir uns in Stufe 1 mit einer einzigen Rechnungsanschrift begnügen. Die Erfahrung hat gezeigt, dass jeder Kunde mehrere Telefonanschlüsse haben kann. Deshalb werden die Telefonnummern als mehrwertiges Attribut erfasst.
Damit ergibt sich der erste Entitätstyp Kunden (vgl. auch die folgende Abbildung).
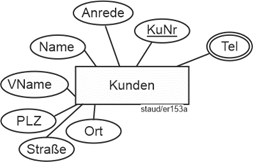
Abbildung 11.1-2: |
Rechnungsstellung, Fragment Entitätstyp Kunden |
Tel: mehrwertiges Attribut
Rechnungskopf vs. Rechnungspositionen
Ähnlich einfach ist das Erkennen der Rechnung als Modellelement. Bei genauerem Hinsehen erkennt man aber, dass es eine Unterscheidung geben muss zwischen dem Rechnungskopf (identifiziert durch die Rechnungsnummer (ReNr)) und den Rechnungspositionen. Denn es gibt pro Rechnung mehrere Positionen, so dass sich einige Attribute auf die Rechnung als Ganzes, andere auf die Positionen der Rechnung beziehen. Folgende Attribute liegen zur Rechnung vor:
- ReDatum: Es gibt genau ein Rechnungsdatum pro Rechnung und jede Rechnung hat ein Rechnungsdatum.
- Verkäufer: Durch Nachfragen wurde ermittelt, dass immer nur einer für einen Kaufvertrag zuständig ist und nur einer auf der Rechnung erscheint.
- Tour: Es gibt ein Auslieferungsteam je Rechnung.
- KVDAT: Kaufvertragsdatum, genau eines je Rechnung.
- ZV: Zahlungsvereinbarung, die je Rechnung eindeutig ist. Trotz Nachfragen konnte auch keine weitere Semantik (z.B. Abhängigkeit vom gekauften Produkt) festgestellt werden.
Ergänzt man noch das Rechnungsdatum (ReDatum), das Datum der Lieferung (DatumLief) und den Mehrwertsteuerbetrag (MWStB) ergibt sich der Entitätstyp ReKöpfe für die Rechnungsköpfe.
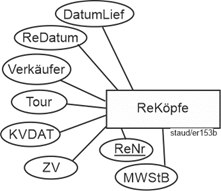
Abbildung 11.1-3: |
Rechnungsstellung, Fragment Entitätstyp Rechnungsköpfe |
Für die Rechnungspositionen wird ein Entitätstyp RePos eingerichtet. Zu ihm gehören die Attribute PosNr und Anzahl, evtl. auch die Artikelnummer. Da wir aber erkennen, dass die Artikel als eigener Entitätstyp eingerichtet werden müssen
(vgl. unten), denken wir schon voraus und lassen die ArtNr hier weg. RePos ist ein singulärer Entitätstyp, da die Existenz jeder Rechnungsposition von der Existenz des zugehörigen Rechnungskopfes abhängt. Dazu unten mehr bei der Betrachtung der Beziehungstypen. Datenbanktechnisch bedeutet das im übrigen, dass bei Löschung eines Rechnungskopfes automatisch alle zugehörigen Rechnungspositionen gelöscht werden sollten, damit die Datenbank integer bleibt.
Rechnungspositionen
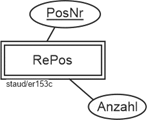
Abbildung 11.1-4: |
Rechnungsstellung, Fragment singulärer Entitätstyp Rechnungspositionen |
Doppellinie: Kennzeichnung singulärer Entitätstypen
Der letzte leicht erkennbare Entitätstyp sind die Artikel. Auch sie werden identifiziert (ArtNr), haben eine Bezeichnung (ArtBez) und werden beschrieben. Allerdings liegt nicht zu jedem Artikel eine Beschreibung vor. Gemäß der Zuordnungsregel („jedes Attribut muss auf alle Entitätstypen anwendbar sein“), müssen wir damit die Artikel mit Beschreibungen in einen eigenen Entitätstyp tun (ArtBeschr). Damit ergeben sich die folgenden Fragmente.
Artikel und Beschreibung
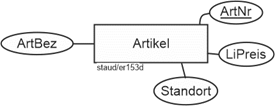
Abbildung 11.1-5: |
Rechnungsstellung, Fragment Entitätstyp Artikel |
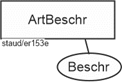
Abbildung 11.1-6: |
Rechnungsstellung, Fragment Entitätstyp Artikelbeschreibung |
Für die Artikel mit Beschreibung wird also ein eigener Entitätstyp angelegt, da es sich um eine Teilmenge aller Artikel handelt, um die mit einem zusätzlichen Attribut. Dieses Fragment ist didaktisch motiviert. Näheres vgl. unten bei der Betrachtung des Beziehungstyps zwischen den beiden Entitätstypen.
Alternativer Weg.
Oftmals wird der Zusammenhang von Rechnung und Artikel auf andere Weise erfasst. Da es typischerweise pro Rechnung mehrere Artikel gibt und die Artikel auch auf mehreren Rechnungen auftauchen (ein bestimmtes Sofa, das hundert mal verkauft wurde) wird dabei dann zuerst ein Beziehungstyp zwischen Rechnungsköpfen und Artikeln eingerichtet und diesem die PosNr als beschreibendes Attribut zugeordnet.
Obiges macht nochmals deutlich: Die Findung der Entitätstypen erfolgt über die Attribute. Wenn man hier die Zuordnungsregel sehr genau beachtet, erhält man Modellfragmente, die absolut redundanzfrei sind und die im relationalen Fall der 5NF entsprechen.
Finden der Entitätstypen
Die Beziehungstypen
Rechnungsköpfe und Rechnungspositionen stehen in einer Beziehung. Sie ist, von den Rechnungspositionen aus gesehen, sogar existenziell. Wie oben schon ausgeführt, ist RePos ein singulärer Entitätstyps bzgl. ReKöpfe. Deshalb werden die beiden Entitätstypen durch einen Beziehungstyp (R/R) verbunden, die Doppellinie drückt die Abhängigkeit aus. Die Min-/Max-Angaben ergeben sich mit 1,n bei den Rechnungsköpfen (jede Rechnung hat mindestens eine Rechnungsposition) und 1,1 bei den Rechnungspositionen (jede Rechnungsposition gehört zu genau einer Rechnung).
Rechnung
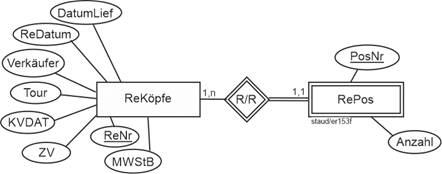
Abbildung 11.1-7: |
Rechnungsstellung, Fragment Rechnungsköpfe - Rechnungspositionen |
Zwischen Kunden und ReKöpfe liegt ebenfalls eine Beziehung vor. Für diese gilt: Ein Kunde hat u.U. viele Rechnungen mit dem Unternehmen, aber eine Rechnung bezieht sich immer nur auf einen Kunden. Diese 1:n - Beziehung führt zu einem Beziehungstyp K_RK. Die Min-/Max-Angaben sind wie folgt:
Kunden und Rechnungsköpfe
- 1,n bei den Kunden, weil wir nur Kunden erfassen, die mindestens eine Rechnung bei uns erzeugt haben. Diese könnte auch anders sein, wenn z.B. für Marketingaktionen potentielle Kunden aufgenommen würden, Dann wäre die Min-/Max-Angabe 0,n.
- 1,1 bei ReKöpfe, denn jeder Rechnungskopf bezieht sich auf genau einen Kunden.
Damit ergibt sich folgender Beziehungstyp:
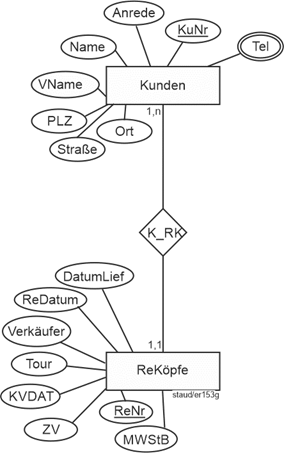
Abbildung 11.1-8: |
Rechnungsstellung, Fragment Kunden - Rechnungsköpfe |
Zwischen Kunden und Artikel gibt es semantisch natürlich eine Beziehung und – wie oben ausgeführt – wäre auch eine Modellierung mit einem Beziehungstyp Kunden-Artikel möglich. Es käme das gleiche Ergebnis raus. Hier greift aber die „kaufmännische Tiefensemantik“ („eine Rechnung hat Positionen“) ein und empfiehlt die Modellierung über einen Entitätstyp RePos. Insgesamt also von ReKöpfe zu RePos und dann zu Artikel.
Kunden und Artikel
Damit ergibt sich hier ein Beziehungstyp zwischen Rechnungspositionen und Artikel (A_RP) mit einer 1:n - Beziehung. Ein Artikel kommt hoffentlich auf vielen Rechnungspositionen vor und eine Rechnungsposition erfasst genau einen Artikel. Die Min-/Max-Angabe von 1,1 auf der Seite der Rechnungspositionen ist hier besonders sinnvoll, denn es hat keinen Sinn, Rechnungspositionen ohne Artikel zu erfassen. Bei den Artikeln ist 0,1 sinnvoll, denn es gibt sicherlich Artikel, die auf vielen Positionen auftauchen, andererseits gibt es auch welche, die noch nicht verkauft wurden.
Rechnungspositionen und Artikel
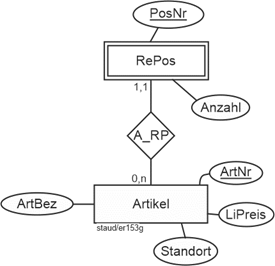
Abbildung 11.1-9: |
Rechnungsstellung, Fragment Rechnungspositionen - Artikel |
Bleibt noch der Beziehungstyp für „Artikel – Artikel mit Beschreibung“. Hier geht es darum, dass das Attribut Beschr (Beschreibung des Artikels) nicht für alle Artikel vorhanden ist. Würden wir Beschr daher bei Artikel hinzufügen, gäbe es Entitäten, für die dieses Attribut keine Ausprägung hätte. Dies widerspricht der Zuordnungsregel, weshalb ein eigener Entitätstyp für die Artikel mit Beschreibung eingerichtet wurde. Wie sieht die Beziehung aus? Diese kann als ganz normaler Beziehungstyp angelegt werden, so wie hier mit A_AB, denkbar wäre auch eine Generalisierung / Spezialisierung. Die Min-/Max-Angaben sind 0,1 bei Artikel und 1,1 bei ArtBeschr, denn jeder Artikel ist mit maximal einem Beziehungstyp dabei und jede Artikelbeschreibung gehört zu genau einem Artikel.
Artikel, ohne und mit Beschreibung
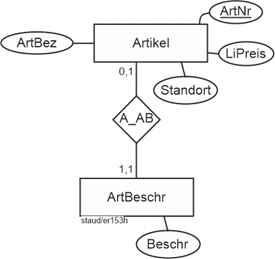
Abbildung 11.1-10: |
Rechnungsstellung, Fragment Artikel - Artikelbeschreibung |
Fügen wir obige Fragmente zusammen, ergibt sich das folgende Gesamtmodell.
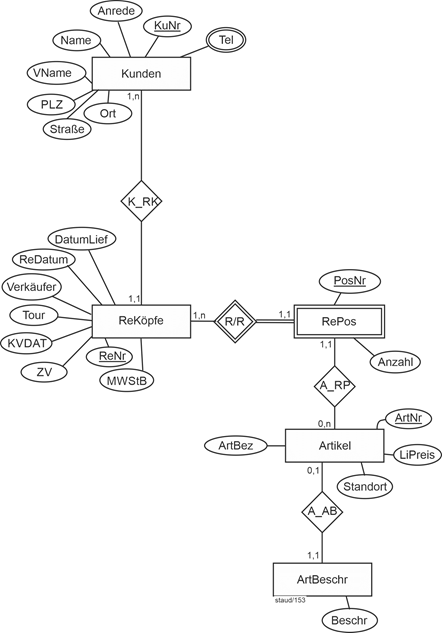
Abbildung 11.1-11: |
ER-Modell Rechnungsstellung Stufe 1 - Gesamtmodell |
Hinweise:
KVDAT: Kaufvertragsdatum
ZV: Zahlungsvereinbarung
Tel: mehrwertiges Attribut
11.1.2 Stufe 2
In Stufe 2 wird zwischen Liefer- und Rechnungsadresse unterschieden und es soll gelten: Ein Kunde kann beliebig viele Adressen haben, jede kann bei einer Rechnung Liefer- oder Rechnungsadresse sein.
Eine Folge dieser Festlegung ist, dass der alte Entitätstyp Kunden verkürzt wird, da die Adressattribute in den Entitätstyp Adressen gehen. Übrig bleiben KuNr, Name, VName, Anrede, Tel.
Beim Entitätstyp Adressen wird ein Schlüssel ergänzt (Adressnummer, AdrNr). Für den Beziehungstyp zwischen Kunden und Adressen (Ku/Adr) gelten die Min-/Max-Angaben 1,n bei Kunden (ein Kunde hat mindestens eine Adresse) und 1,n bei Adressen (zu jeder Adresse gehört mindestens ein Kunde („große Wohneinheit, Mehrfamilienhaus, usw.“). Damit ergibt sich folgendes Fragment:
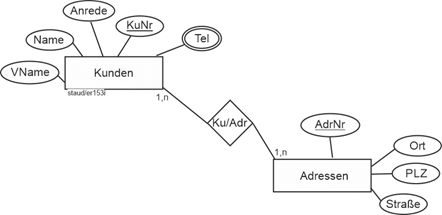
Abbildung 11.1-12: |
ER-Modell Rechnungsstellung Stufe 2 - Kunden und Adressen |
Bleibt noch zu klären, wie festgehalten wird, welche Adresse bei einer bestimmten Lieferung die Liefer- und welche die Rechnungsadresse ist. Diese Information muss sich auf das Tripel Kunden/Adressen/Rechnungsköpfe beziehen und sie muss auch erlauben, dass es auch mal nur eine einzige Adressangabe gibt.
