1.1 Grundstruktur
Jede Modellierungstechnik für Datenbanken bildet Aspekte des zu modellierenden Anwendungsbereichs in ein Modell ab. In ein semantisches, logisches, objektorientiertes, usw. Die Technik der Entity Relationship - Modelle (ER-Modelle) gehört zu denen, die im Anwendungsbereich Objekte und Beziehungen zwischen diesen mit Hilfe von Attributen identifizieren und beschreiben.
Für die Objekte wird bei dieser Methode auch in deutschen Texten der Begriff Entity (Entität), für Beziehungen der Begriff Relationship (Beziehung) gewählt.
Wie bei diesen Methoden üblich werden die einzelnen Entitäten und Beziehungen klassifiziert. Alle mit derselben Attributausstattung werden zu Typen zusammengefasst, wodurch Entitätstypen und Beziehungstypen entstehen. Aus diesen sind ER-Modelle aufgebaut.
1.2 Mehr Semantik ins Datenmodell
Entity Relationship - Modelle (ER-Modelle) sind Semantische Datenmodelle. Das Hauptziel bei deren Entwicklung war, mehr von der Semantik eines Anwendungsbereichs zu erfassen als in älteren oder näher an den Dateistrukturen befindlichen Modellierungsansätzen, weshalb die ganze Gruppe dieser datenbanktheoretischen Modellierungsansätze so genannt wird.
Vgl. zum Begriff Semantik den nächsten Absatz
Semantische Datenmodelle wurden vor allem in den 1970er Jahren entwickelt. Dies führte zu einer großen Zahl von Vorschlägen, von denen nur einer dauerhaft Bedeutung für die Datenbankpraxis erlangt hat, die Entity Relationship - Modellierung.
Sie entstanden als Antwort auf die semantische Armut relationaler Datenmodelle. Die relationale Datenmodellierung ist im Kern reduziert auf attributbasierte Tabellen, die bestimmte Bedingungen erfüllen (sie werden dann Relationen genannt) und auf Verknüpfungen dieser Relationen durch Schlüssel/Fremdschlüssel. Vgl. [Staud 2021, Kapitel 5] für eine umfassende Einführung. Diese semantische Armut sollte durch die semantische Modellierung überwunden werden.
Entstehung
Zu dem Mehr an Semantik gehört die grundsätzliche Unterscheidung von Entitäten und Beziehungen, die in der relationalen Theorie durch ein gemeinsames Konzept (Relationen) erfasst werden. Außerdem die Erfassung zahlreicher semantischer Muster im Anwendungsbereich, z.B. Ähnlichkeit (Generalisierung / Spezialisierung), Enthaltensein (part_of, Teil_von), Existenzabhängigkeit (singuläre Entitätstypen), usw., die im übrigen danach auch in der objektorientierten Datenbanktechnologie Verwendung fanden.
Mehr Semantik
Abgrenzungen sollte man v.a. in zweierlei Hinsicht machen. Erstens zur objektorientierten Datenmodellierung. Die Modellierungstechnik ist hier eine ähnliche, wenn auch mit anderer Begrifflichkeit, z.B. Klasse statt Typ. V.a. aber kommen bei der objektorientierten Modellierung, sei es für Datenbanken oder Systeme, die sog. Methoden mit dazu. Damit werden die statischen Aspekte des Anwendungsbereichs, die durch Datenbanken erfasst werden, durch dynamische ergänzt. Für eine umfassende Einführung in die objektorientierte Modellierung mit der UML 2.5 vgl. [Staud 2019].
Abgrenzungen
Die zweite Abgrenzung ist gegenüber den Datenbanken und ihren Modellierungstechniken notwendig, die nicht auf dem Attributsbegriff basieren. Diese gibt es schon sehr lange unter unterschiedlichen Bezeichnungen. Heute wird diese Thematik größtenteils unter der Bezeichnung NoSQL-Datenbanken behandelt. Vgl. für einen Überblick [Staud 2021, Kapitel 24].
1.3 Syntax, Semantik, Pragmatik
Was genau ist mit dem bei dieser Modellierungstechnik eine große Rolle spielenden Begriff Semantik gemeint?
Die im Datenbankkontext verwalteten Informationen werden i.d.R. durch Daten ausgedrückt, weshalb wir von diesem Begriff ausgehen.
Solche Daten haben einen bestimmten Aufbau (Syntax), eine Bedeutung (Semantik) und dienen einem Zweck (Pragmatik):
- Semantik meint hier im Datenbankkontext die Bedeutung, den Bedeutungsgehalt der Informationen, die über den Anwendungsbereich gewonnen wurden.
- Den korrekten Aufbau legt die sog. Syntax fest, die dafür die Regeln vorgibt.