Liefer- und Rechnungsadresse
Eine sinnvolle Lösung dafür ist, für jede Lieferung die drei Entitätstypen Kunden, Adressen und ReKöpfe mittels eines Beziehungstyps Ku/Adr/Re („Lieferungen“) zu verknüpfen und bei jeder Verknüpfung festzuhalten, ob es neben der Rechnungsadresse auch eine abweichende Lieferadresse gibt (hier mit dem Attribut Typ). Die Wertigkeiten beim Beziehungstyp Ku/Adr/Re ergeben sich wie folgt:
Dreistellige Beziehung
- Bei Kunden: Jeder Kunde ist an mindestens einer Lieferung beteiligt, hat also mindestens einmal eine Adressangabe in einem Rechnungskopf getätigt. Typischerweise mit der Rechnungsanschrift. Er kann aber auch schon mehrere Lieferungen erhalten haben.
- Bei Adressen: Bei jeder Lieferung werden mindestens eine, maximal zwei Adressen angegeben.
- Bei den Rechnungsköpfen: Jeder Rechnungskopf nimmt genau einmal an einer Beziehung teil.
Vgl. für die grafische Umsetzung das Entity Relationship - Modell unten.
Das Attribut Typ hat die Ausprägungen L(ieferadresse) und R(echnungsadresse). R gibt es immer, L nur, falls es eine extra Lieferanschrift gibt. Ansonsten ist die Rechnungsanschrift gleich der Lieferanschrift. Die folgende Tabelle zeigt zur Verdeutlichung einige Beispielsdaten:
| Typ |
ReNr |
KuNr |
AdrNr |
|---|---|---|---|
| L |
1001 |
007 |
2 |
| R |
1001 |
007 |
5 |
| R |
2002 |
007 |
1 |
| R |
2020 |
010 |
1 |
| ... |
... |
... |
... |
Zur Veranschaulichung wurde in den Daten auch der Fall eingefügt, dass unter einer Adresse mehrere Kunden wohnen (Rechnungsnummer 2002 und 2020).
Der Beziehungstyp Ku/Adr wird jetzt eigentlich nicht mehr benötigt. Da es aber oftmals sinnvoll ist, die Adressen von Kunden auch ohne die Rechnungen ansprechen zu können, z.B. bei Marketingmaßnahmen oder ganz allgemein im Customer Relationship Management (CRM), soll er drin bleiben. So kann die Pragmatik zum ER-Modell beitragen.
Pragmatik
Hier das Gesamtmodell nach Stufe 2:
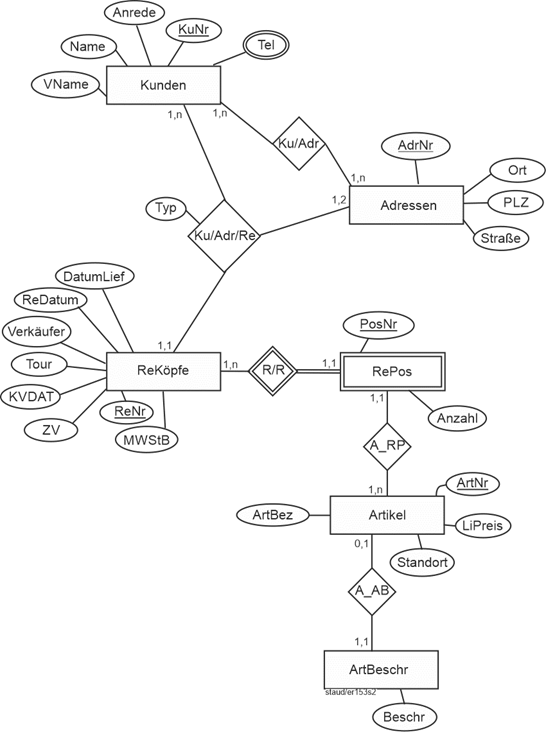
Abbildung 11.1-13: |
Rechnungsstellung Stufe 2 - Gesamtmodell |
11.1.3 Stufe 3
In der folgenden dritten Stufe soll nun die zeitliche Dimension hinzugefügt werden und zwar mit dem Ziel, die Rechnungen der vergangenen Jahre aus der Datenbank heraus reproduzierbar zu halten, auch wenn sich die Stammdaten verändern. Bei einer Rechnungsstellung entstehen ja Daten zum kaufmännischen Vorgang, die auch nicht mehr verändert werden. Z.B. Rechnungsnummer, Rechnungsdatum, Artikelbeschreibung, Positionssummen, Gesamtsumme. Andere Daten werden mit Hilfe der durch das Datenmodell vorgegebenen Struktur im Moment der Rechnungsstellung aus den Datenbeständen geholt: zum Kunden, zu den Artikeln. Genau diese Daten können sich aber nach dem Zeitpunkt der Rechnungsstellung sehr schnell ändern:
Zu „rettende“ Kundendaten
- Der Kunde zieht um, seine Telefonnummer ändert sich, er ändert seinen Namen.
- Die Artikelpreise ändern sich, Artikel verschwinden aus dem Sortiment, ihre Bezeichnung oder auch Beschreibung ändert sich.
Und so weiter. Um sich dagegen abzusichern können die "vergänglichen" Attribute bzw. deren Ausprägungen zum Zeitpunkt der Rechnungsstellung (RZP; Rechnungsstellungszeitpunkt) festgehalten werden. Dazu werden diese Attribute an geeigneter Stelle im Datenmodell angelegt und dann in der Datenbank gespeichert.
Rechnungs-stellungs-zeitpunkt RZP
Folgende Attribute müssen bezüglich der Kunden "gerettet" werden: Name, Vorname, PLZ, Ort, Straße. Dies geschieht, indem sie mit dem Zusatz "RZP" zusätzlich aufgenommen werden. Doch in welchem Entitätstyp soll man sie unterbringen? Hier gibt es mehrere Möglichkeiten, z.B. eine zeitlich fixierte Anlage im Entitätstyp Kunden bzw. Adressen. Dann gäbe es mit der Zeit eine Historie von Namen bzw. Adressen und bei Abfragen oder Auswertungen müsste auf zeitliche Übereinstimmung geachtet werden.
Historische Kundendaten
Eleganter ist die Lösung diese Daten vom Rechnungsstellungszeitpunkt bei den Entitäten zu platzieren, die ebenfalls durch diesen Zeitpunkt fixiert sind. Dies ist hier der Entitätstyp ReKöpfe. Deshalb fügen wir hier folgende Attribute an:
- Name-RZP (Name zum Zeitpunkt der Rechnungsstellung)
- VName-RZP (Zeitgeist: Thomas -> Tom)
- Ort-RZP (wegen eventuellem Umzug)
- Straße-RZP
- Tel-RZP
Da sich der Mehrwertsteuersatz ja auch regelmäßig ändert und auf der Rechnung ausgewiesen ist, muss auch er "konserviert" werden. Deshalb ergänzen wir noch MWStB-RZP.
Folgende "vergänglichen" Attribute bezüglich der Artikel sollten, da sie auf der Rechnung erscheinen, verdoppelt werden: ArtNr (Artikelnummer), ArtBez (Artikelbezeichnung), LiPreis (Listenpreis). Wieder hängen wir das Kürzel RZP an. Der Platz für diese Attributdoppelung ist, auch hier hilft wieder die Überlegung zur zeitlichen Fixierung, der Entitätstyp RePos. Damit erhält RePos folgende zusätzlichen Attribute:
Zu "rettende" Artikeldaten
- ArtNr-RZP
- ArtBez-RZP
- LiPreis-RZP
Fassen wir das Vorgehen zusammen. Folgende Schritte sind zu leisten:
- Klären, welche Attribute wegen der notwendigen Reproduzierbarkeit dupliziert werden müssen.
- Feststellen, wo diese Attribute platziert werden können.
Hier nun das gesamte Entity Relationship - Modell der Stufe 3.
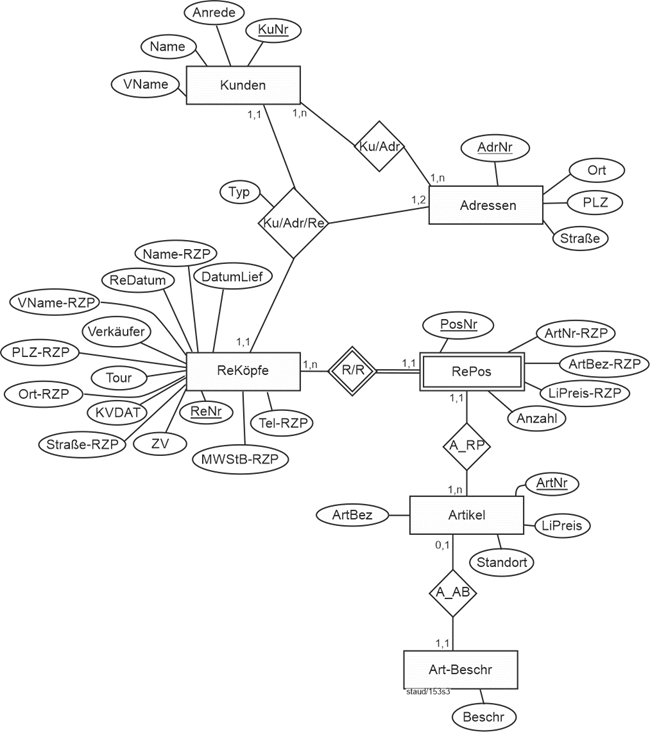
Abbildung 11.1-14: |
Rechnungsstellung Stufe 3 - Gesamtmodell |
Obige Lösung gelingt nur, weil zu einem Rechnungskopf genau ein Kunde gehört und zu jeder Rechnungsposition genau ein Artikel. Bei anderen Min-/Max-Angaben muss man andere Lösungen finden. Vgl. Kapitel 7.
![]()
11.2 Angestellte
Zu diesem Beispiel gibt es: Aufgabenstellung + Lösung + Umsetzung in ein relationales Datenmodell
Aufgabe und Lösung
Es geht um die Angestellten eines Unternehmens. Festgehalten wird ihre Tätigkeit, die evtl. Projektmitarbeit, die Abteilungszugehörigkeit und die PC-Nutzung. Dies alles gegenüber der Realität stark vereinfacht.
Folgendes soll im ER-Modell festgehalten werden:
- Für die Angestellten Personalnummer (PersNr), Name (Name), Vorname (VName) und Geburtstag (GebTag). Außerdem werden die Adressen erfasst mit Strasse, PLZ und Ort. Es kommt vor, dass Angestellte mehrere Adressen haben (Erst- und Zweitwohnsitz, usw.)
Dies führt zum Entitätstyp Angestellte. Für die Adressen wird ein eigener Entitätstyp angelgt. Der Beziehungstyp Ang-Adr stellt die Beziehung her.
- Das Vorgesetztenverhältnis. Wer ist wem unter- bzw. überstellt?
Dafür muss ein rekursiver Beziehungstyp (siehe Abschnitt 2.3) angelegt werden. Er wird An-An genannt. Ein Vorgesetzter hat zahlreiche Unterstellte, ein Angestellter ohne Leitungsfunktion hat genau einen Vorgesetzten (wir sehen hier mal von „Doppelspitzen“ ab).
- Für die Projekte die Bezeichnung (Bez), der Einrichtungstag (TagEinr), die Dauer (Dauer) und das Budget (Budget). Ein Projekt kann auf mehrere Standorte verteilt sein.
Dies führt zum Entitätstyp Projekte. Die Standorte könnten ein beschreibendes Attribut von Projekte sein, da sie aber im nächsen Punkt näher beschrieben werden, wird auch daraus ein eigener Entitätstyp.
- Die Standorte werden mit einer identifizierenden Information (OrtId), ihrer Bezeichnung (Bez) und ihrer Adresse erfasst. Außerdem wird erfasst, wieviele Mitarbeiter am Standort sind (AnzMitarb). An einem Standort muss kein Projekt sein, es können aber auch mehrere Projekte dort angesiedelt sein.
Hier wird zum einen die Beschreibung der Standorte geklärt, zum anderen auch die Beziehung zwischen Projekten und Standorten (Pr-Ort). Die Min-/Max-Angabe 0,n bei Standorte soll signalisieren, dass an einem Standort, z.B. bei der Einrichtung, auch mal kein Projekt angesiedelt sein kann.
- Ein Angestellter kann in keinem, einen oder mehreren Projekten mitarbeiten und ein Projekt hat mindestens einen (Projektleitung), typischerweise aber mehrere Mitarbeiter.
Damit wird die Beziehung zwischen Angestellten und Projekten geklärt. 1,n bei Projekte, 0,n bei Angestellte.
- Für die Abteilungen wird die Abteilungsbezeichnung (AbtBez), der Abteilungsleiter (AbtLeiter) und der Standort festgehalten. Eine Abteilung ist immer genau an einem Standort, an einem Standort können mehrere Abteilungen sein.
Dies bringt erstens Abteilungen zu einer eigenen Existenz („Identifikation + Beschreibung“), führt zweitens zur Beziehung Abteilungen / Standorte (Ab-St) und klärt drittens deren Min-/Max-Angaben. Wiederum signalisiert die Minimumsangabe 0 bei den Standorten, dass Standorte datenbanktechnisch schon erfasst werden können, bevor dort eine Abteilung eingerichtet wird.
- In einer Abteilung sind mehrere Angestellte, ein Angestellter gehört aber zu einem Zeitpunkt genau einer Abteilung. Im Zeitverlauf können Angestellte auch die Abteilung wechseln.
Dieser Absatz klärt die Beziehung Ang-Abt zwischen Angestellten und Abteilungen. Wichtig ist der Hinweis auf die zeitliche Dimension. Diese erfordert die Attribute Beginn und Ende auf dem Beziehungstyp.
- Festgehalten wird auch, welche Funktion ein Angestellter in einer Abteilung hat. Dies geschieht mit Hilfe der Funktionsbezeichnung (BezFu), dem Beginn (Beginn) und Ende (Ende) der Funktionsübernahme. Es ist durchaus möglich, dass ein Angestellter im Zeitablauf auch unterschiedliche Funktionen in einer Abteilung übernimmt. Zu einem Zeitpunkt aber immer nur eine.
Damit werden abteilungsbezogene Funktionen eingeführt. Diese werden am besten durch einen Beziehungstyp zwischen Angestellte und Abteilungen modelliert. Er wird Funktion genannt und erhält die oben angeführten Attribute. Auch hier ist die Erfassung der zeitlichen Dimension nötig.
Beispiel Beziehungsattribute
- Für die von den Angestellten benutzten PCs wird die Inventarnummer, (InvNr), die Bezeichnung (Bez) und der Typ (Typ) erfasst. Ein PC kann mehreren Angestellten zugeordnet sein, ein Angestellter nutzt zu einem Zeitpunkt maximal einen PC. Die Übernahme eines PC durch einen Angestellten wird mit der Art der Übernahme (Art; „Entwickler, Office-Nutzer, Superuser“), dem Beginn (Beginn) und dem Ende (Ende) festgehalten. Natürlich nutzt ein Angestellter im Zeitverlauf mehrere PC.
Damit werden die PC als Modellobjekte eingeführt und zwar als Einzelentitäten (PC-Einzeln) und als Typen (PC-Typen). Vgl. dazu das Muster Einzel/Typ. Außerdem wird die Beziehung zwischen Angestellten und PC geklärt. Der Beziehungstyp An-PC erhält die angeführten Attribute.
Muster Einzel/Typ
- Für die Programmiersprachen, die von den Angestellten beherrscht werden, wird die Bezeichnung der Sprache (BezPS), die Bezeichnung des Compilers (BezComp) und der Preis (PreisLiz) für eine Lizenz festgehalten. Es gibt auch Angestellte, die nicht programmieren und keine Programmiersprache beherrschen. Wegen der Bedeutung der Programmiererfahrung wird außerdem festgehalten, wieviel Jahre Programmierpraxis (ErfPS) jeder Angestellte in seinen Programmiersprachen hat. Dieser Wert wird immer zum Jahresende aktualisiert.
Die Programmiersprachen könnten, in einer einfacheren Modellierung, Attribut von Angestellte sein. Da sie aber näher beschrieben werden, wird ein Entitätstyp daraus. Die Programmiererfahrung wird am Beziehungstyp An-PS angelegt, die jährliche Aktualisierung ist nicht Gegenstand des Datenmodells.
- Für die Entwickler unter den Angestellten wird die von ihnen genutzte Entwicklungsumgebung (EntwU) und ihre hauptsächlich genutzte Programmiersprache festgehalten (HauptPS). Für die Mitarbeiter des Gebäudeservices die Funktion (Funktion) und die Schicht (Schicht), in der sie arbeiten. Für das Top-Management der Bereich in dem sie tätig sind (Bereich) und das Entgeltmodell, nach dem sie ihr Gehalt bekommen (Entgelt).
Dies führt zu einer Unterteilung der Angestellten in die drei Gruppen. Da sie alle gemeinsame und spezifische Attribute haben, entsteht im ER-Modell eine Generalisierung / Spezialisierung.
Das ER-Modell
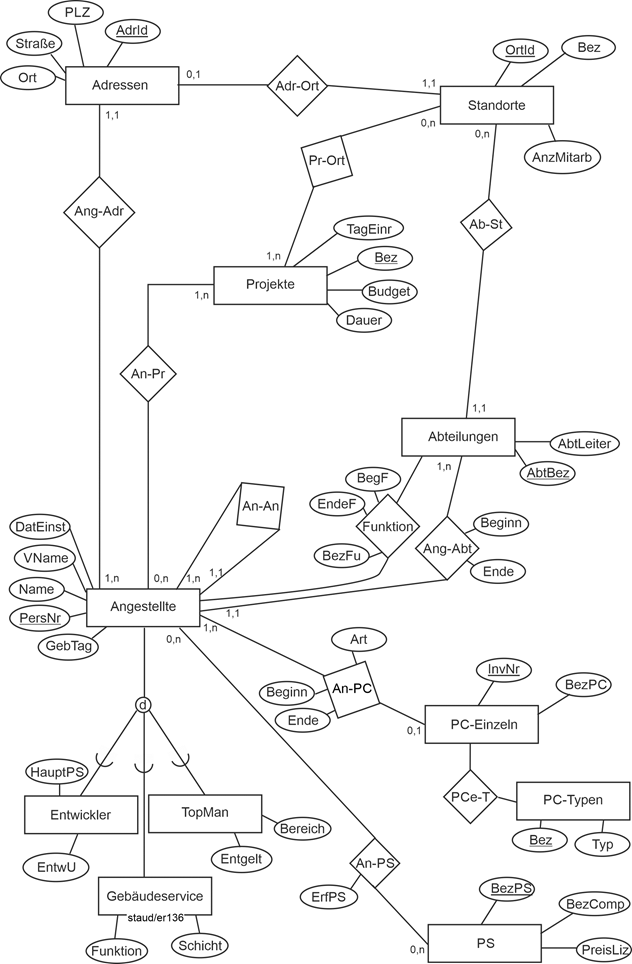
Abbildung 11.2-1: |
ER-Modell Angestellte / Abteilungen / PCs / Projekte |
11.2.1 Das relationale Datenmodell
Es ist für das Verständnis attributbasierter Modellierung sinnvoll, die Umsetzung von ER-Modellen in relationale (oder objektierte) zu betrachten. Deshalb dazu hier das entsprechende relationale Datenmodell Angestellte in textlicher Notation.
Abteilungen (#AbtBez, AbtLeiter, OrtId)
Adressen (#AdrId, PLZ, Ort, Straße)
An-An (#(PersNrV, PersNrU)) //Vorgesetzte
Ang-Abt (#(PersNr, AbtBez), Beginn, Ende))
Ang-Adr (PersNr, #AdrId)
Angestellte (#PersNr, Name, VName, DatumEinst, GebTag)
Ang-PC (PersNr, #InvNrPC, Art, Beginn, Ende))
Ang-Pr (#(PersNr, BezProj))
Ang-PS (#(PersNr, BezPS), ErfPS)
Entwickler (#PersNr, EntwU, HauptPS)
Funktionen (#(PersNr, AbtBez), BezFu, BegF, EndeF))
Gebäudeservice (#PersNr, Funktion, Schicht)
PC-Einzeln (#InvNr, BezPC)
PC-Typ (#Bez, Typ)
Projekte (#Bez, TagEinr, Dauer, Budget)
Pr-Ort (#(BezProj, OrtId))
PS (#BezPS, BezComp, PreisLiz)
Standorte (#(OrtId, Bez, AnzMitarb, AdrId)
TopMan (#PersNr, Bereich, Entgelt)
![]()
11.3 Zoo
Zu diesem Beispiel gibt es: Aufgabenstellung + Lösung
Anwendungsbereich / Aufgabenstellung
Für einen Zoo soll eine Datenbank rund um die vorhandenen Tiere erstellt werden. Dabei erfolgt eine Konzentration auf größere Tiere (Säugetiere, Reptilien, …). Allen diesen Tieren wird eine identifizierende Tiernummer (TNr), ihr Name (Name; vom Pflegepersonal vergeben), ihr Geburtstag (GebTag) und das Geschlecht zugewiesen. Außerdem wird das Gebäude erfasst, in dem Sie gehalten werden und die Gattung, zu der sie gehören
. Für jede Gattung wird auch festgehalten, wie viele Tiere dieser Gattung der Zoo hat (z.B. 5 Afrikanische Elefanten oder 20 Schimpansen) (Anzahl). Wegen der Bedeutung der Information für die Gebäude und das Außengelände wird bei Elefanten noch zusätzlich das Gewicht und bei Giraffen die Größe erfasst, jeweils mit dem Datum, zu dem der Wert erhoben wurde.
Auch die Rahmenbedingungen der Fütterung der Tiere wird festgehalten: Welches Futter (FutterBez) ein Tier bekommt (durchaus mehrere Futterarten, z.B. Heu und Frischkost), eine Beschreibung des Futters (Beschr) und welche Menge davon täglich (MengeJeTag) gegeben wird.
Für die einzelnen Gebäude des Zoos wird eine Gebäudenummer (GebNr), die Größe, der Typ (für Säugetiere, für Reptilien, usw.) und die Anzahl der Plätze (AnzPlätze) erfasst.
Das ER-Modell
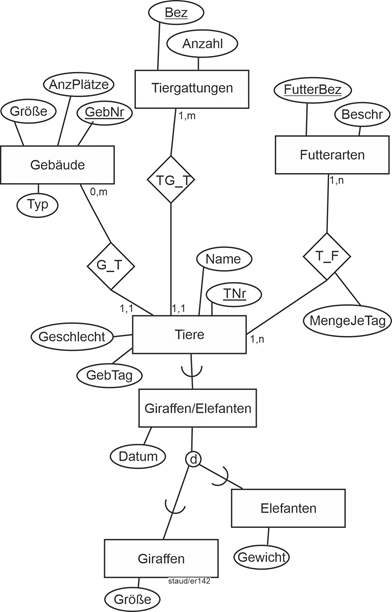
Abbildung 11.3-1: |
ER-Modell Zoo |
Das Attribut Datum ist nicht bei der Generalisierung, weil nur Giraffen und Elefanten mit Tagesdatum gewogen werden. Fügt man es bei Giraffen und Elefanten dazu, ergibt sich ein Verstoß gegen das Gen/Spez-Konzept. Der richtige Platz für dieses Attribut ist daher eine eigene Spezialisierung Giraffen/Elefanten.
![]()
11.4 Schützenverein
Zu diesem Beispiel gibt es: Aufgabenstellung + Lösung
Theorieaspekte:
- Muster Einzel/Typ
- Generalisierung / Spezialisierung
Außerdem wird bei einem Entitätstyp die zeitliche Dimension erfasst.
Anwendungsbereich
Für einen Schützenverein soll ein ER-Modell erstellt werden. Folgende Informationen werden erfasst:
- Für die Vereinsmitglieder die Mitgliedsnummer (MNr), der Name, der Vorname (VName), die (Haupt)Telefonnummer (Telefon), die Mailadresse (Mail) sowie der Hauptwohnsitz. Für diesen wird der Ort, die Postleitzahl (PLZ) und die Straße mit Hausnummer erfasst. Es wird nur eine Adresse erfasst. Außerdem soll für jedes Mitglied der Tag des Eintritts in den Verein festgehalten werden (Eintritt).
- Für die vom Verein verwalteten Waffen die Nummern der Waffen (eindeutig, vom Verein vergeben, eingraviert) (WaffNr), den Typ der Waffe (Gewehr, Revolver, Pistole, usw.) (WaffTyp), den Preis der Waffe bei der Anschaffung (Preis) und den Tag der Anschaffung der Waffe (Anschaffung). Für jeden Waffentyp wird außerdem festgehalten, wie viele Waffen man davon hat (Anzahl) und wie hoch deren Gesamtsumme bei der Anschaffung war (SumAnsch).
- Jede Nutzung einer Vereinswaffe durch ein Vereinsmitglied (auf den Schießständen des Vereins) mit dem Datum und dem Anfangs- und Endzeitpunkt der Nutzung (Datum, AnfZeit, EndZeit).
- Die Funktionen, die im Verein zu übernehmen sind (BezFkt), z.B. Aufsicht führen, Kassierer, Waffenwart, usw. Bei jeder Funktion wird festgehalten, welche Voraussetzungen nötig sind, um sie zu übernehmen (Vorauss).
- Welches Vereinsmitglied welche Funktion übernommen hat, also die Funktionsträger. Hierbei wird festgehalten, ab welchem Tag die Pflicht übernommen und wann sie (gegebenenfalls) wieder abgegeben wurde (Beginn, Ende)
- Für aktive Mitglieder (die also dem Sport wirklich nachgehen), mit welchem Waffentyp sie in den Wettkämpfen schießen. Es gibt Mitglieder, die mit mehreren unterschiedlichen Waffen aktiv sind.
- Für ehemalige Mitglieder, wann sie ausgetreten sind (Austritt) und wie viele Jahre sie Mitglied waren (Jahre).
Das ER-Modell
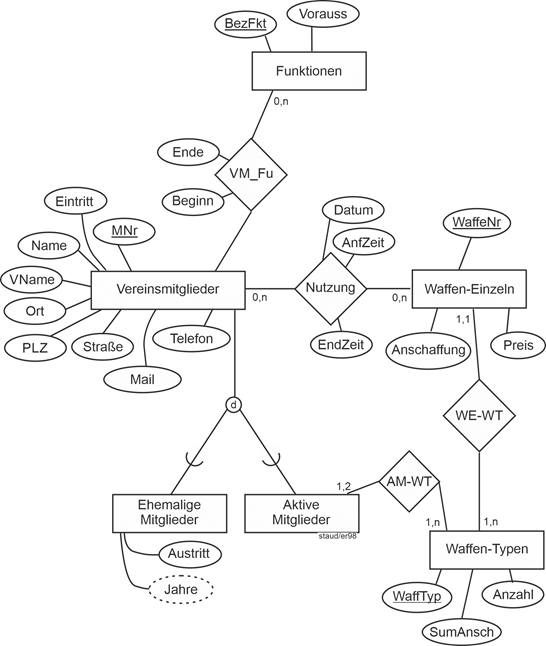
Abbildung 11.4-1: |
ER-Modell Schützenverein |
Hier liegt auch ein Muster Einzel/Typ vor: zwischen den Entitätstypen Waffen-Einzeln und Waffen-Typen. Durch die Berücksichtigung dieses Musters können die Informationen redundanzfrei gespeichert werden. Die Min-/Max-Angaben sind entsprechend: Jede einzelne Waffe gehört zu einem Waffentyp, zu einem Waffentyp gehören u.U. viele Einzelwaffen.
Muster Einzel/Typ
Die zeitliche Dimension bei den Mitgliedern (Eintritt, Austritt) wurde hier so umgesetzt, dass für Ehemalige Mitglieder ein eigener Entitätstyp angelegt wurde. Bei der Funktionsübernahme und bei der Nutzung der Waffen wurde dagegen pragmatisch modelliert, d.h. das jeweilige Ende bleibt unbeschrieben, bis es erreicht ist.
Zeitliche Dimension
![]()
11.5 Sportverein
Zu diesem Beispiel gibt es: Aufgabenstellung + Lösungsweg
Anwendungsbereich
Ein Sportverein beschließt, seine Aktivitäten (Mitgliederverwaltung, Sportveranstaltungen, usw.) in Zukunft computergestützt abzuwickeln. Dazu soll im ersten Schritt eine einfache Datenbank aufgebaut werden, für die folgende Spezifikationen festgehalten werden:
Beispiel Sportverein
- Der Sportverein ist in Abteilungen gegliedert. Eine für Handball, eine für Fußball. Weitere können in der Zukunft dazukommen.
- Jede Abteilung hat einen Leiter.
- Jede Abteilung hat mehrere Mannschaften.
- Von jeder Mannschaft werden die Spieler, der Kapitän und die Liga festgehalten, in der sie spielt (Bundesliga, usw.)
- Jede Mannschaft hat einen Trainer.
- Die Begegnungen von Mannschaften des Vereins mit Datum, gegnerischer Mannschaft und Ergebnis sollen festgehalten werden.