- Mit Pragmatik ist der zielgerichtete Zweck gemeint, durch den Daten zu einer (eindeutig interpretierbaren) Information werden.
Betrachten wir einige Beispiele, zuerst Datumsangaben. Diese haben eine schlichte Struktur. Sie bestehen aus einer Tages-, einer Monats- und einer Jahresangabe. Z.B. könnte die Syntax folgenden Aufbau vorschreiben: 4. Mai 2021 oder auch 2021/05/04. Also z.B. dass die Tagesangabe aus einer maximal zweistelligen positiven Zahl besteht, die Monatsangabe ebenfalls (oder aus einer Zeichenfolge) und die Jahresangabe entweder ebenfalls als zweistellige oder als vierstellige positive Zahl erfasst wird. Damit legt die Syntax den korrekten Aufbau dieser Information schon etwas fest, würde aber auch den 31. April 2024 oder den 35. 12. 2022 zulassen.
Datumsangaben: Tag, Monat, Jahr
Dies unterbindet die Semantik, die zur weiteren Festlegung der Datumsangaben führt:
- Tagesangaben liegen nur zwischen 1 und 31
- Monatsangaben nur zwischen 1 und 12
- Die Monate April, Juni, September, November haben maximal 30 Tage
- Der Monat Februar hat maximal 28 Tage mit Ausnahme der Schaltjahre
- Das Jahr 2004 ist ein Schaltjahr, der Februar hat also 29 Tage
- Das Jahr 2000 war ebenfalls ein Schaltjahr (die Schaltjahrregelungen sind recht kompliziert, so gibt es Schaltjahre, die nur in großem Abstand auftreten).
usw.
Solche Festlegungen stellen also die Semantik der Datumsangaben dar. Genauer formuliert ist es so, dass die Realwelt (Datumsangaben) eine Semantik hat, die durch die Datumsangaben im Datenbestand möglichst genau erfasst werden soll. Dem Datenbanksystem liefert damit die Semantik weitere Regeln für die Korrektheit der Information. Dabei spricht man auch von Semantischen Integritätsbedingungen (englisch: constraints) .
Semantik von Datumsangaben
Noch präziser wird die Information durch die Pragmatik beschrieben. Eine Datumsangabe kann zum Beispiel einen Auftragseingang, ein Zahlungsziel oder den Abgabetermin für die Bachelorarbeit bedeuten. Das weiß die jeweilige Nutzerin und richtet ihr Verhalten daran aus.
Betrachten wir ein weiteres Beispiel. Die Ausprägung einer Information sei die Zahl "19". Ein solches Datenelement kann verschiedene Bedeutungen haben:
Beispiel
Zahl 19
- eine Hausnummer
- eine Uhrzeit
- ein Kalendertag
- die Nummer einer Buslinie
Die Semantik wird erst durch den Zusammenhang klar:
- Steht 19 neben der Eingangstür an einer Hauswand, weiß man: Es ist die "Hausnummer 19".
- Steht 19:00 auf einer digitalen Armbanduhr, so weiß man: Es ist "7 Uhr abends".
- Steht 19 auf der Anzeige vorne in der S-Bahn, so weiß man: Es ist "die Linie 19".
In einer Hochschule könnten folgende Grundsätze unserer Daseins zur Semantik gehören und bei der Gestaltung einer Datenbank zum Lehrbetrieb wichtig sein:
Beispiel
Lehrbetrieb
- In einem Raum kann in einer Zeitspanne nur eine Veranstaltung stattfinden.
- Ein Dozent kann in einer Zeitspanne nur einen Kurs abhalten.
- Ein Dozent sollte pro Tag nicht mehr als 6 Stunden Vorlesungen und Übungen geben.
- Veranstaltungen, die das lokale PC-Netz zum Absturz bringen könnten (z.B. Programmierkurse) sollten nicht am Freitag Nachmittag stattfinden, da ab 13.00 Uhr die Rechenzentrumsmitarbeiter nicht mehr da sind, um einen evtl. Netzzusammenbruch "zu reparieren".
usw. Wenigstens ein kleiner Teil solcher Semantikaspekte kann in Datenmodellen erfasst werden. Allerdings wirklich nur ein kleiner, wie im Folgenden zu sehen sein wird, weshalb die diesbezüglichen Anstrengungen weitergehen.
Woher kommt der Wunsch, möglichst viel Semantik des jeweiligen Weltausschnitts in einem Datenmodell und dann in der Datenbank zu erfassen? Nun, die Semantik gehört zur Anwendung. Sie muss auf jeden Fall berücksichtigt werden, soll die Anwendung leistungsstark sein. Entweder wird sie in der Datenbank hinterlegt oder in den Programmen softwaretechnisch realisiert (dann ist sie Gegenstand der Systemanalyse).