Die Mitglieder des Vereins werden durch Name, Vorname, PLZ, Ort, Straße, Telefon, Geburtstag, Alter und eine Mitgliedsnummer (Nr) festgehalten.
Außerdem wird für die Mitglieder erfasst, ob es sich um ein passives oder ein aktives Mitglied handelt. Für jedes aktive Mitglied wird dann noch festgehalten, welche Sportart es in welcher Leistungsstufe betreibt; für die passiven Mitglieder wird erfasst, für welche ehrenamtliche Tätigkeit sie zur Verfügung stehen.
Aktiv / passiv
Wie sehen nun die konkreten Modellierungsschritte aus? Sinnvoll ist es, zuerst die Entitätstypen zu suchen. Dies ist dann allerdings keine endgültige Festlegung, sondern eine, die im Verlauf der Modellierung auch wieder korrigiert werden kann.
Erste Schritte
Beginnen wir also mit Entitäten und Entitätstypen. Diese erkennt man im modellierungstechnischen Sinne daran, dass es sich erstens um Objekte im allgemeinen Sinn handelt und dass zweitens diese Objekte durch Attribute beschrieben werden. Zweiteres ist von zentraler Bedeutung, denn sonst kann es sich auch um ein Attribut handeln, wie auch dieses Beispiel gleich zeigen wird.
Entitäten und Entitätstypen erkennen
Natürlich etablieren auch andere nicht-konventionelle Attribute einen Entitätstyp. Z.B. Grafiken, Bilder, Videos, usw. Allerdings sind diese nur Ergänzungen der Basisbeschreibung durch Attribute, die auf jeden Fall vorhanden sein muss.
Hier ist ein Entitätstyp sofort erkennbar, die Mitglieder. Die Vereinsmitglieder existieren – auch im allgemeinen Sinn – und sie werden durch Attribute beschrieben. Das Alter wurde als Beispiel eines abgeleiteten Attributs hinzugefügt.
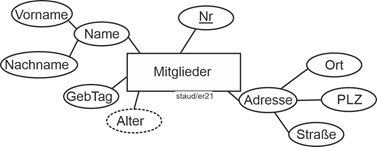
Abbildung 11.5-1: |
Modellierung der Mitglieder |
Adresse, Name: zusammengesetzte Attribute
Alter: abgeleitetes Attribut
Wichtig bei der Findung von Entitätstypen ist die umfassende Beachtung der Zuordnungsregel, wie sie in Abschnitt 3.1 formuliert wurde.
Offen bleibt bzgl. der Mitglieder noch die Frage, wie die Eigenschaft, aktives oder passives Vereinsmitglied zu sein, erfasst wird. Ginge es nur um diese Eigenschaft, würde einfach ein Attribut aktiv/passiv mit diesen zwei Eigenschaften an den Entitätstyp Mitglieder angefügt. Nun ist es hier aber so, dass für die aktiven und passiven Mitglieder jeweils unterschiedliche Attribute festgehalten werden sollen. Deshalb müssen diese Teilgruppen der Mitglieder getrennt erfasst und – da sie ja als Mitglieder auch gemeinsame Attribute haben – mit der in Abschnitt 5.1 vorgestellten Generalisierung / Spezialisierung angelegt werden:
Aktiv / passiv
Hinzugenommen wurde in der Generalisierung (Mitglieder) ein Attribut Status mit den Ausprägungen passiv und aktiv, mit dem es möglich ist, die allgemeinen Attribute (Adressen) der beiden Gruppen gezielt anzusprechen.
Hinweis: Das Attribut mit den Punkten soll oben und im Folgenden die schon vorher eingeführten Attribute andeuten.
Die aktiven Mitglieder erhalten die Attribute Sportart (derzeit nur Handball oder Fußball) und Leistungsstand. Es wird davon ausgegangen, dass ein Spieler nur eine Sportart betreibt. Das Attribut ehrenamtliche Tätigkeiten der passiven Mitglieder erfasst in einer verkodeten Form, für was das Mitglied zur Verfügung steht. Es handelt sich um ein mehrwertiges Attribut.
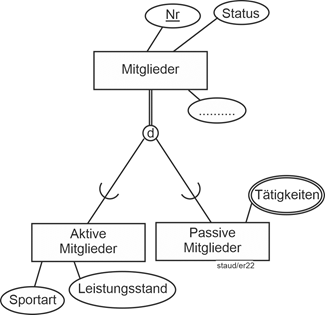
Abbildung 11.5-2: |
Aktive und passive Mitglieder in einer Generalisierung / Spezialisierung |
Tätigkeiten: mehrwertiges Attribut
Wie in Abschnitt 4.3 gezeigt, gibt es in ER-Modellen die Möglichkeit, grafisch auszudrücken, dass alle Entitäten des übergeordneten Typs an der Spezialisierung teilnehmen müssen. Diese totale Beteiligung wurde oben durch den Doppelstrich zwischen dem übergeordneten Typ und dem d-Kreis ausgedrückt. Er signalisiert hier, dass alle Mitglieder entweder aktive oder passive Mitglieder sein müssen.
Totale
Beteiligung
Bei Beziehungen wird „totale Beteiligung“ durch die Min-/Max-Angaben festgelegt. Steht als Mindestwert ein Wert größer 0 da, müssen alle Entitäten des Entitätstyps an der Verbindung teilhaben.
Betrachten wir nun die Mannschaften. Sie tauchen mit folgenden Beschreibungen auf:
Mannschaften
- Jede Abteilung hat mehrere Mannschaften, insofern könnte „Mannschaft“ ein Attribut von Abteilung sein.
- Von jeder Mannschaft werden Spieler, Kapitän, Liga, Trainer und Begegnungen festgehalten.
Letzteres macht die Mannschaften zu Entitätstypen, da sie durch weitere Attribute beschrieben werden. Die Klärung der Frage, ob sie evtl. ein Beziehungstyp sein können, wird auf eine spätere Phase des Modellierungsvorgangs verschoben. Damit ergibt sich folgender erster Entwurf:
Findung Entitätstyp – Beispiel

Abbildung 11.5-3: |
Entitätstyp Mannschaften |
Hinzugefügt wurde ein Attribut Name, mit der Bezeichnung der Mannschaften. Das Attribut Spieler ist mehrwertig, da jede Mannschaft mehrere Spieler hat.
Auf die Aufnahme eines Attributs Begegnung wurde verzichtet, da die Begegnungen durch weitere Attribute zu einer eigenständigen Existenz kommen. Im beschreibenden Text wurde festgelegt, dass alle Begegnungen von Mannschaften des Vereins mit Tagesdatum, Gegner und Ergebnis festgehalten werden sollen. Damit entsteht ein entsprechender Entitätstyp. Gleichzeitig wird hier der erste Beziehungstyp deutlich, der mit M_B bezeichnet werden soll und schlicht die Tatsache beschreibt, dass die Mannschaften des Vereins an den Begegnungen teilnehmen. Da auch nur solche Begegnungen erfasst werden, handelt es sich um einen singulären Entitätstyp, der durch ein Rechteck mit Doppellinie dargestellt wird (vgl. Abschnitt 2.4). Der zugehörige Beziehungstyp erhält ebenfalls eine solche.
Begegnungen
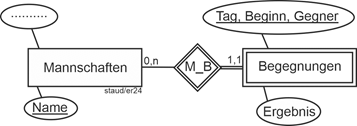
Abbildung 11.5-4: |
Singulärer Entitätstyp Begegnungen |
Zusammengesetzter Schlüssel: (Tag, Beginn, Gegner). Das Attribut Beginn wurde zusätzlich aufgenommen, um mehrere Begegnungen an einem Tag, z.B. im Rahmen eines Turniers, unterscheiden zu können. Schlüssel für diesen Entitätstyp sind die Attribute Tag, Beginn und Gegner zusammen.
Zu beachten ist, dass es nur um die Spiele des betrachteten Vereins geht, nicht um alle Spiele einer Liga, was die Situation verändern würde.
Als Schlüssel wurde hier ein zusammengesetzter genommen, der bei der Überführung in konkretere Strukturen (Z.B. in Relationen) um den Schlüssel von Mannschaften ergänzt werden müsste. Dies ist typisch für singuläre Entitätstypen. Ihre Existenzabhängigkeit zeigt sich auch darin, dass ihr Schlüssel um den des anderen Entitätstyps ergänzt werden muss.
Jetzt müssen noch die Abteilungen betrachtet werden. Für sie wurde oben festgehalten, dass der Verein in Abteilungen gegliedert ist (Handball und Fußball), dass jede Abteilung eine/n Leiter/in und mehrere Mannschaften hat.
Abteilungen
In Konfrontation mit den schon erstellten Modellfragmenten lässt sich damit festhalten, dass Abteilungen ein Entitätstyp mit den Attributen Leiter und Sportart ist. Die Tatsache, welche Mannschaft zu welcher Abteilung gehört, wird nicht durch ein Attribut festgehalten, sondern durch einen Beziehungstyp M_A zwischen Mannschaften und Abteilungen:
Beziehungstyp M_A
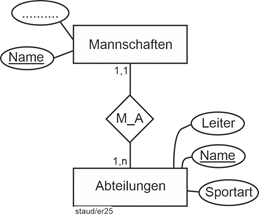
Abbildung 11.5-5: |
Beziehung Mannschaften in Abteilungen |
Damit sind die wichtigsten Komponenten des zu erstellenden Datenmodells realisiert. In der folgenden Abbildung werden sie zusammengestellt. Die Min-/Max-Angaben haben folgende Bedeutung:
- 1,1 bei Mannschaften -- Abteilungen (M_A): Eine Mannschaft gehört zu genau einer Abteilung.
- 0,n bei Mannschaften -- Begegnungen (M_B): Eine Mannschaft hat an keiner (z.B., wenn sie neu aufgestellt wurde) oder an mehreren Begegnungen teilgenommen.
- 1,1 bei Begegnungen -- Mannschaften (M_B): Eine Begegnung wird nur dann als solche aufgenommen, wenn genau eine Mannschaft „unseres“ Vereins teilgenommen hat. Wir schließen hier also bewusst Begegnungen zwischen zwei Mannschaften des Vereins aus.
- 1,n bei Abteilungen -- Mannschaften (M_A): Eine Abteilung hat mindestens eine Mannschaft.
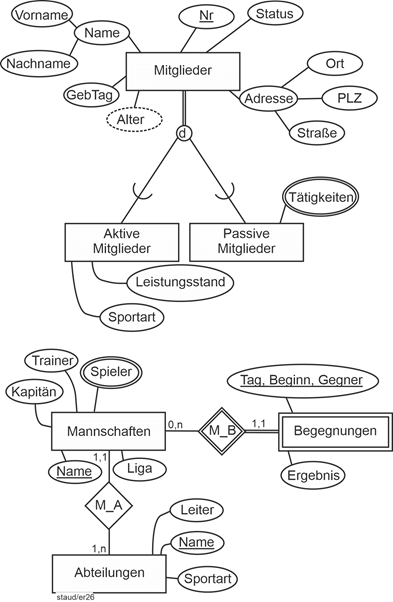
Abbildung 11.5-6: |
Gesamtmodell Sportverein - Erster Versuch |
Dieses Gesamtmodell ist nun aber in einem wichtigen Punkt fehlerhaft: Eine Trennung eines Datenmodells in zwei unverbundene Teile ist nicht möglich. So etwas gibt es nicht, da ein Datenmodell sich ja gerade dadurch auszeichnet ist, dass zusammengehörige Informationen über einen Weltausschnitt verwaltet werden. Sonst sind es zwei Datenmodelle mit zwei verschiedenen Datenbanken.
Defizit: Trennung
Bei genauerer Betrachtung zeigt sich nun aber, dass natürlich die Mitglieder mit den organisatorischen Aspekten des Vereins auf vielfältige Weise verknüpft sind. Insbesondere durch folgende Aspekte:
Korrektur
- Aktive Mitglieder spielen in Mannschaften
- Aktive Mitglieder können Kapitän einer Mannschaft sein
- Aktive Mitglieder trainieren die Mannschaften (wir gehen davon aus, dass die Trainer als aktive Mitglieder zum Verein gehören)
- Aktive Mitglieder leiten die Abteilungen
Alle diese Informationen wurden im obigen ersten Entwurf – herrührend von den Modellkomponenten – als Attribute von Entitätstypen definiert. Dies muss nun geändert werden.
Beginnen wir mit den Spielern der Mannschaften. Diese Information sollte nicht als mehrwertiges Attribut von Mannschaften erfasst werden, sondern als Beziehungstyp zwischen Mannschaften und Aktive Mitglieder: AM_S. Damit ist nicht nur die Information der Mannschaftszugehörigkeit eindeutig erfasst, sondern es stehen auch die Adressen der Mannschaftsmitglieder zur Verfügung und die Namen der Spieler werden nur einmal erfasst, im Mitgliederverzeichnis, wo sie hingehören.
Spieler der Mannschaften
AM_S
Ganz ähnlich bei der Erfassung der Trainer. Bisher als Attribut von Mannschaft erfasst, werden sie nun zu einer Beziehung zwischen Trainern und Mannschaften: AM_T.
AM_T
Die Kapitäne der Mannschaften werden ebenfalls durch eine Beziehung zwischen Mannschaften und Aktive Mitglieder erfasst, AM_K, denn die Kapitäne sollen in unserem Datenmodell aktive Mitglieder sein.
Die Leiter der Abteilungen werden dementsprechend als Beziehung zwischen Abteilungen und Aktive Mitglieder erfasst: AM_A.
In der folgenden Abbildung nun das Gesamtmodell mit den besprochenen Korrekturen. Weggefallen sind nun die diversen Attribute, mit denen vorher die Beziehungen festgelegt wurden. Die weiteren Min-/Max-Angaben sind ebenfalls angegeben. Sie bedeuten:
- 0,1 bei Aktive Mitglieder -- Mannschaften und Beziehung AM_S: Ein aktives Mitglied spielt in maximal einer Mannschaft. Selbstverständlich wäre an der zweiten Position auch ein höherer Wert möglich, falls die Semantik es erfordert. Ebenso ein Wert größer Null an der ersten Position.
- 0,1 bei Aktive Mitglieder -- Mannschaften und Beziehung AM_T: Ein aktives Mitglied kann in maximal einer Mannschaft Trainer sein (Für diese und die anderen Festlegungen gilt, dass die Semantik natürlich auch anders sein kann).
- 0,1 bei Aktive Mitglieder -- Mannschaften und Beziehung AM_K: Ein aktives Mitglied ist in maximal einer Mannschaft Kapitän.
- 0,1 bei Aktive Mitglieder -- Abteilungen und Beziehung AM_A: Ein aktives Mitglied leitet maximal eine Abteilung.
- 1,1 bei Mannschaften -- Aktive Mitglieder und Beziehung AM_T: Eine Mannschaft wird von genau einem aktiven Mitglied trainiert.
- 11,15 bei Mannschaften -- Aktive Mitglieder und Beziehung AM_S: Eine Mannschaft besteht aus mindestens 11 und maximal 15 Spielern (aktive Mitglieder).
- 0,1 bei Mannschaften -- Aktive Mitglieder und Beziehung AM_K: Eine Mannschaft hat maximal einen Kapitän.
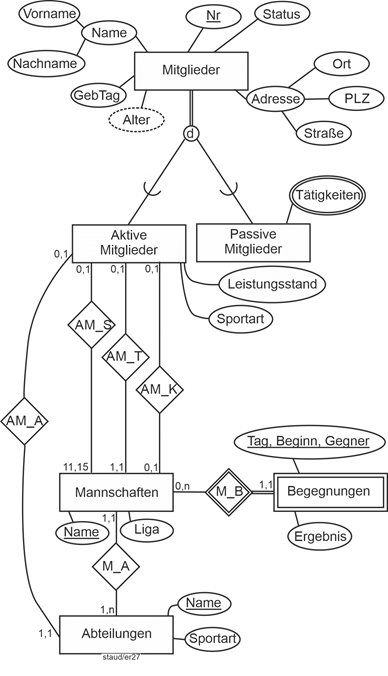
Abbildung 11.5-7: |
Entity Relationship - Modell Sportverein - Endfassung |
![]()
11.6 PC-Beschaffung
Zu diesem Beispiel gibt es: Aufgabenstellung + Lösungsweg
11.6.1 Anwendungsbereich
In einem Unternehmen soll der Vorgang der PC-Beschaffung durch eine Datenbank festgehalten werden. Dafür soll ein ER-Modell erstellt werden. Folgende Festlegungen ergaben sich in den Interviews, die im Vorfeld mit den Betroffenen geführt wurden. Die Attributsnamen wurden, soweit möglich, auch gleich geklärt:
- Jeder PC erhält eine Inventarnummer (InvPC). Neben dieser wird der Prozessortyp (Proz) und die Größe des Arbeitsspeichers (ArbSp) festgehalten.
- Bildschirme erhalten ebenfalls eine Inventarnummer (InvBild). Außerdem wird für sie die Seriennummer (SerNr), der Typ (BSTyp) und der Durchmesser (Zoll) festgehalten. Jedem PC sind maximal zwei Bildschirme zugeordnet.
- Für jeden PC wird folgendes festgehalten: der Prozessortyp (Proz), die Größe des Arbeitsspeichers (ArbSp), ob ein DVD-Laufwerk - Laufwerk vorhanden ist und falls ja, welche Bezeichnung (DVDBez) und welche Geschwindigkeit (Geschw) es hat. Außerdem werden jeweils mit Hilfe einer Kurzbezeichnung (KBezSK) die sonstigen Komponenten (Streamer, SoundBlaster, externe Platten usw.) festgehalten. Jede dieser Komponenten ist genau einem PC zugeordnet. Ein PC hat natürlich typischerweise mehrere.
- Für jede Festplatte wird festgehalten: Name und Größe (PlName, Größe) sowie die Zugriffsgeschwindigkeit (Zugriff), die Seriennummer (SerNr) (diese ist eindeutig, auch über Hersteller hinweg) und der Tag, an dem die Platte in den Rechner eingebaut wurde (TagEinbau).
- Ein PC kann mehrere Festplatten haben, eine Festplatte ist aber nur einem PC zugeordnet.
- Für jeden PC wird weiterhin festgehalten, in welcher Abteilung er steht (Abteilung), wer ihn nutzt (erfasst über die PersNr) und wann er dort eingerichtet wurde (Einrichtung). Es kommt vor, wenn auch nicht oft, dass ein PC von mehreren Mitarbeitern genutzt wird. Allerdings ist er immer einer einzigen Abteilung zugewiesen.
- Die Nutzer werden durch ihre Personalnummer (PersNr), den Namen (Name, Vorname) und ihre Telefonnummer (Tel) erfasst. Außerdem wird festgehalten, ab welchem Datum die Nutzung erfolgte (Beginn). Nach dem Ende der Nutzung, wird auch dies festgehalten (Ende).
Mit diesem Beispiel wird u.a. folgendes Ziel verfolgt: Es soll auf die Unterscheidung von Einzelobjekt und Gruppe gleichartiger Objekte (hier im Weiteren nicht ganz korrekt „Typ“ genannt) hingewiesen werden. Z.B. auf die Unterscheidung von einzelnen Festplatten (identifiziert durch ihre Seriennummer) und Festplattentyp (alle gleichen). Diese Unterscheidung muss bei der Modellierung beachtet werden.
Muster Einzel/Typ
11.6.2 Lösungsweg
Betrachten wir zur Erstellung des Datenmodells nochmals die Spezifikationen, Schritt um Schritt, jeweils mit Spiegelstrichen.
- Jeder PC erhält eine Inventarnummer (InvPC). Neben dieser wird der Prozessortyp (Proz) und die Größe des Arbeitsspeichers (ArbSp) festgehalten.
- Bildschirme erhalten ebenfalls eine Inventarnummer (InvBild). Außerdem wird für sie die Seriennummer (SerNr), der Typ (BSTyp) und der Durchmesser (Zoll) festgehalten. Jedem PC sind maximal zwei Bildschirme zugeordnet.
Hier werden zwei potentielle Entitätstypen direkt durch identifizierende Attribute angesprochen. Um zu erkennen, ob tatsächlich Entitätstypen entstehen, prüfen wir die übrigen Texte und erkennen, dass schon in der nächsten Spezifikation Attribute von PCs genannt werden. Also entsteht ein Entitätstyp PC (dazu mehr unten). Genauso bei den Bildschirmen. Hier werden auch gleich mehrere beschreibende Attribute genannt. Damit ergibt sich ein Entitätstyps Bildschirme. Ohne diese weiteren Attribute wäre InvBild einfach ein Attribut von PC. Aus pragmatischen Gründen ergänzen wir ein Attribut Bildschirmbezeichnung (BSBez) [Anmerkung] .
Identifikation + Beschreibung -> Existenz
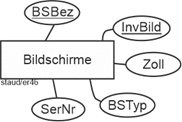
Abbildung 11.6-1: |
Entitätstyp Bildschirme - erste Fassung |
Außerdem ergibt sich damit gleich ein Beziehungstyp, denn PCs und Bildschirme sind ja verknüpft und wir müssen sicherlich festhalten, welcher Bildschirm an welchem PC dient. Dazu unten mehr.
Mit Hilfe des folgenden Ausschnitts aus der Spezifikation ergänzen wir nun die Beschreibung des Entitätstyps PC um die angegebenen Attribute. Unkritisch sind die Attribute Proz und ArbSp. Doch was ist mit den DVD – Laufwerken und mit den „sonstigen Komponenten“?
- Für jeden PC wird folgendes festgehalten: der Prozessortyp (Proz), die Größe des Arbeitsspeichers (ArbSp), ob ein DVD-Laufwerk - Laufwerk vorhanden ist und falls ja, welche Bezeichnung (DVDBez) und welche Geschwindigkeit (Geschw) es hat. Außerdem werden jeweils mit Hilfe einer Kurzbezeichnung (KBezSK) die sonstigen Komponenten (Streamer, SoundBlaster, externe Platten usw.) festgehalten. Jede dieser Komponenten ist genau einem PC zugeordnet. Ein PC hat natürlich typischerweise mehrere.
Die DVD – Laufwerke kommen modellierungstechnisch zu einer eigenen Existenz, da sie identifiziert und beschrieben werden. Also entsteht ein Entitätstyp DVD-LW. Damit ist auch die Frage beantwortet, wie festgehalten wird, ob ein PC eines hat oder nicht: über die Beziehung zwischen PC und DVD-LW. Dazu unten mehr.
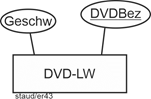
Abbildung 11.6-2: |
Entitätstyp CD-Rom - Laufwerke |
Für die sonstigen Komponenten ist die Situation einfacher. Da sie nur durch eine Kurzbezeichnung KBezSK identifiziert werden, entsteht hier einfach ein Attribut von PC, allerdings ein mehrwertiges, wie der Text auch ausdrücklich festhält. Insgesamt ergibt sich damit der Entitätstyp PC (erst mal) wie folgt:
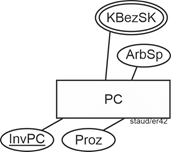
Abbildung 11.6-3: |
Entitätstyp PC - Version 1 |
Der nächsten Abschnitte der Spezifikation legt fest, wie die Festplatten erfasst werden:
Festplatten
- Für jede Festplatte wird festgehalten: Name und Größe (Plbez, Größe) sowie die Zugriffsgeschwindigkeit (Zugriff), die Seriennummer (SerNr) (diese ist eindeutig, auch über Hersteller hinweg) und der Tag, an dem die Platte in den Rechner eingebaut wurde (DatEinb).
- Ein PC kann mehrere Festplatten haben, eine Festplatte ist aber nur einem PC zugeordnet.
Hier liegt wiederum das Muster Einzel/Typ vor. Zum einen werden die einzelnen Festplatten identifiziert und beschrieben (SerNr, DatEinb), zum anderen die Fetplattentypen mit PlBez, Größe und Zugriff. Deshalb entstehen die beiden Entitätstypen FP-Einzeln und FP-Typ mit dem Beziehungstyp FP-T/E. Die Min-/Max-Angaben sind:
Identifikation + Beschreibung
- 1,1 bei FP-Einzeln, denn eine bestimmte Festplatte gehört zu genau einem Typ.
- 1,n bei FP-Typen, denn zu einem Festplattentyp gehören eine oder mehrere konkrete Festplatten.
Die Beziehung der Festplatten zu den PC wird unten geklärt.
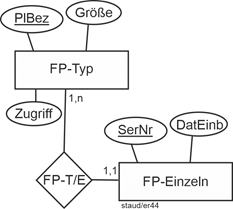
Abbildung 11.6-4: |
Entitätstyp Festplatten - erste Fassung |
Der folgende Ausschnitt aus der Spezifikation klärt das Umfeld der im Unternehmen eingesetzten PCs.
- Für jeden PC wird weiterhin festgehalten, in welcher Abteilung er steht (Abteilung), wer ihn nutzt (erfasst über die PersNr) und wann er dort eingerichtet wurde (Einrichtung). Es kommt vor, wenn auch nicht oft, dass ein PC von mehreren Mitarbeitern genutzt wird. Allerdings ist er immer einer einzigen Abteilung zugewiesen.
Betrachten wir zuerst die Angabe der Abteilung, in der er steht. Würden irgendwo die Abteilungen noch weiter beschrieben, müsste ein eigener Entitätstyp für sie eingerichtet werden. Da dies hier nicht der Fall ist, wird Abteilung(sname) zu einem Attribut von PC.
Umfeld der PC
Wie erfassen wir den oben ebenfalls angeführten Einrichtungszeitpunkt? Hätten wir einen Entitätstyp Abteilungen, wäre alles einfach. Wir würden dann den Einrichtungszeitpunkt auf den Beziehungstyp zwischen Abteilungen und PC legen, denn da gehört er semantisch hin. Da hier aber die Abteilungen nicht als Entitätstyp gewünscht werden, bleibt nur die Notlösung, Einrichtung zu einem Attribut von PC zu machen.
Pragmatik
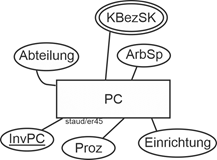
Abbildung 11.6-5: |
Entitätstyp PC - Version 2 |
Ähnliche Überlegungen wie bei der Klärung des Standortes (Abteilung) sind bei den Nutzern anzustellen. Sie werden in obigem Text nur über die Personalnummer erfasst. Insoweit wäre PersNr ein Attribut von PC. Da aber im nächsten Abschnitt der Spezifikation die Nutzer weiter modelliert werden, werden sie zu einem eigenen Entitätstyp Nutzer mit den angegebenen Attributen.
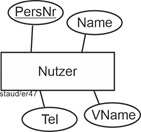
Abbildung 11.6-6: |
Entitätstyp Nutzer |
Damit sind die Fragmente des Datenmodells zusammengestellt. Bleibt noch die Präzisierung durch Klärung eventueller Muster und der Zusammenhang, die Beziehungen zwischen den Entitätstypen.
11.6.3 Präzisierung und Zusammenhänge
Die Beziehung zwischen PC und Bildschirmen ist direkt im Text angegeben, bedarf aber der Klärung, ob Einzelgeräte oder Gerätetypen modelliert werden. Auf Seiten der PCs natürlich Einzelgeräte, dies zeigt auch der vorgeschlagene Schlüssel.
PC – Bildschirme
Bei den Bildschirmen deutet der Schlüssel InvBild an, dass unsere „Auftraggeber“ hier Einzelgeräte modelliert haben möchten. Damit hätten wir aber Redundanz, wenn wir die Modellierung so belassen wie oben vorgeschlagen und wenn wir einfach einen Beziehungstyp zwischen PC und Bildschirme platzieren. Wenn wir hundert technisch identische Bildschirme kaufen würden, würde unsere Datenbank hundertmal festhalten, dass diese (z.B.) 24 Zoll groß und vom Typ XYX sind.
Wo liegt der Fehler? Ganz einfach, die vier Attribute von Bildschirme beschreiben unterschiedliche Informationsträger. InvBild und SerNr beschreiben Einzelgeräte, die beiden anderen (Zoll und BSTyp) aber die Gruppe der technisch gleichen Geräte, hier Gerätetypen genannt. BSTyp kann dafür als Schlüssel genommen werden. Also muss dieser Entitätstyp in zwei aufgespaltet werden, BS-Einzeln und BS-Typen, die aber verknüpft sind (Beziehungstyp PC-B; vgl. die folgende Abbildung): Ein bestimmter Bildschirm gehört zu genau einem Gerätetyp, ein Gerätetyp hat mindestens ein zugehöriges Gerät (sonst wäre er in unserer Datenbank nicht erfasst), kann aber beliebig viele haben. Wie meist beim Muster Einzel/Typ sind die Min-/Max-Angaben 1,1 bzw. 1,n.