Mehr Semantik in das Datenmodell
Es geht natürlich nur um den Teil der Semantik, der für die jeweilige Anwendung bzw. für die Geschäftsprozesse, denen die Datenbank "dient", Bedeutung hat.
Die Hinterlegung in der Datenbank, aufbauend auf der vorangehenden Berücksichtigung beim Datenbankentwurf, hat aber Vorteile: Sie ist sehr übersichtlich (z.B. als Semantische Integritätsbedingungen (constraints) auf den Relationen) und leicht änderbar. Man kann es auch so formulieren: Alle (zu berücksichtigende) Semantik, die nicht in der Datenbank hinterlegt wird, muss bei der Systemanalyse für die Anwendungsprogramme berücksichtigt werden.
Fehlt noch die Pragmatik von Daten bzw. Informationen. Daten, die eine Bedeutung haben, sind immer noch keine (eindeutige) Information. Dazu fehlt der praktische Wert, den eine Angabe für den Empfänger der Information bekommt. Eine Datumsangabe zum Beispiel kann einen Auftragseingang, ein Zahlungsziel oder den Abgabetermin für die Bachelorarbeit bedeuten. Das weiß der jeweilige Nutzer. Daten und ihre Bedeutung müssen also über einen zielgerichteten, pragmatischen Zweck verfügen, um zu einer (eindeutig interpretierbaren) Information zu werden. Diesen Aspekt von Daten nennt man auch Pragmatik.
Pragmatik
1.4 Thematische Einordnung
In diesem Text geht es um die aktuell bedeutsamen Ausprägungen der semantischen Datenmodellierung: ERM, S-ERM und SAP-SERM. Die Einbettung dieser Thematik in das Datenbankgeschehen kann anhand der folgenden Abbildung geklärt werden. Sie stammt aus [Staud 2021, S. 17] und zeigt den Gesamtweg eines Datenbankprojekts, von der Analyse des Anwendungsbereichs bis zu den Dateien der Datenbank.
Inhalt und Einbettung
Alles beginnt mit einem Anwendungsbereich, für den eine Datenbank zu erstellen ist. Sie ist in der Abbildung ganz oben als Wolke dargestellt (Position 1). Die Auseinandersetzung mit dem Anwendungsbereich, das Gewinnen der für die Datenbank wichtigen Informationen, wird konzeptionelle Modellierung (conceptual modeling) genannt. Mit ihrer Hilfe werden Objekte und Objektklassen (im umgangssprachlichen Sinn, nicht im Sinn der objektorientierten Theorie) erkannt, Attribute gefunden und zugeordnet sowie Beziehungen geklärt.
Konzeptionelle Modellierung
Die konzeptionelle Modellierung führt zu einem semantischen Datenmodell (Position 2). Mit einem solchen ist es möglich, Objekte, Beziehungen und Attribute unabhängig von einem konkreten Datenbanksystem und seinen Datenbanktechniken zu beschreiben. Von den vielen, die in den letzten Jahrzehnten hierfür vorgeschlagen wurden, blieb nur das sog. Entity Relationship - Modell (ER-Modell) übrig. Seine Aufgabe ist eine erste mit viel Aussagekraft erstellte Modellierung. Oder auch eine für Überblicksnotationen.
Semantische Datenmodelle
Genau hier ist dieser Text angesiedelt, wobei der Schwerpunkt auf dem klassischen ER-Ansatz nach Chen liegt, ergänzt um den Vorschlag von Sinz, ER-Modelle zu strukturieren (vgl. Kapitel 12) und die davon abgeleitete Variante der SAP (SAP-SERM; vgl. Kapitel 13).