Muster Einzel/Typ
Der Fehler resultierte also aus einem Verstoß gegen eine zentrale Regel der ER-Modellierung, dass nur die Attribute zu einem Entitätstyp genommen werden, die genau dessen Entitäten beschreiben.
Verstoß gegen Zuordnungsregel
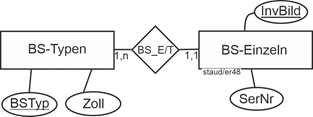
Abbildung 11.6-7: |
Einzelgeräte und Gruppe gleichartiger Entitäten als Entitätstypen |
Die Beziehung PC_B zwischen Bildschirme und PC muss nun auf Seiten der Bildschirme 1,1 als Min-/Max-Angabe erhalten, da jetzt eine Entität genau einen Bildschirm beschreibt und ein Bildschirm genau einem PC zugeordnet ist. Auf Seiten der PCs erhält sie ebenfalls 1,1, da ja ein PC genau einen Bildschirm hat (vgl. die Gesamtgrafik am Schluss).
Die Beziehung PC_F zwischen PC und Festplatten wird sinnvollerweise mit FP-Einzeln und nicht mit FP-Typ hergestellt. Dann ist die Zuordnung ganz klar und ma weiß, welche Festplatten in welchem PC integriert sind und wieviele Festplatten ein PC hat.
Ungenauigkeit
Die Beziehung DVD-PC zwischen DVD-LW und PC wie folgt: Der Entitätstyp DVD-LW modelliert auf Typebene. Damit ist die Min-/Max-Angabe bei den Laufwerken 1,n (da DVD-Laufwerke des gleichen Typs in mehreren PCs sein können) und bei den PCs 0,1 (da nicht jeder PC ein DVD – Laufwerk hat).
Die Beziehung zwischen PCs und Nutzern ist wiederum im spezifizierenden Text festgelegt: „Es kommt vor, wenn auch nicht oft, dass ein PC von mehreren Mitarbeitern genutzt wird.“ Damit ergibt sich bei PC die Angabe 1,n. Durch Nachfrage haben wir herausbekommen, dass umgekehrt ein Nutzer ebenfalls mehrere PCs nutzen kann. Damit ergibt sich dort ebenfalls die Min-/Max - Angabe 1,n.
Eine weitere Nachfrage ergab, dass man Nutzer und PC datenbanktechnisch auch schon anlegen möchte, wenn noch keine Zuordnung PC/Nutzer erfolgt ist. Deshalb wurde der jeweilige Minimumwert auf 0 geändert.
0,n statt 1,n
11.6.4 Das gesamte ER-Modell
Die folgende Abbildung zeigt das Datenmodell im Zusammenhang.
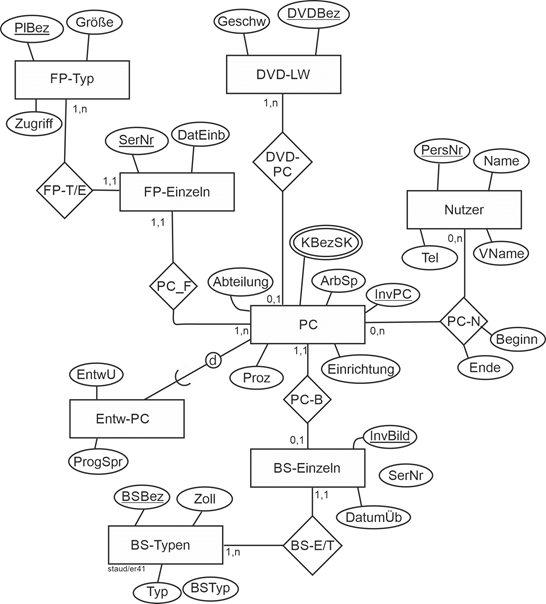
Abbildung 11.6-8: |
Anwendungsbereich PC-Nutzung - Gesamtmodell |
![]()
11.7 Sprachenverlag
Zu diesem Beispiel gibt es: Aufgabenstellung + Lösungsweg
Besonderes Lernziel dieses Beispiels ist, das Muster Generalisierung / Spezialisierung (GenSpez) ausführlich vorzustellen.
11.7.1 Der Anwendungsbereich
Es geht um die Produkte eines Verlages, der Wörterbücher (z.B. Deutsch / Englisch), digital oder auch gedruckt, herstellt und verkauft und der seit einiger Zeit auch Übersetzungsprogramme anbietet. Seine Produkte sollen in einer Datenbank verwaltet werden. Einige Attribute sind schon angeführt. Zu erfassen ist folgendes:
- Alle Wörterbücher und Volltextübersetzer (vgl. unten) mit den Sprachen, die abgedeckt sind (z.B. Deutsch nach Englisch und Englisch nach Deutsch, Deutsch nach Französisch und Französisch nach Deutsch), …). Es ist grundsätzlich möglich, dass ein Wörterbuch auch nur eine Richtung abdeckt.
- Für jedes gedruckte Wörterbuch wird auch festgehalten, wie viele Einträge es hat (Einträge), für welche Zielgruppe es gedacht ist (Schüler, Studierende, „Anwender“, „Profi-Anwender“, Übersetzer) (Zielgruppe), wann es auf den Markt gebracht wurde (ErschDatum) und wie viele Seiten es hat (AnzSeiten).
- Für jedes digitale Wörterbuch wird auch festgehalten, wann es auf den Markt gebracht wurde (ErschDatum), welche Bezeichnung (SWBez) die aktuelle Software hat (z.B. Professional English 7.0), wie viele Einträge es hat (Einträge) und für welche Zielgruppe es gedacht ist (Schüler, Studierende, „Anwender“, „Profi-Anwender“, Übersetzer) (Zielgruppe).
- Für jeden „Volltextübersetzer“ (Programm zur automatischen Übersetzung) wird auch festgehalten, welche Sprachen abgedeckt sind, wie viele Einträge das Systemlexikon hat (Einträge), für welche Zielgruppe das Produkt gedacht ist und wann es auf den Markt gebracht wurde (ErschDatum). Festgehalten wird ob man den Käufern anbietet, es durch Internetzugriffe regelmäßig aktualisieren zu lassen. Falls ja, wie lange dies möglich ist (AktJahre), z.B. 5 Jahre ab Kauf.
- Die Volltextübersetzer beruhen jeweils auf einem Übersetzungsprogramm (SWBez). Es kann sein, dass ein Volltextübersetzer mit verschiedenen Programmen angeboten wird (z.B. Zielgruppenspezifisch). Natürlich dient ein Programm u.U. vielen Volltextübersetzern (z.B. Deutsch nach Englisch, Französisch nach Deutsch). Für diese Programme wird festgehalten, welche Dokumentarten (DokArt) sie auswerten können (Word, PDF, Bildformate, usw.) und ob es möglich ist, die Programmleistung in Textprogramme zu integrieren (IBK; Integrierbarkeit).
- Die Programme für die digitalen Wörterbücher werden nicht erfasst.
- Für die Programme der Volltextübersetzer werden außerdem die Softwarehäuser, die an der Erstellung mitgearbeitet haben, mit ihrer Anschrift (nur die Zentrale) festgehalten. Es wird auch die zentrale E-Mail-Adresse erfasst. Ein Programm stammt von einem einzigen Softwarehaus.
- Festgehalten wird auch, wann die Zusammenarbeit mit dem Softwarehaus bzgl. eines Programmes begann (Beginn) und – gegebenenfalls – wann sie endete (Ende). Diese Angaben sind natürlich i.d.R. je nach Produkt, bei dem zusammengearbeitet wurde, unterschiedlich.
- Für alle digitalen Produkte (Wörterbücher/Systemlexikon usw. + Programme) werden außerdem die Systemvoraussetzungen festgehalten. Welche minimale Hardwareanforderung (Hardware) gegeben ist (anhand des Prozessors), wieviel Arbeitsspeicher sie benötigen (ArbSpeich), wieviel freier Plattenspeicher (PlattSpeich) nötig ist (in MB) und welche Betriebssystemversion (BS) genutzt werden kann. Dies sind in der Regel mehrere.
- Für alle Produkte des Verlags werden die Bezeichnung (Bez), der Typ (Wörterbuch, Übersetzungsprogramm, …) sowie der Listenpreis (LPreis) erfasst.
11.7.2 Lösungsschritte
Hier wird nun obiger Text Schritt für Schritt bearbeitet und das Datenmodell erarbeitet.
Abschnitt 1
- Alle Wörterbücher und Volltextübersetzer (vgl. unten) mit den Sprachen, die abgedeckt sind (z.B. Deutsch nach Englisch und Englisch nach Deutsch, Deutsch nach Französisch und Französisch nach Deutsch), …). Es ist grundsätzlich möglich, dass ein Wörterbuch auch nur eine Richtung abdeckt.
Hier sind zwei Tatsachen ableitbar. Erstens, dass es wohl Wörterbücher und Volltextübersetzer als solche gibt – und zwar wahrscheinlich als „Spitze“ einer Generalisierungshierarchie. Nennen wir sie Produkte und geben ihnen den Schlüssel ProdNr. Zweites, dass die abgedeckten Sprachen zu erfassen sind, und zwar als mehrwertige Attribute an diesem Entitätstyp:
Mehrwertiges Attribut Sprachen
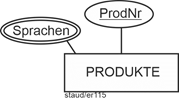
Abbildung 11.7-1: |
Entitätstyp Produkte - Version 1 |
Sprachen: mehrwertiges Attribut
Nächste Abschnitte
- Für jedes gedruckte Wörterbuch wird auch festgehalten, wie viele Einträge es hat (Einträge), für welche Zielgruppe es gedacht ist (Schüler, Studierende, „Anwender“, „Profi-Anwender“, Übersetzer) (Zielgruppe), wann es auf den Markt gebracht wurde (ErschDatum) und wie viele Seiten es hat (AnzSeiten).
Hier wird eine erste Spezialisierung deutlich: Gedruckte Wörterbücher. Sie werden WöBüBuch genannt und haben (erstmal) die oben angeführten Attribute.
- Für jedes digitale Wörterbuch wird auch festgehalten, wann es auf den Markt gebracht wurde (ErschDatum), welche Bezeichnung (SWBez) die aktuelle Software hat (z.B. Professional English 7.0), wie viele Einträge es hat (Einträge) und für welche Zielgruppe es gedacht ist (Schüler, Studierende, „Anwender“, „Profi-Anwender“, Übersetzer) (Zielgruppe).
Damit ist die zweite Spezialisierung klar: digitale Wörterbücher. Dieser Entitätstyp wird WöBüDigital genannt. Da hier zum Teil dieselben Attribute wie in WöBüBuch auftauchen, gibt es also Attribute, die der Generalisierung zuzuordnen sind: Einträge, ErschDatum und Zielgruppe. Konkret ergibt sich damit insgesamt aus obigem das folgende ER-Modell-Fragment:
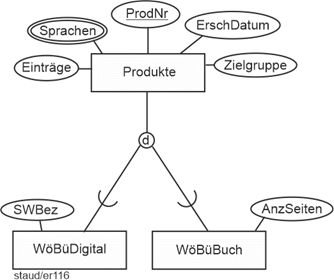
Es kann vermutet werden, dass die Generalisierung / Spezialisierung noch weitergeführt wird, deshalb legen wir eine Tabelle mit den zugehörigen Entitätstypen und Attributen an.
Attributtabelle: Produkte und ihre Spezialisierungen - 1
| Alle Produkte |
Gedruckte Wörterbücher (WöBüBuch) |
Digitale Wörterbücher (WöBüDigital) |
|---|---|---|
| Sprachen |
Sprachen |
Sprachen |
| Einträge |
Einträge |
Einträge |
| Zielgruppe |
Zielgruppe |
Zielgruppe |
| ErschDatum |
ErschDatum |
ErschDatum |
|
|
AnzSeiten |
|
|
|
|
SWBez |
So die erste Fassung der Matrix – noch völlig ungeordnet.
- Für jeden „Volltextübersetzer“ (Programm zur automatischen Übersetzung) wird auch festgehalten, welche Sprachen abgedeckt sind, wie viele Einträge das Systemlexikon hat (Einträge), für welche Zielgruppe das Produkt gedacht ist und wann es auf den Markt gebracht wurde (ErschDatum). Festgehalten wird ob man den Käufern anbietet, es durch Internetzugriffe regelmäßig aktualisieren zu lassen. Falls ja, wie lange dies möglich ist (AktJahre), z.B. 5 Jahre ab Kauf.
Dies zeigt eine weitere Spezialisierung, die Volltextübersetzer. Ergänzen wir damit unsere Attributtabelle:
Attributtabelle: Produkte und ihre Spezialisierungen – 2
| Alle Produkte |
Gedruckte Wörterbücher (WöBüBuch) |
Digitale Wörterbücher (WöBüDigital) |
Volltextübersetzer (VTÜ) |
|---|---|---|---|
| Sprachen |
Sprachen |
Sprachen |
Sprachen |
| Einträge |
Einträge |
Einträge |
Einträge |
| Zielgruppe |
Zielgruppe |
Zielgruppe |
Zielgruppe |
| ErschDatum |
ErschDatum |
ErschDatum |
ErschDatum |
|
|
AnzSeiten |
|
|
|
|
|
SWBez |
|
|
|
|
|
AktJahre |
Das Attribut AktJahre legen wir ganz pragmatisch so an: Bei fehlender Aktualisierungsmöglichkeit wird ein sog. Null Value eingetragen, ansonsten die Zahl der Jahre.
Pragmatik
Eine ganz korrekte Lösung bestünde darin, für die VTÜ mit Aktualisierungsmöglichkeit einen eigenen Entitätstyp anzulegen und dort das Attribut AktJahre hinzuzufügen. Dieser Entitätstyp wäre dann eine Spezialisierung von Volltextübersetzer.
Bereinigen wir nun noch die Tabelle, indem wir die oberste Generalisierung mit all den Attributen ausstatten, die in allen untergeordneten Spezialisierungen vorkommen und alle Attribute in Spezialisierungen streichen, die in übergeordneten Generalisierungen vorkommen, ergibt sich folgende Tabelle:
Attributtabelle: Produkte und ihre Spezialisierungen – 3
| Alle Produkte |
Gedruckte Wörterbücher (WöBüBuch) |
Digitale Wörterbücher (WöBüDigital) |
Volltextübersetzer (VTÜ) |
|---|---|---|---|
| Sprachen |
|
|
|
| Einträge |
|
|
|
| Zielgruppe |
|
|
|
| ErschDatum |
|
|
|
|
|
AnzSeiten |
|
|
|
|
|
SWBez |
|
|
|
|
|
AktJahre |
Damit wird folgende Generalisierung / Spezialisierung deutlich:
Die Zahl der Einträge, die Sprachen, die Zielgruppe und das Erscheinungsdatum (ErschDatum) erfassen wir weiterhin bei Produkte (weil alle Spezialisierungen diese Attribute aufweisen), das Attribut SWBez bei WöBüDigital, das Attribut AnzSeiten bei WöBüBuch und das Attribut AktJahre bei Volltextübersetzer.
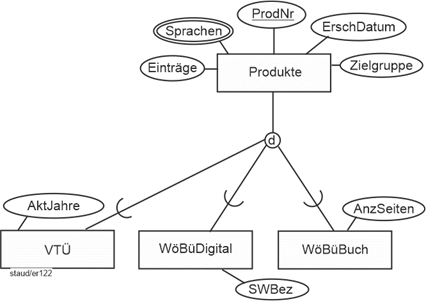
Abbildung 11.7-2: |
Generalisierung / Spezialisierung rund um Produkte |
Nächster Abschnitt
- Die Volltextübersetzer beruhen jeweils auf einem Übersetzungsprogramm (SWBezVTÜ). Es kann sein, dass ein Volltextübersetzer mit verschiedenen Programmen angeboten wird (z.B. zielgruppenspezifisch). Natürlich dient ein Programm u.U. vielen Volltextübersetzern (z.B. Deutsch nach Englisch, Französisch nach Deutsch). Für diese Programme wird festgehalten, welche Dokumentarten (DokArt) sie auswerten können (Word, PDF, Bildformate, usw.) und ob es möglich ist, die Programmleistung in Textprogramme zu integrieren (IBK; Integrierbarkeit).
Hier werden nun die Übersetzungsprogramme zu einem Datenbankobjekt. Da gleich auch noch Attribute für die Programme angegeben werden, muss für sie tatsächlich ein Entitätstyp angelegt werden.
Attribut zu Entitätstyp
Programme können mehrere Dokumentarten auswerten, deshalb ist das Attribut DokArt mehrwertig:
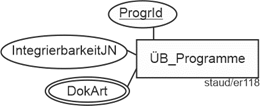
Abbildung 11.7-3: |
Entitätstyp Üb_Programme |
Es wird auch gleich die Beziehung zwischen Übersetzungsprogrammen und den Volltextübersetzern geklärt. Für diese muss ein eigener Beziehungstyp VÜ_P eingerichtet werden.
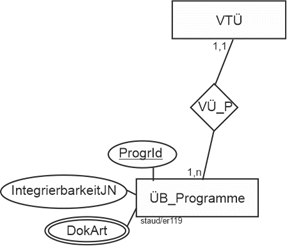
Abbildung 11.7-4: |
Beziehungstyp VÜ_P |
Da ein Übersetzungsprogramm vielen Volltextübersetzern dienen kann, umgekehrt aber ein bestimmter Volltextübersetzer nur ein Übersetzungsprogramm hat, sind die Min-/Max-Angaben wie folgt:
- 1:1 beim Entitätstyp VTÜ
- 1:n beim Entitätstyp ÜB_Programme
Nächste Abschnitte
- Die Programme für die digitalen Wörterbücher werden nicht erfasst.
- Für die Programme der Volltextübersetzer werden außerdem die Softwarehäuser, die an der Erstellung mitgearbeitet haben, mit ihrer Anschrift (nur die Zentrale) festgehalten. Es wird auch die zentrale E-Mail-Adresse erfasst. Es kommt durchaus vor, dass ein Programm von mehreren Softwarehäusern erstellt wird.
- Festgehalten wird auch, wann die Zusammenarbeit mit dem Softwarehaus bzgl. eines Programmes begann (Beginn) und – gegebenenfalls – wann sie endete (Ende). Diese Angaben sind natürlich i.d.R. je nach Produkt, bei dem zusammengearbeitet wurde, unterschiedlich.
Der erste Abschnitt stellt klar, dass die Programme für die digitalen Wörterbücher lediglich als Attribut und nicht als eigener Entitätstyp erfasst werden sollen.
Der zweite Abschnitt führt die Softwarehäuser als Datenbankobjekte ein, hier also als Entitätstyp. Erfasst wird eine einzige Anschrift sowie die zentrale Mail-Adresse. Der folgende Satz gibt den Hinweis, dass zwischen Programmen und Softwarehäusern eine n:m-Beziehung vorliegt, wenn man davon ausgeht, dass ein Softwarehaus im Zeitverlauf auch an mehreren Programmen des Verlags mitgearbeitet hat. Zusammen mit dem Hinweis auf die zu erfassenden Start- und Endtermine im dritten Abschnitt ergibt sich folgendes Modellfragment:
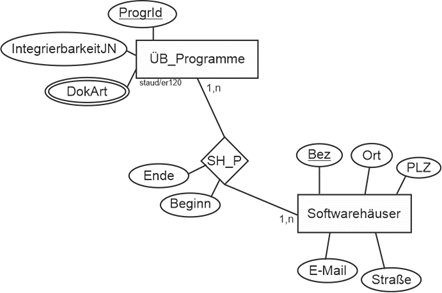
Attribute auf Beziehungstyp
Abbildung 11.7-5: |
Beziehung zwischen Übersetzungsprogrammen und Softwarehäusern |
Nächster Abschnitt
- Für alle digitalen Produkte (Wörterbücher/Systemlexikon usw. + Programme) werden außerdem die Systemvoraussetzungen festgehalten. Welche minimale Hardwareanforderung (Hardware) gegeben ist (anhand des Prozessors), wieviel Arbeitsspeicher sie benötigen (ArbSpeich), wieviel freier Plattenspeicher (PlattSpeich) nötig ist (in MB) und welche Betriebssystemversion (BS) genutzt werden kann. Dies sind in der Regel mehrere.
Obiger Punkt führt über die Festlegung der Systemanforderungen neue Attribute für alle digitalen Produkte ein. Ergänzen wir zur Klärung dieses Sachverhalts die Attributtabelle um diese Attribute:
Attributtabelle: Produkte und ihre Spezialisierungen - 4
| Alle Produkte |
WöBüBuch |
WöBüDigital |
VTÜ |
|---|---|---|---|
| Sprachen / mehrwertig |
|
|
|
| Einträge |
|
|
|
| Zielgruppe |
|
|
|
| ErschDatum |
|
|
|
|
|
AnzSeiten |
|
|
|
|
|
SWBez |
|
|
|
|
|
Erweiterbarkeit |
|
|
|
Hardware |
Hardware |
|
|
|
ArbSpeich |
ArbSpeich |
|
|
|
PlattSpeich |
PlattSpeich |
|
|
|
BS |
BS |
Damit ergibt sich, dass WöBüDigital und VTÜ einige Attribute gemeinsam haben. Dies führt dazu, dass eine weitere Spezialisierung von Produkte angelegt wird, die in der Spezialisierungshierarchie zwischen Produkte und WöBüDigital / VTÜ liegt. Sie soll ProdukteDig genannt werden.
Weitere Spezialisierung
Ergänzen wir obige Attribute in der Attributtabelle und streichen die Attribute der Generalisierung in ihren Spezialisierungen ergibt sich die folgende Attributtabelle.
Attributtabelle: Produkte und ihre Spezialisierungen - 5
| Alle Produkte |
WöBüBuch |
ProdukteDig |
WöBüDigital |
VTÜ |
|---|---|---|---|---|
| Sprachen / mehrwertig |
|
|
|
|
| Einträge |
|
|
|
|
| Zielgruppe |
|
|
|
|
| ErschDatum |
|
|
|
|
|
|
AnzSeiten |
|
|
|
|
|
|
|
SWBez |
|
|
|
|
|
|
Erweiterbarkeit |
|
|
|
Hardware |
|
|
|
|
|
ArbSpeich |
|
|
|
|
|
PlattSpeich |
|
|
|
|
|
BS / mehrwertig |
|
|
Damit wird dann eine neue Generalisierungs- / Spezialisierungsstruktur deutlich. Der Entitätstyp ProdukteDig wird als Generalisierung der digitalen Wörterbücher und der Volltextübersetzer eingebaut.
Dies ist ein Beispiel dafür, wie durch die Generalisierung / Spezialisierung die Attribute des Datenmodells und später der Datenbank effizient angelegt werden.
Die Information zu den Betriebssystemversionen wird als mehrwertiges Attribut von ProdukteDig angelegt. Damit ergibt sich folgendes Modellfragment:
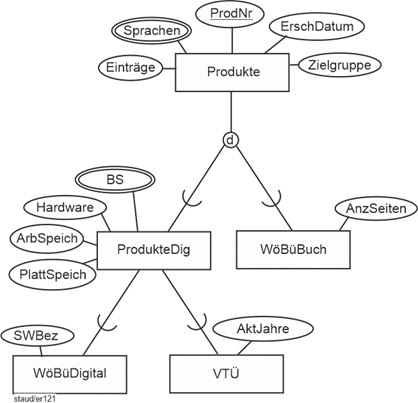
Abbildung 11.7-6: |
Generalisierung / Spezialisierung rund um Produkte - Endfassung |
Wie hier gerade zu sehen war, kann durch weitere Modellinformationen eine bestehende Generalisierung / Spezialisierung verändert werden. Dies kommt nicht selten vor.
Was die obigen Attributtabellen vielleicht auch deutlich gemacht haben ist, dass für die Bewältigung komplexer Generalisierungs- / Spezialisierungsstrukturen diese Tabellen ein hilfreiches Werkzeug sind.
Letzter Abschnitt
- Für alle Produkte des Verlags werden die Bezeichnung (Bez), der Typ (Wörterbuch, Übersetzungsprogramm, …) sowie der Listenpreis (LPreis) erfasst.
Mit diesen Attributen vervollständigen wir den Entitätstyp Produkte.
11.7.3 Das gesamte ER-Modell
Fügt man die einzelnen Modellfragmente zusammen, ergibt sich das folgende Entity Relationship - Modell für den Anwendungsbereich Sprachenverlag.
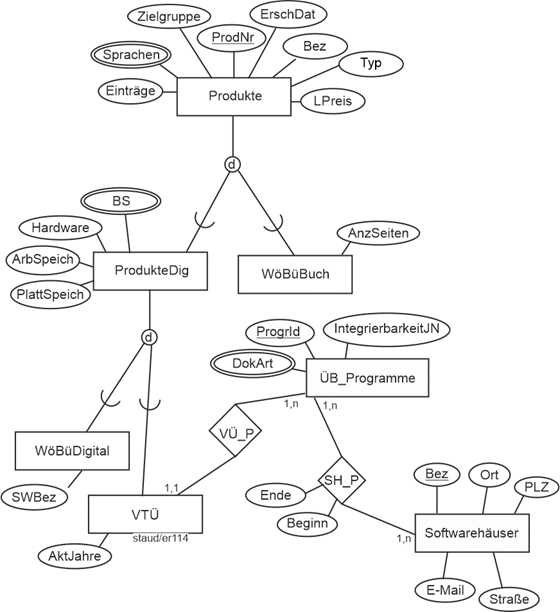
Abbildung 11.7-7: |
ER-Modell Sprachenverlag - Endfassung |
![]()
11.8 Hochschule – Vorlesungsbetrieb
Zu diesem Beispiel gibt es die Aufgabenstellung und den Lösungsweg
Anwendungsbereich Vorlesungsbetrieb einer Hochschule. Folgendes soll erfasst werden:
- Besuch von Vorlesungen durch Studierende
- Besuch von Prüfungen durch Studierende
- Durchführung von Lehrveranstaltungen durch Dozenten
Folgendes soll erfasst werden:
- Die Lehrveranstaltungen (LV) als solche mit ihrer Bezeichnung (BezLV) und der Angabe des Semesters, indem sie nach Studienplan stattfinden (SemPlan). Außerdem soll festgehalten werden, in welchem Studiengang (BezSG) sie stattfinden (Bachelor WI, Bachelor AI, Master WI, usw.) und von welchem Typ sie sind (Typ; Vorlesung, Übung, Projekt).
- Die Prüfungen, die Studierende besuchen. Dabei soll die Art der Prüfung (ArtPrüfung), die zugehörige Lehrveranstaltung (BezVeranst), die Bezeichnung des Studienganges (BezStudiengang) und die erzielte Note erfasst werden. Für Klausuren außerdem die Voraussetzungen, um den wievielten Versuch es sich handelt (Versuch) und die Länge. Für mündliche Prüfungen ebenfalls die Länge und wieviele Prüfer anwesend sein müssen (ZahlPrüfer). Für jeden Besuch einer Prüfung wird festgehalten, in welchem Semester er erfolgte und welche Note erzielt wurde.
- Die Dozenten mit Name, Vorname, E-Mail , Telefonnummer (Tel) und Typ (intern / extern). Für die internen Dozenten werden die Sprechstunden (Sprechst) erfasst, für die externen die private und. geschäftliche Telefonnummer, die Organisation, in der sie tätig sind (Org) und die Adresse (PLZ, Ort, Straße)
- Die konkreten Termine einer jeden Lehrveranstaltung mit Tag, Beginn, Ende, Raum, Semester (die Redundanz, die in der gleichzeitigen Erfassung von Tag und Semester liegt, wird akzeptiert).
- Die Studierenden mit Matrikelnummer (MatrNr), Namen (Name), Vornamen (Vorname), Mail-Account (E-Mail) und ihren Adressen (Heimatadresse, Adresse am Studienort, usw.) mit PLZ, Ort und Straße.
- Welcher Dozent welche Lehrveranstaltung grundsätzlich zu halten bereit (und fähig) ist und welcher Dozent welche Lehrveranstaltung ganz konkret gehalten hat.
- Welche konkreten Termine bei jeder Lehrveranstaltung realisiert werden und wer sie durchführt. Es ist durchaus möglich, dass sich mehrere Dozenten die Veranstaltungstermine einer Lehrveranstaltung aufteilen.
- Der Besuch der einzelnen Veranstaltungstermine durch die Studierenden. An dieser Hochschule ist es üblich, die Anwesenheit zu kontrollieren. Deshalb wird für jeden Veranstaltungstermin einer LV festgehalten, welche Studierenden anwesend waren.
11.8.1 Entitätstypen
Als Entitäten und Entitätstypen sofort erkennbar sind die Lehrveranstaltungen (LV). Sie werden identifiziert und beschrieben.