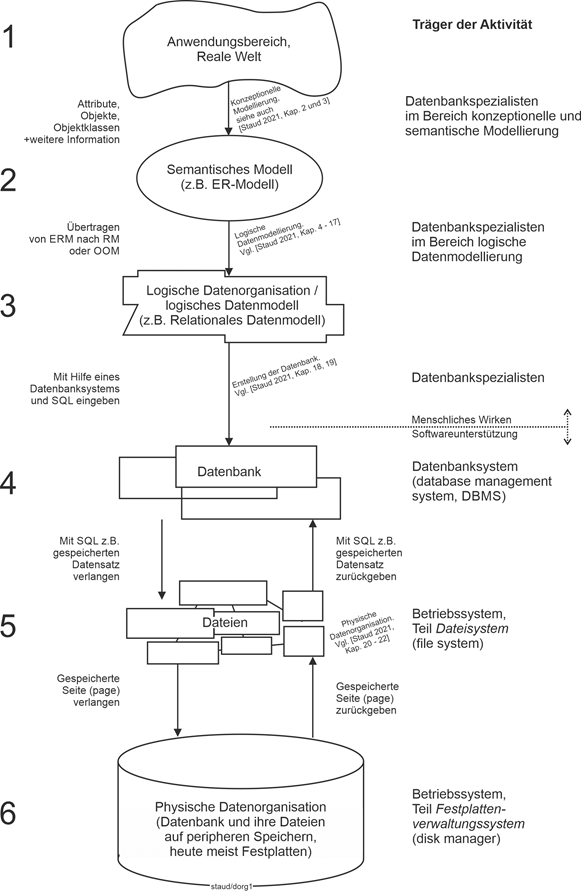
Abbildung 1.4-1: |
Der Weg vom Anwendungsbereich zur Datenbank und ihren Dateien. Quelle: [Staud 2021, S. 17]. |
Dass damit ein zwar wichtiger Schritt zur Datenbank geleistet wird, einige weitere aber noch fehlen, zeigt der Rest der Abbildung, der hier nur des Überblicks wegen skizziert werden soll.
Im nächsten Schritt (Position 3) entsteht ein logisches Datenmodell. Damit werden Modelle bezeichnet, die einer bestimmten Datenbanktheorie und damit einem bestimmten Datenbanksystemtyp entsprechen. Dies sind heutzutage i.w. relationale und objektorientierte Datenbanksysteme und weitere, die neueren Ansätzen zur Datenverwaltung entsprechen (vgl. Kapitel 23 in [Staud 2021]).
Logisches Datenmodell
Vgl. [Staud 2021] für eine umfassende Einführung in die relationale Theorie und [Staud 2019] für eine umfassende Darstellung der objektorientierten Theorie mit Blick auf Unternehmensmodellierung.
Mit der Erstellung des logischen Datenmodells ist die Struktur der künftigen Datenbank festgelegt. Also ein relationales Datenmodell oder auch ein objektorientiertes. Für diese Datenmodelle gibt es Datenbanksysteme, die mehr oder weniger gut das jeweilige Datenmodell (die jeweilige Theorie) unterstützen und seine Umsetzung erlauben.
Datenbankdesign vollzogen
Nun gilt es, aufbauend auf dem logischen Datenmodell, die konkrete Datenbank mit einem geeigneten Datenbanksystem einzurichten (Position 4). Dabei entstehen viele Dateien auf dem peripheren Speicher (heute meist Festplatten), in denen die Daten und die Verwaltungsinformation abgelegt sind (Position 5) .
Auf der rechten Seite der folgenden Abbildung ist angegeben, wer die jeweilige Aktivität umsetzt. Von 1 nach 2 ist Kompetenz in den Bereichen konzeptionelle und semantische Modellierung nötig. Hier ist dieser Text angesiedelt. Geht es weiter nach 3, ist Kompetenz in logischer Datenmodellierung gefragt, heute also v.a. in relationaler oder in objektorientierter Modellierung.
Träger der jeweiligen Aktivität
Die nächsten Schritte bis zum physischen Speichermedium werden dann durch Anwendungssysteme realisiert. Durch das Datenbanksystem(database management system; DBMS; hier DBS) und das Betriebsssystem. Letzteres v.a. durch die in der Abbildung angeführten Komponenten Dateisystem (file system) und Festplattenverwaltungssystem (disk manager).
Datenbanksystem – Betriebssystem
1.5 Typographische Festlegung
Um im Text die Übersichtlichkeit zu erhöhen, wird folgende typographische Festlegung getroffen:
- Bezeichnungen von Anwendungsbereichen werden in normaler Größe, in Kapitälchen und in Arial gesetzt: Hochschule, Personalwesen, WebShop. In der Web-Version dieses Textes sind sie zusätzlich in roter Farbe gehalten.
- Bezeichnungen von Datenmodellen und Datenbanken sind fett in normaler Größe und in Arial gesetzt: Vertrieb, Zoo, WebShop, Datenbanksysteme (Markt für Datenbanksysteme). In der Web-Version zusätzlich in rot.
- Bezeichnungen von Entitäts- und Beziehungstypen sind etwas verkleinert und in Arial gesetzt: Angestellte, Abteilungen, Projekte. In der Web-Version zusätzlich in rot.
- Bezeichnungen von Attributen sind etwas verkleinert, fett und in Arial gesetzt: Gehalt, Name, Datum. Bei zusammengesetzten Benennungen wird der nachfolgende Begriff wieder groß begonnen: PersNr (Personalnummer), BezProj (Bezeichnung Projekt).
- Attributsausprägungen werden in normaler Größe und in Courier gesetzt.
![]()