Die Attribute sind angegeben, wir ergänzen lediglich einen numerischen Schlüssel (LVNr), da mit ihm in der Datenbankpraxis besser umzugehen ist.
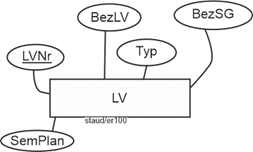
Abbildung 11.8-1: |
Beispiel Hochschule - Lehrveranstaltungen (LV) |
Nun die Prüfungen, die im zweiten Spiegelstrich angefordert werden. Es wird ausgeführt, dass es sich um die konkreten einzelnen Prüfungen handelt, nicht um die abstrakten Prüfungen des Studienplanes.
Prüfungen
Hier muss erkannt werden, dass eine Generalisierung / Spezialisierung vorliegt. Die Generalisierung wird Prüf_Allg genannt. Die Spezialisierungen sind Klausuren (Prüf_Kl) mit den spezifischen Attributen Versuch und Voraussetzung und mündliche Prüfungen (Prüf_MP) mit ZahlPrüfer.
Auch hier wurde wieder ein numerischer Schlüssel ergänzt (PrüfNr). Damit ergibt sich das folgende Modellfragment.
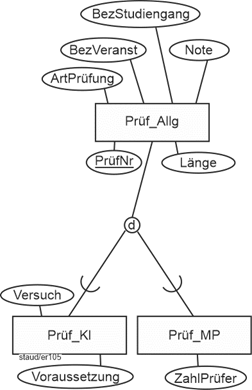
Abbildung 11.8-2: |
ER-Modell Hochschule - Prüfungen |
Auch beim Entitätstyp der Dozenten, muss erkannt werden, dass die Attribute in eine Generalisierung / Spezialisierung hinein aufgelöst werden müssen. Es gibt Attribute, die für alle Dozenten Gültigkeit haben (der Entitätstyp wird Doz_Allg genannt) und weitere, die nur auf externe Dozenten (Doz_Extern) und interne Dozenten (Doz_Intern) anwendbar sind. Mit einem hinzugefügten numerischen Schlüssel (DozNr) ergibt sich folgende Aufteilung:
Gen/Spez bei Dozenten
- Doz_Allg erhält DozNr, Name, Vorname, E-Mail und Telefon. Da wir in der Anforderung sehen, dass für die externen Dozenten die private und die geschäftliche Telefonnummer erfasst werden sollen, legen wir dieses Attribut als mehrwertiges an.
- Doz_Intern erhält das Attribut Sprechst.
- Doz_Extern erhält die Attribute PLZ, Ort, Straße und Org.
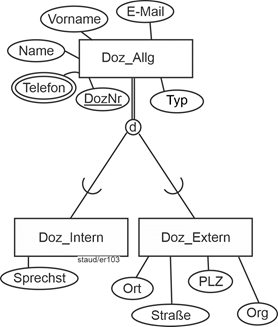
Abbildung 11.8-3: |
ER-Modell Hochschule - Dozenten |
Als nächstes werden in der Anforderungsliste Studierende genannt. Sie gibt es ganz sicher als Entitätstyp („Identifizierung + Beschreibung“) mit den Attributen MatrNr, Name, Vorname und E-Mail.
Studierende
Da die Erfassung mehrerer Adressen angefordert wird, wird ein eigener Entitätstyp notwendig (Adressen). Er erhält die Attribute PLZ, Ort und Straße. Wir ergänzen wieder einen Schlüssel: AdressNr.
Adressen
Nun die Beziehung. Die Min-/Max-Angabe bei Studierende ist sicher 1,n. Doch was ist mit der Min-/Max-Angabe bei Adressen? Eigentlich 1,1. Allerdings ist es so, dass verschiedene Studierende auch dieselbe Adresse haben können (Wohnheim, Hochhaus, usw.). Damit wird die Min-/Max-Angabe bei Adressen auch 1,n. Der dabei entstehende Beziehungstyp wird StudAdr genannt.
Oft wird an dieser Stelle gefragt, ob man hier nicht als Min-Angabe jeweils 0 nehmen kann. Ja, das kann man. Man lässt dann zu, dass es Einträge in die Datenbank gibt für Studierende (noch) ohne Adresse und Adressen ohne Studierende.
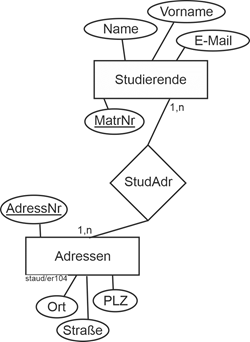
Abbildung 11.8-4: |
ER-Modell Hochschule - Studierende mit ihren Adressen |
Im nächsten Punkt werden die Dozenten angesprochen. Erfasst werden soll, welche Lehrveranstaltung (LV) ein Dozent grundsätzlich zu halten bereit ist. Eine notwendige Information für die Planung der Lehre. Dies kann durch einen Beziehungstyp Lehrfähigkeit zwischen LV und Doz_Allg gelöst werden. Für die konkret gehaltenen Lehrveranstaltungen legen wir einen Beziehungstyp Lehrtätigkeit an. Er muss mit Attributen versehen werden: Semester (SS, WS) und Jahr (in dem das Semester beginnt. Auf Nachfrage erfahren wir, dass hin und wieder Veranstaltungen geteilt und mehrfach gehalten werden müssen, u.U. vom selben Dozenten. Deshalb ergänzen wir noch das Attribut Nr. Die Wertigkeit dieser Beziehungen wird unten betrachtet.
Dozenten und Lehre
Abbildung 11.8-5: |
ER-Modell Hochschule - Lehrfähigkeit und Lehrtätigkeit |
Als nächstes wird in der Anforderungsliste gefordert, zu erfassen, welche Termine bei jeder Lehrveranstaltung (LV) konkret durchgeführt werden. Dazu müssen wir einen Entitätstyp Veranstaltungstermine anlegen. Hier muss man erkennen, dass die einzelnen Termine existenzabhängig sind von ihren Lehrveranstaltungen. Ohne Lehrveranstaltung keine Termine, bzw., wenn dann später eine LV aus der Datenbank gelöscht wird, müssen auch die zugehörigen Termine gelöscht werden. Es handelt sich also um einen singulären Entitätstyp. Die Attribute legen wir wie folgt fest: Semester, Tag, Beginn, Ende, Raum. Damit sind die einzelnen Termine eindeutig festgelegt. Für den Schlüssel genügt Tag, Beginn, Raum, da dies bereits eindeutig ist. In der Praxis wird hier oft ein Schüssel generiert, z.B. VTerminId („20211200800M220“), wir belassen es hier beim zusammengesetzten Schlüssel.
Dozenten und LV-Termine
Die Beziehung besteht ja zum Entitätstyp LV, der Beziehungstyp wird deshalb LVT genannt (siehe Abbildung). Um die weitere Beziehung und um die Wertigkeiten kümmern wir uns unten, im „Beziehungsteil“.
Redundanz im Datenmodell?
Das Attribut Semester könnte auch aus den Datumsangaben und dem Wissen, wann das Semester beginnt und endet berechnet werden. Dann müßte aber der Anfang und das Ende der Semester in den einzelnen Jahren auch in der Datenbank hinterlegt werden und jede Abfrage hätte dies zu berücksichtigen. Hier wird deshalb der einfachere Wege gewählt, die Semesterangabe bei den Terminen zu hinterlegen, auch wenn dadurch Redundanz entsteht.
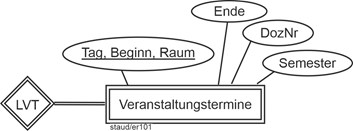
Abbildung 11.8-6: |
ER-Modell Hochschule - Veranstaltungstermine |
11.8.2 Beziehungstypen
In der folgenden Abbildung sind die obigen Fragmente zusammengefügt und die jetzt betrachteten Beziehungen vermerkt.
Nachdem die Entitätstypen modelliert sind, können jetzt die noch nicht modellierten Beziehungen betrachtet werden.
Wie sehen die Min-/Max-Angaben bei der Beziehung
LVT
LV – LVT – Veranstaltungstermine
aus? Auf der Seite des singulären Entitätstyps 1,1, denn ein Termin gehört zu genau einer Lehrveranstaltung. Beim Entitätstyp LV ergibt sich 1,n, da eine Lehrveranstaltung mindestens einen Termin hat, i.d.R. aber mehrere.
In der Anforderungsliste ist auch gefordert, dass festgehalten wird, welcher Dozent ganz konkret welchen Veranstaltungstermin wahrnimmt. Der Beziehungstyp wird DVT (Dozenten – Veranstaltungstermine) genannt. Damit geht es um folgende Beziehung:
DVT
Doz_Allg – DVT – Veranstaltungstermine
Es ist hier wohl so, dass die Termine einer Lehrveranstaltung auch zwischen mehreren Dozenten aufgeteilt werden können. Damit ergeben sich folgende Min-/Max-Angaben:
- 1,n bei Doz_Allg.
- 1,x bei Veranstaltungstermine. x hängt von den Gepflogenheiten der Hochschule ab. Wieviele Dozenten dürfen maximal einen Veranstaltungstermin wahrnehmen. Normalerweise ist x gleich 2. Somit ergibt sich als Min-/Max-Angabe 1,2.
Nun die Beziehung
Lehrfähigkeit
LV – Lehrfähigkeit – Doz_Allg
Typischerweise gilt: Ein Dozent kann eine oder mehrere Lehrveranstaltungen halten. „Eine“ z.B. im Fall von externen Lehrbeauftragten, „mehrere“ bei Hauptamtlichen, denn dafür wurden sie berufen.
Umgekehrt gilt, dass eine Lehrveranstaltung normalweise von mindestens einem Dozenten gehalten werden kann. Da wir aber später auch neue Lehrveranstaltungen in der Datenbank anlegen wollen, für die wir u.U. nicht gleich einen Dozenten haben, wählen wir hier als Min-Angabe 0. Insgesamt also 0,n.
Für die Beziehung
Lehrtätigkeit
LV – Lehrtätigkeit – Doz_Allg
gilt: Ein Dozent hält in einem Semester keine (Praxissemester), eine oder mehrere Lehrveranstaltungen und eine Lehrveranstaltung wird von mindestens einem oder auch mehreren Dozenten gehalten. Daraus folgen 1,n bei LV und 0,m bei Doz_Allg.
Werfen wir einen Blick auf die später entstehende Datenbank:
Dadurch, dass die Lehrtätigkeit zum einen über die Lehrveranstaltung als Ganzes und zum anderen über die einzelnen Veranstaltungstermine erfasst wird, ergibt sich Redundanz. Aus dem Halten der Termine könnte die Lehrtätigkeit abgeleitet werden. Ganz pragmatisch, um die späteren SQL-Abfragen nicht zu verkomplizieren, wird hier die Lösung über den Beziehungstyp Lehrtätigkeit gewählt.
Möglich wäre hier auch, die Lehrtätigkeit nicht eingeben, sondern aus DVT berechnen zu lassen. Dann wäre ein abgeleitetes Attribut nötig.
Bei VTBesuch geht es um den Besuch der einzelnen Veranstaltungstermine durch Studierende (Veranstaltungsterminbesuch; VTBesuch). Der Beziehungstyp muss zwischen Veranstaltungstermine und Studierende eingefügt werden:
VTBesuch
Veranstaltungstermine – VTBesuch – Studierende
Die Min-/Max-Angaben ergeben sich wie folgt: x,n bei Studierende. „x“ steht für die Mindestanzahl von Terminen, die besucht werden müssen. Bei einer dem Verfasser bekannten Hochschule darf man von 13 Semesterwochen höchstens drei fehlen. Also wäre hier x gleich 10, die Wertigkeit also 10,13. Dies hängt aber von der Prüfungsordnung der Hochschule ab.
Für jeden Veranstaltungstermin gilt, dass mindestens 3 Studierende anwesend sein müssen, woraus sich 3,n ergibt.
Die nächste Beziehung betrifft den Prüfungsbesuch. Der Beziehungstyp PrüfBesuch wird zwischen Studierende und Prüf_Allg eingefügt:
PrüfBesuch
Studierende – PrüfBesuch – Prüf_Allg.
Er erhält das Attribut Semester, durch das festgehalten wird, in welchem Semester der Besuch der Prüfung erfolgte und ein Attribut (erzielte) Note.
Die Wertigkeiten sind wie folgt: Ein Studierender besucht keine, eine oder mehrere Prüfungen pro Semester (0,n). Eine Prüfung wird von mindestens einem Studierenden besucht (1,m).
11.8.3 Gesamtmodell
Hier nun das Gesamtmodell einschließlich aller Beziehungen.
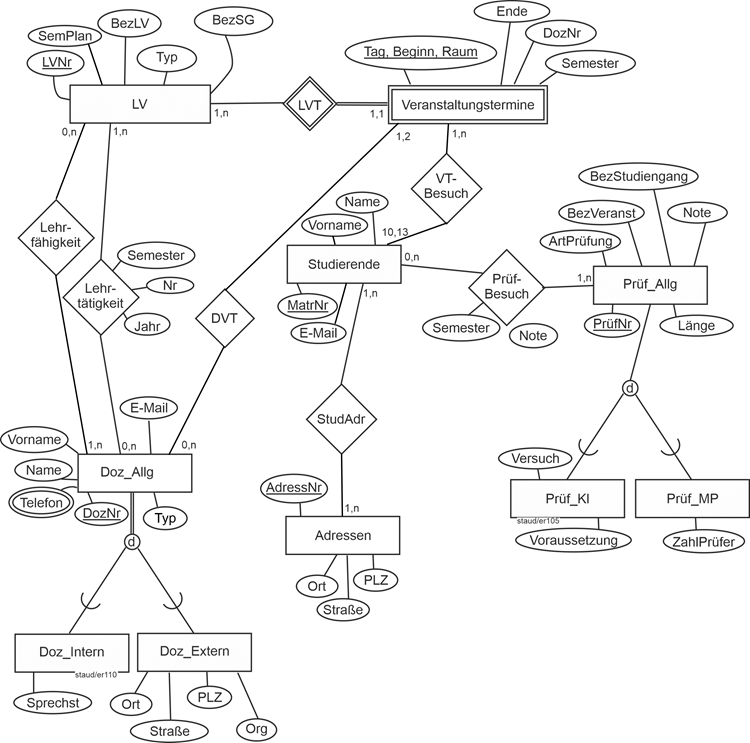
Abbildung 11.8-7: |
ER-Modell Hochschule |
![]()